内容大纲:
一、开发环境准备
1. IDE开发工具选择及安装
2. Java SDK版本选择及安装
3. Spark开发语言 版本选择及安装
4. 下载Spark的安装程序
5. 安装Maven
6. 安装sbt
7. IDE的插件选择、安装及配置
二、从零开始创建第一个Spark程序 - HelloSpark
1. 创建Scala工程
2. 添加Spark依赖的jar包
3. 修改工程pom文件,并更新依赖包
4. 编写Spark程序代码
5. 在IDE中编译并本地测试HelloSpark程序
6. 编译jar包,并部署到Spark集群运行
三、从github获取工程,并快速搭建Spark开发环境
1. 从github中clone工程
2. 修改代码,编译测试及打包
3. 部署到Spark集群
四、使用IDE及Github实现版本控制
1. 建立github账号
2. 下载github并安装
3. intellij idea配置github
4. intellij idea检出github项目
5. 修改代码,编译及测试代码
6. 上传项目到GitHub
一、开发环境准备
IDE开发工具选择及安装
主流的IDE开发环境有Scala-IDE(Eclipse)及IntelliJ IDEA两种,开发者可以根据自己的喜好选择。本演示所有的实验是基于IntelliJ IDEA完成。
两种工具下载地址分别如下:
· Scala-IDE (目前最新版4.4.1,Eclipse Luna 4.4.2)
http://scala-ide.org/download/sdk.html 下载适合自己系统的版本
· IntelliJ IDE (目前最新版2016.1)
https://www.jetbrains.com/idea/download/ 有社区版和收费版两种。对于本演示来说,社区版足够
选择、下载并安装JDK
JDK可以选择1.7和1.8。由于Oracle官方已经停止了1.7版本的更新,建议使用JDK1.8版本。
JDK1.7 下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
JDK1.8下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载适合开发环境系统的版本。如本例中使用的是Mac OS X系统,所以下载Mac OS版本。
接下来安装JDK
配置Java运行环境变量

验证jdk安装成功
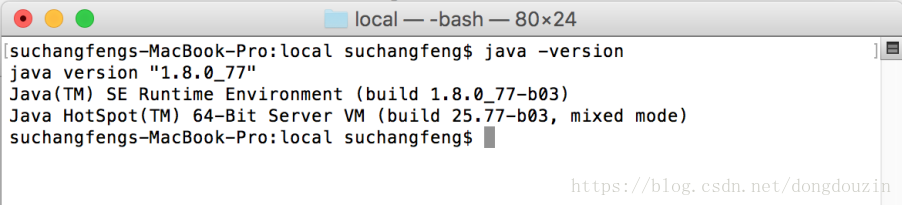
Spark开发语言Scala 的选择及安装
下载地址 http://www.scala-lang.org/download/ (目前最新版本是2.11.8)
本演示中使用的是2.10.6版本 (原因是Spark1.6版本使用的是scala2.10版本进行编译的,如果使用scala2.11版本,开发者需要自己基于scala2.11版本编译spark1.6的版本)。
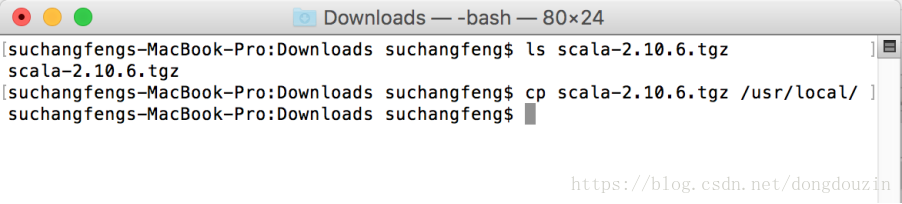
验证scala-2.10.6安装包下载成功
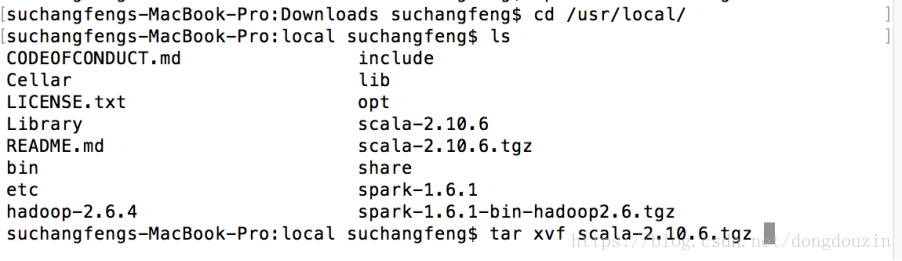
拷贝安装包到制定的目录,并解压缩
验证解压完成后,并修改环境变量,添加scala到path
添加SCALA_HOME,并添加Path
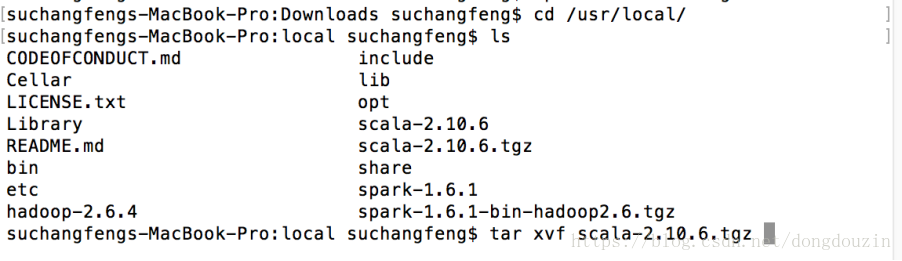
启动scala,确认能够正常启动scala命令行环境

