前言
前面几篇文章对Shader及CG语言做了大概的介绍,算是为了编写Shader做的前期准备,但在真正写之前还是有必要把渲染管线再详细说一下,这样在写Shader时,才能更加清晰明白每一步的意义
渲染管线
渲染管线主要是用于3D渲染,可以理解为一个流程,即CPU方面准备一些数据传给GPU,GPU对数据处理得出一张二维图像的过程。渲染流程主要分为几个大的阶段
- 数据准备阶段
- 顶点着色阶段
- 图元装配阶段
- 几何着色阶段
- 光栅操作阶段
- 片段着色阶段
- 测试与混合
下面来分别说一下。
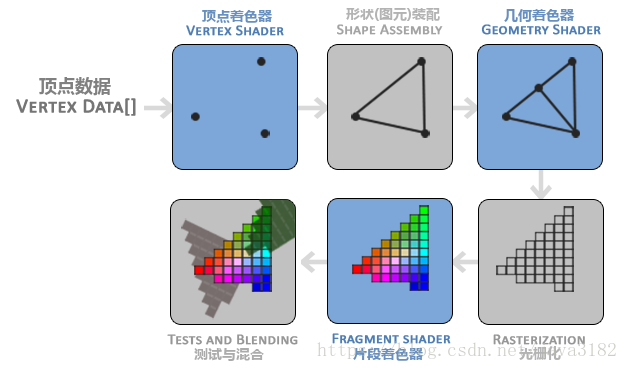
数据准备阶段
这个主要是CPU的工作,CPU准备好顶点数据,设置好各种状态,图片资源,Shader命令,打包发送给GPU。
这个阶段一般会遇到如下几个问题:
- 数据从哪里来?
- 如何用尽可能少的drawcall次数,提交给GPU更多的数据,
- 如何剔除掉无用的数据,减少GPU负担.
等等
这些事情一般都由引擎来做,在这里不展开来讲
那数据都包括哪些以及用来做什么呢?
- 位置position:这个是最基本的
- 索引信息indexs:组装成图元
- 颜色color:颜色信息主要用做插值用。
- 法线normals:用于光照计算
- 切线tangent:用于光照计算
- 副法线binormal:也是用于光照计算
- 纹理坐标uv:用于贴图,携带数据(如法线贴图携带法线相关的信息)
- 骨骼信息bones:用于骨骼动画
- 骨骼权重信息bonesweight:用于骨骼动画
- 各种常量数据(世界矩阵,观察矩阵,灯光的位置,纹理因子等)
这些都是编写Shader时的原料,通过算法操作就可以实现更种神奇的效果了
顶点着色阶段
CPU将各种数据准备好后,提交给GPU后(这些数据称为顶点数据),首先要处理的就是顶点数据,这是一个可编程的阶段,完全由程序员自己实现。在这个阶段有以下几个问题:
- 为什么要先经过顶点处理阶段呢?
- 一般哪些操作在顶点着色中进行?
为什么要先经过顶点处理阶段呢
- 顶点处理阶段主要就是确定顶点的位置,位置确定下来,才能产生进一步的优化方案。比如,某个点或某个面是保留还是剔除掉,都需要位置信息
- 顶点处理比像素处理执行次数少,有些数据先在顶点处理好再传给像素着色会节省很多的计算时间
一般哪些操作在顶点着色中进行?
- 空间变换:顶点数据中的位置信息一般都是指的模型空间,是相对位置,为了计算方便及确定模型的绝对位置需要将模型的相对位置信息转为世界空间的位置,有了世界空间的位置接下来要处理的就是视空间了,也就是摄像机空间,这个主要是方便投影和裁剪操作,为呈现到屏幕的数据做准备,之后就是投影矩阵的操作,分正交投影和透视投影两种,投影裁剪到屏幕空间
- 光照计算
图元装配阶段
这个阶段主要是将顶点着色器输出的所有顶点装配成指定图元的形状。这个阶段主要是由硬件执行
几何着色阶段
可以产生新顶点构造出新的图元,生成其他形状。这个一般用的不多,暂不进行深入展开
光栅化阶段
这个阶段也是主要由硬件实现,包括
- 视口变换
- 背面剔除
- 顶点插值操作
- 生成fragment片段
这个阶段因为算法固定,也没什么可操作空间,硬件实现又比较快,所以这个阶段不能自由操作
像素着色阶段
像素着色阶段接收光栅化后的片段数据,输出颜色值,这个阶段是做一些效果的主要阶段。许多的图像效果都在这里完成,如遮罩,水波,扰动,流光,描边,发光,阴影等好多效果,之后会详细说明
Alpha测试和混合阶段
像素阶段处理完后,还不能最终显示到屏幕上,还要做深度测试,模板测试,进一步去掉不需要的数据,之后进行alpha混合,就可以到达framebuffer等待显示了。当然此时也可以从framebuff中取出数据做后处理特效。
总结
图形渲染管线非常复杂,饮食许多可配置的部分,通过只需要配置顶点和片段着色器,几何着色器是可选的,一般都有一个默认的,使用默认的就可以了。在写Shader时一定要熟悉数据在各阶段的流动及做了哪些操作,才能在写shader时得心应手,效果达不到预期时,也可以知道错在哪个环节。接下来就该进入具体Shader实现阶段了。