大数据开发

1、实时数据平台整体架构
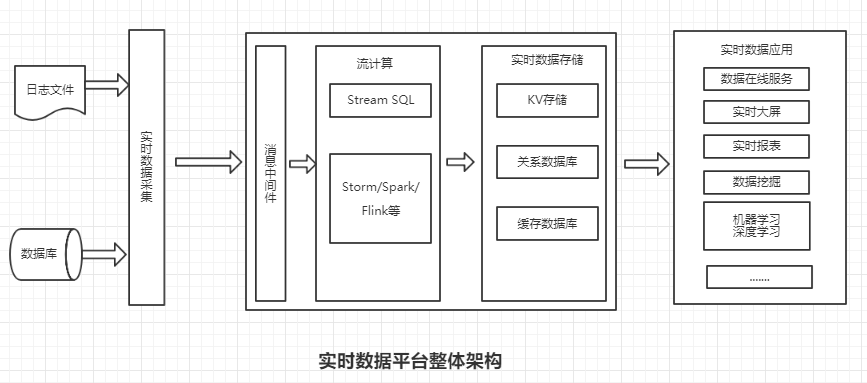
实时数据平台的支撑技术主要包含四个方面:实时数据采集(如Flume),消息中间件(如Kafka), 流计算框架(如Storm, Spark, Flink和Beam),以及数据实时存储(如列族存储的HBase)
实时数据平台最为核心的技术是流计算。
2、流计算
流计算的典型特征:
1、无边界:流计算的数据源头是源源不断的,就像河水一样不停第流过来,相应地,流计算任务也需要始终运行。
2、触发:不同于Hadoop离线任务是定时调度触发,流计算任务的每次计算是由源头数据触发的。触发是流计算的一个非常重要的概念,在某些业务场景下,触发消息的逻辑比较复杂,对流计算挑战很大。
3、延迟:很显然,流计算必须能高效地、迅速地处理数据。不同于Hadoop任务至少以分组甚至小时计的处理延迟,流计算的延迟通常在秒甚至毫秒级,分组级别的延迟只有在特殊情况下才能被接受。
4、历史数据:Hadoop离线任务如果发现历史某天的数据有问题,通常很容易修复问题而且重运行任务,但是对于流计算任务基本不可能或代价非常大,以为首先实时流消息不会保存很久(一般几天),而且保存历史的完全
现场基本不可能,所以实时流计算一般只能从问题发现的时刻修复数据,历史数据是无法通过流式方式来补的。
3、数据管理
数据管理包括数据探查、数据集成、数据质量、元数据管理和数据屏蔽
数据探查:就是对数据的内容本身和关联关系等进行分析,包括但不限于需要的数据是否有、都有哪些字段、字段含义是否规范明确以及字段的分布和质量如何等。
数据集成:数据仓库的数据集成也叫ETL(抽取:extract、转换:transform、加载:load),是数据平台构建的核心,ETL泛指将数据从数据源头抽取、经过清洗、转换、关联等转换,
并最终按照预先设计的数据模型将数据加载到数据仓库的过程。
互联网科技发展蓬勃兴起,人工智能时代来临,抓住下一个风口。为帮助那些往想互联网方向转行想学习,却因为时间不够,资源不足而放弃的人。我自己整理的一份最新的大数据进阶资料和高级开发教程,大数据学习群:868847735 欢迎进阶中和进想深入大数据的小伙伴加入。