下载Spark的安装程序
Apache Spark的下载地址:
http://spark.apache.org/downloads.html
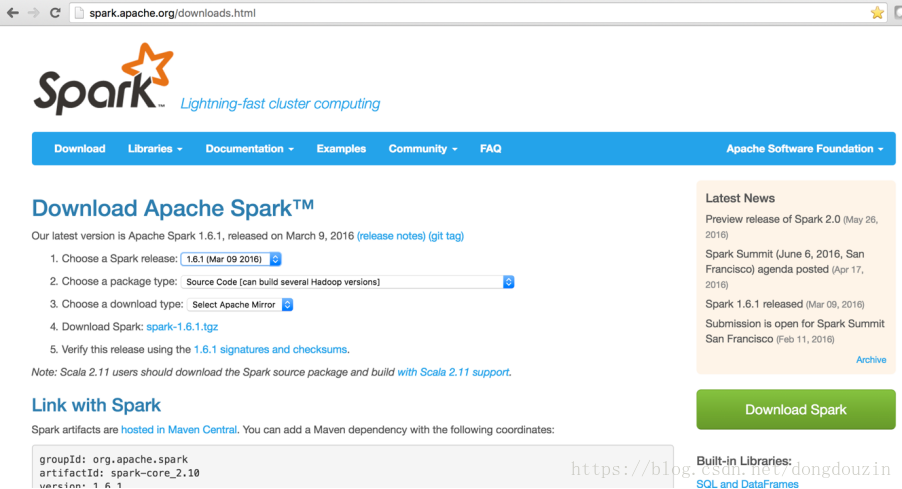

下载安装程序,并解压缩
安装Maven
最新版本下载地址:
http://apache.cs.utah.edu/maven/maven-3/3.3.9/
无需安装,解压即可。
安装SBT
最新版本下载地址:
https://dl.bintray.com/sbt/native-packages/sbt/0.13.9/
无需安装,解压即可。
1. 修改环境变量,配置MAVEN_HOME / SBT_HOME, 并加入path
source ~/.bash_profile
IDE的插件选择、安装及配置
启动IntelliJ IDE,点击“Configure”进入配置界面

