文章目录
前言
接着前两章 构建大数据开发知识体系图谱 和 大数据平台架构技术概览 ,本次继续分享邦中老师的《离线和实时大数据开发实战》读书笔记 。讲讲大数据开发的主战场 —— 离线数据开发。离线数据技术已经有了十多年的发展,已经 比较稳定,形成了 Hadoop、 MapReduce 和 Hive 为事实标准的离线数据处理技术,离线数据平台是整个数据平台的根本和基础,也是目前数据平台的主站场。
一、HDFS 和 MapReduce 优缺点分析
1.1 HDFS
HDFS 文全称是 Hadoop Distributed File System ,即 Hadoop 分布式文件系统,它是Hadoop 的核心子项目。实际上, Hadoop 中有一个综合性的文件系统抽象,它提供了文件系 现的各类接口,而 HDFS 只是这个抽象文件系统的一种实现,但 HDFS 是各种抽象接口实现中应用最为广泛和最广为人知的一个。
HDFS 是基于流式数据模式访问和处理超大文件的需求而开发的,其主要特点如下:
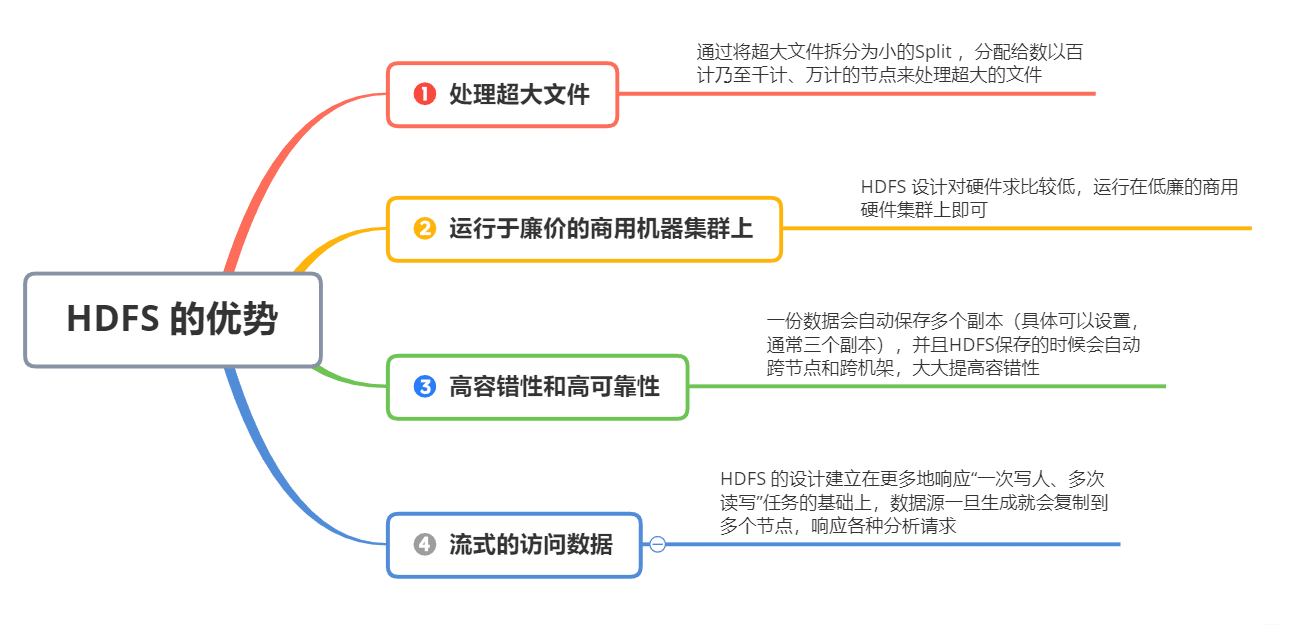
当然,HDFS 的上述种种特点非常适合于大数据量的批处理,但是对于一些特定问题不但没有优势, 而且有一定的局限性,主要表现在如下几个方面:
- 不适合低延迟数据访问
对于那些有低延时要求的应用程序, HBase 是一个更好的选择,尤其适用于对海量数据集进行访问并要求毫秒级响应时间的情况。
- 无法高效存储大量小文件
要想让 HDFS 处理好小文件,有不少方法。例如,利用 SequenceFile、MapFile、Har 等方式归档小文件。这个方法的原理就是把小文件归档起来管理, HBase 就是基于此的对于这种方法,如果想找回原来的小文件内容,就必须得知道与归档文件的映射关系。此外,也可以横向扩展,一个 NameNode不够,可以多 Master 设计,将NameNode 一个集群代替, Alibaba DFS 的设计,就是多 Master 设计,它把 Metadata 的映射存储和管理分开了,由多个 Metadata 存储节点和一个查询 Master 节点组成。
- 不支持多用户写入和随机文件修改
在 HDFS 的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作。
1.2 MapReduce
MapReduce 是 Google 公司的核心计算模型,它将运行于大规模集群上的复杂并行计算过程高度地抽象为两个函数: Map 和 Reduce。 Hadoop 中的 MapReduce 是一个使用简单的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并能可靠容错地并行处理 TB 级别的数据集。
MapReduce 目前非常流行,尤其在互联网公司中 MapReduce 之所以如此受欢迎,是因为它有如下的特点:

二、HDFS 和 MapReduce 基本架构
HDFS 和 MapReduce 是 Hadoop 的两大核心,它们的分工也非常明确, HDFS 负责分布式存储,而 MapReduce 负责分布式计算。
首先介绍 HDFS 的体系结构, HDFS 采用了主从( Master/Slave )的结构模型,一个HDFS 集群是由一个 NameNode 和若干个 DataNode 组成的,其中 NameNode 作为主服务器,管理文件系统的命名空间(即文件有几块,分别存储在哪个节点上等)和客户端对文件的访问操作;集群中的 DataNode 管理存储的数据。 HDFS 允许用户以文件的形式存储数据。
从内部来看,文件被分为若干数据块,而且这若干个数据块存放在一组 DataNode上。NameNode 执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体 DataNode 的映射 。DataNode 负责处理文件系统客户端的文件读写请求,并在 NameNode 的统一调度下进行数据块的创建、删除和复制工作。

NameNode 和 DataNode 都被设计成可以在普通商用计算机上运行,而且这些计算机通常运行的是 Linux操作系统 。HDFS 采用 Java 语言开发, 因此任何支持 Java 的机器都可以部署 NameNode 和 DataNode 。
一个典型的部署场景是集群中的一个机器运行一个NameNode 实例,其他机器分别运行一个 DataNode 实例。
MapReduce 也是采用 Master/Slave 的主从架构,其架构图如图:

MapReduce 包含4个组成部分,分别为 Client、 JobTracker、TaskTracker 和 Task。
三、MapReduce 内部原理实践
从上述 MapReduce 架构可以看出, MapReduce 作业执行主要由 JobTracker 和 Task-Tracker 负责完成。
-
客户端编写好的 MapReduce 程序井配置好的 MapReduce 作业是一个 Job, Job 被提交给 JobTracker ,JobTracker 会给该 Job 一个新的 ID 值,接着检查该 Job 指定的输出目录是否存在、输入文件是否存在, 如果不存在,则抛出错误。
-
同时, JobTracker 会根据输入文件计算输入分片 ( input split ),这些都检查通过后, JobTracker 就会配置 Job 需要的资源并分配资源,然后 JobTracker 就会初始化作业,也就是将 Job 放入一个内部的队列,让配置好的作业调度器能调度到这个作业,作业调度器会初始化这个 Job ,初始化就是创建一个正在运行的 Job 对象(封装任务和记录信息),以便 JobTracker 跟踪 Job 的状态和进程。
-
Job 被作业调度器调度时,作业调度器会获取输入分片信息,每个分片创建一个 Map 任务,并根据 TaskTracker 的忙闲情况和空闲资源等分配 Map 任务和 Reduce 任务到 TaskTraker ,同时通过心跳机制也可以监控到 TaskTracker 的状态和进度 ,也能计算出整个Job 的状态和进度。
-
当JobTracker 获得了最后一个完成指定任务的 TaskTracker 操作成功的通知时候, Jo Tracker 会把整个 Job 状态置为成功,然后当查询 Job 运行状态时(注意:这个是异步操作),客户端会查到 Job 完成的通知 。
-
如果 Job 中途失败, MapReduce 会有相应的机制处理 。一般而言,如果不是程序员程序本身有 bug ,MapReduce 错误处理机制都能保证提交的 Job 能正常完成。
那么, MapReduce 到底是如何运行的呢?
我们按照时间顺序, MapReduce 任务执行包括:
输入分片 Map 、Shuffle 和 Reduce 等阶段,一个阶段的输出正好是下一阶段的输入。

上图从整体角度很好地表示了 MapReduce 的大致阶段划分和概貌。

而具体各阶段的作用,可参考如下:

四、小结
这一章节,主要还是从数据处理角度集中介绍了 Hadoop 的相关知识。Hadoop 的 HDFS 和 MapReduce 是离线数据处理的底层技术,实际开发中大家还是很少通过编写 MapReduce 程序来处理大数据,相反大家主要用基 MapReduce 的高级别抽象 Hive ,效率更高,而且更容易使用。这也是下面会重点和大家讲的离线数据处理中的主要技术—— Hive。