在Search框中输入scala,在右边出现的插件中选择Scala的插件进行安装/更新。安装完成后,IDE要求重启。
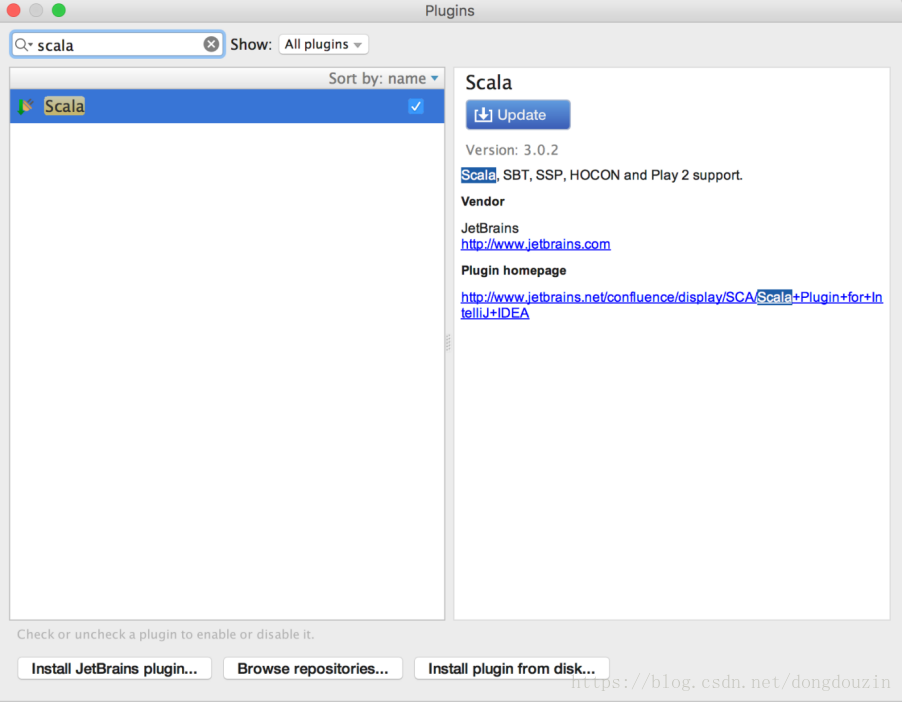
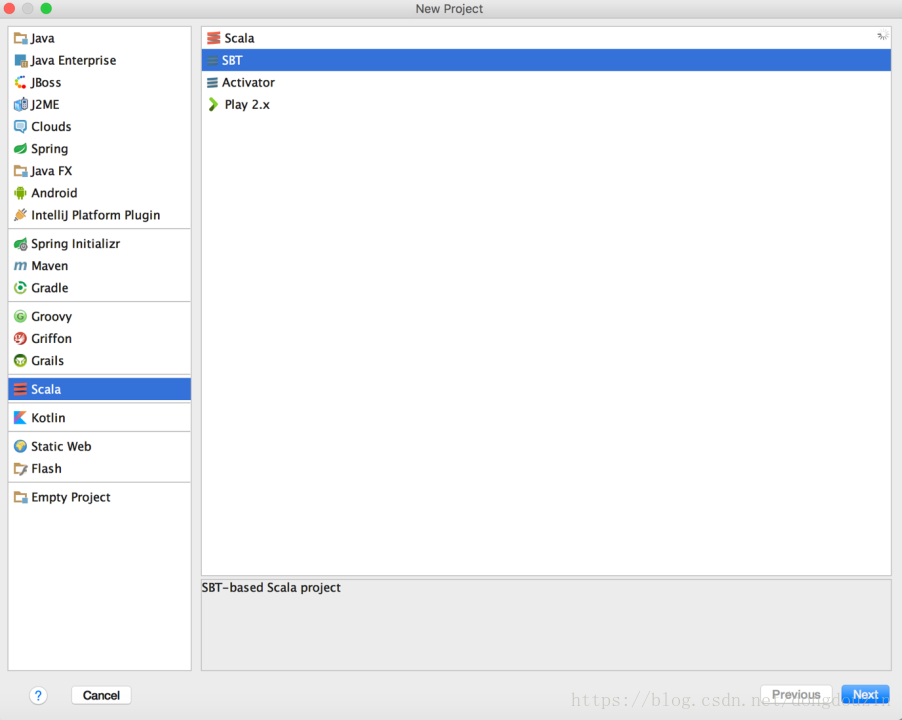
重启IDE后,选择“创建新工程”,选择Scala类型,并出现如下图的工程类型,则环境安装成功。
二、从零开始创建第一个Spark程序 - HelloSpark
创建Scala工程
“新建工程”

选择“Scala”类型
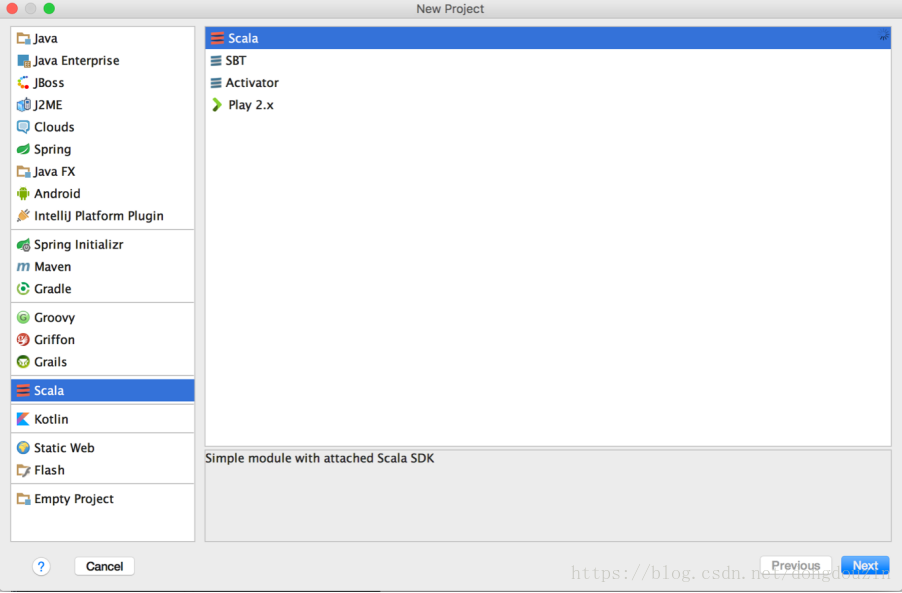
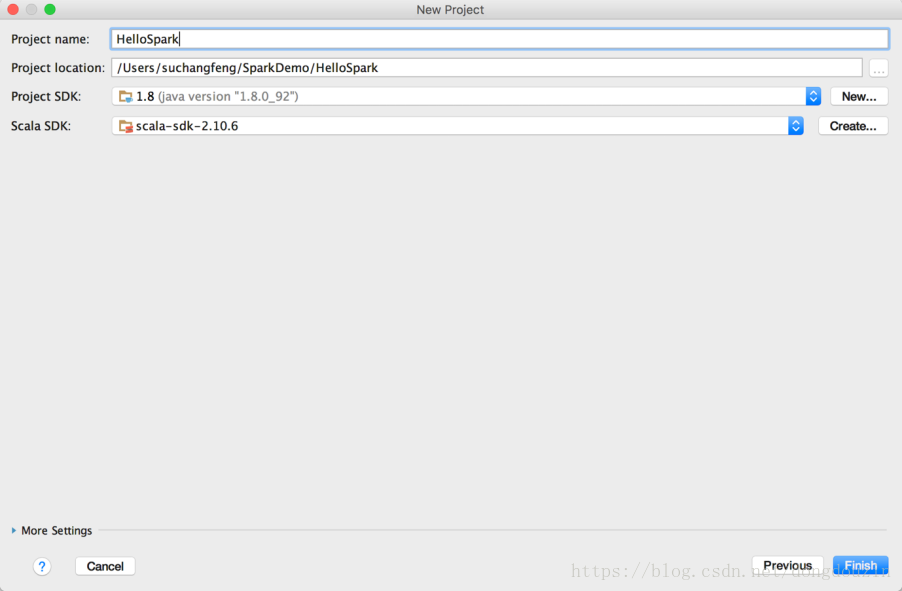
在工程名称中填入工程名称,如“HelloSpark”,并选择合适的工程路径,以及Java SDK及Scala SDK版本。这里,我选择了JDK最新版 1.8.0_92,SDK 2.10.6。然后点击完成。
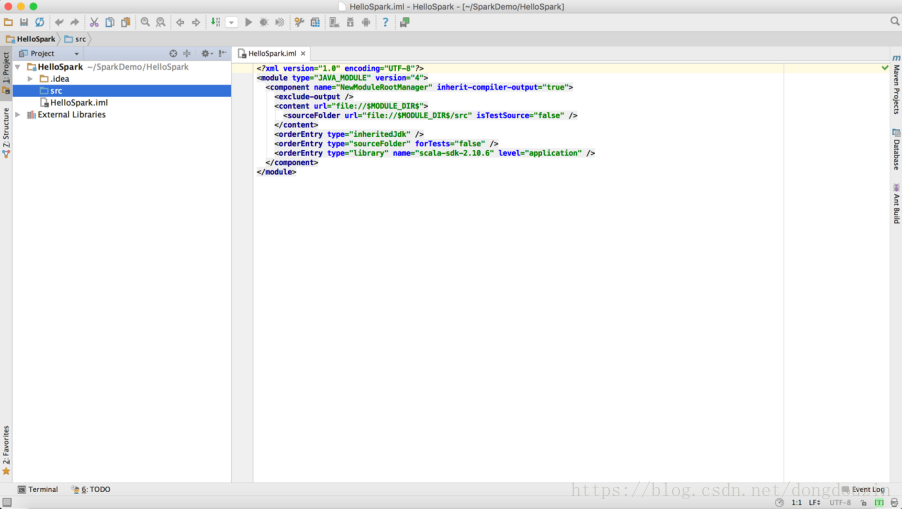
然后进入IDE开发界面。
添加Maven框架支持
右键选择工程名“HelloSpark”,然后“添加框架支持”
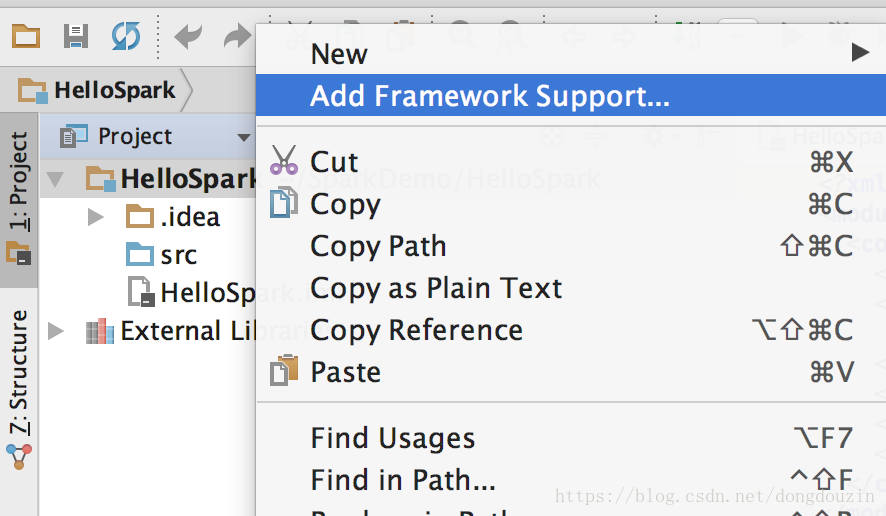
选择添加“Maven”支持
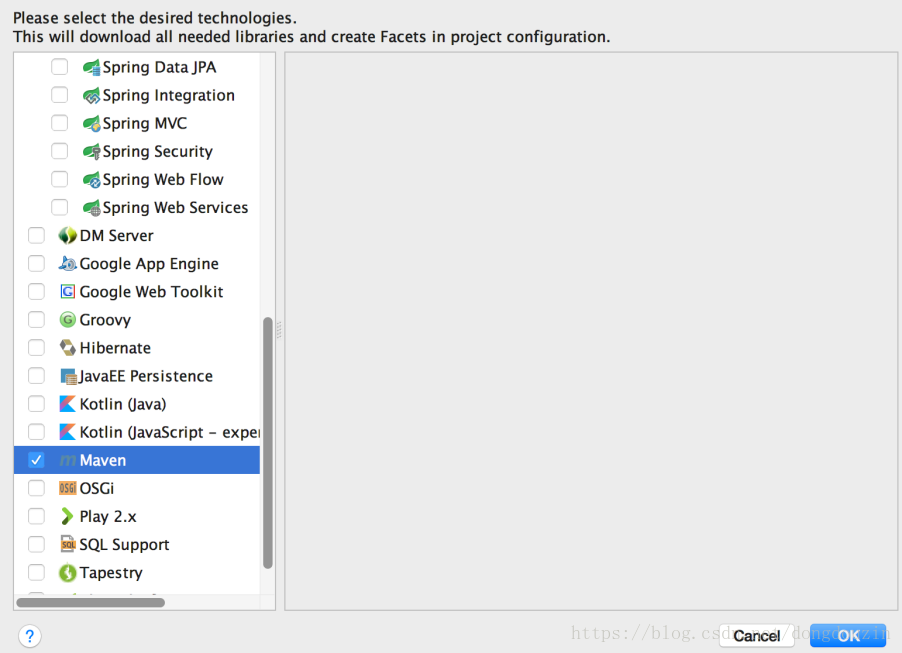
pom文件修改
添加后,工程会自动增加一个pom.xml文件,如下:
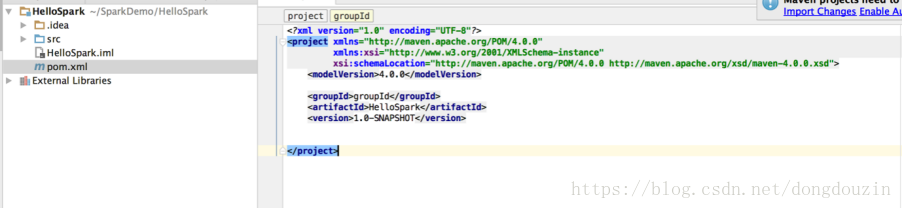
1. 修改工程pom文件,并更新依赖包
接下来,我们需要对pom文件进行修改,比如,增加repository,定义依赖等。
1) Haven Plugin
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
因为本次演示的实验主要是在CDH发行版上进行,所以选择1.6.0-cdh5.7.0的依赖。
2) Dependencies
<dependencies>
<!-- spark core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
<scope>provided</scope>
</dependency>
<!--spark MLib-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
<scope>provided</scope>
</dependency>
<!--spark sql-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
</dependency>
<!-- hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
</dependency>
<!-- spark streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
<scope>provided</scope>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.1</version>
<scope>provided</scope>
</dependency>
<!-- Scala language version -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.10.6</version>
</dependency>
</dependencies>
3) Repositories
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
<repository>
<id>maven-hadoop</id>
<name>Hadoop Releases</name>
<url>https://repository.cloudera.com/content/repositories/releases/</url>
</repository>
<repository>
<id>cloudera-repos</id>
<name>Cloudera Repos</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>Maven</id>
<url>http://repo1.maven.org/maven2</url>
</repository>
<repository>
<id>clojars</id>
<url>http://clojars.org/repo/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
4) 其它属性
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
修改完成后,右键选择pom.xml文件,并选择“验证”,IDE将帮你完成xml文件的语法验证工作。

更新依赖
验证通过后,我们就可以选择更新依赖。所有pom文件中被标注为红色的部分都是即将需要更新的内容。
有两种方法更新依赖。
1) 在IDE右上角,有提示信息,可以直接选择”Import Changes”

2) 或者,右键选择pom文件,àMavenàReimport

IDE右下角会有进度,提示当前依赖更新的状态。通常,根据需要更新的内容多少,以及网络的速度,时间或长或短。

完成后,所有pom文件中被标注为红色的内容将变成正常颜色,而External Libraries 中也会增加很多jar包
添加Spark依赖的jar包
我们在第一部分环境准备的时候已经下载并解压了Spark的安装程序。现在我们需要把相应的jar包加入到工程的依赖中来。
选择工程,“文件”à“工程结构”à“Libraries”

找到Spark的解压目录下的lib目录,并选择
spark-sssembly-1.6.1-hadoop2.6.0.jar
在弹出的窗口中选择确认

创建Spark程序源代码目录
首先,我们希望Java代码及Scala代码分开,因此我们需要在src/main目录下创建一个Scala的文件夹。
选择src/main文件夹,右键,然后选“新建”-“文件夹”

创建后的结构如下

接下来,我们需要把该文件夹加入到工程的结构中。
“文件”à“工程结构”

然后选择 “Modules”à“Sources”à”Sources”,并展开目录结构,找到新创建的“Scala”目录,你将会在最右边看到“src/main/Scala”。
点击确认返回。

编写Spark程序代码
在IDE中,选择新建的“Scala”目录,然后右键,选择“New”-“Scala Calss”

然后在弹出窗口中填入Scala Class的名称。本例中为HelloSpark,类型改为object,然后点击确定。
回到IDE编辑窗口,会得到一个新的Class,如下所示。

代码修改如下:
/**
* Created by suchangfeng on 6/2/16.
*/
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark._
object HelloSpark {
def main(args: Array[String]) {
// initialise spark context
val conf = new SparkConf().setAppName("HelloSpark-app")
val sc = new SparkContext(conf)
// do stuff
println("Hello, world!")
// terminate spark context
sc.stop()
}
}
在IDE中编译并本地测试HelloSpark程序
在IDE中,选择“Run”à“Edit Configurations”

然后在左边的树状结构中选择“Application”,然后点击左上角的“+”按钮,并在弹出窗口中选择“Application”。

添加“Application”后的窗口如下图所示,在“Name”、“Main Class”中分别填入“HelloSpark-app”、“HelloSpark”,并在“VM options”中指定Spark运行模式。在调试过程中,我们可以指定为local模式。
然后“确定”返回。

此时,IDE上方的“Run”按钮便成绿色。点击运行图标,测试我们的代码。
下方的通知栏会显示当前编译的状态。
下方的标准输出窗口将显示Spark运行的日志,并最终打印“Hello,Spark!”消息。
编译jar包,并部署到Spark集群运行
选择“File”à“Project Structure”,在弹出窗口中选择“Artifats”,并选择“+”添加
在新窗口中,选择“JAR”à“From modules with dependencies…”
在弹出窗口中,找到“HelloSpark”工程,并在Main Class中选择选择我们的“HelloSpark”Class。
同时,在输出目录中,选择jar文件的输出路径
最后选择“copy to the output and link via manifest”,避免把全部的依赖包都打到jar里面。
“确定”后得到如下界面 。
再在<output root>上右键,选择“Create Directory”,然后输入“lib”,“确定”返回。
在IDE编辑窗口,选择“Build”菜单,然后“Build Artifacts”
然后在弹出窗口选择“Build”
IntelliJ将开始编译,最下方状态条会显示当前编译状态。
编译完成后,工程结构中会自动增加一个“out”目录,并且可以在子文件夹中找到我们的HelloSpark.jar文件。
上传该jar文件到Spark集群服务器。
并且在另一个窗口中,执行(本实验环境Spark部署为Standalone模式)
最后可以看到,Application成果执行。