1、什么是索引
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。索引是针对表而建立的,它是由数据页面以外的索引页面组成的,每个索引页面中的行都会含有逻辑指针,以便加速检索物理数据。
在数据库系统中建立索引主要有以下作用:
(1)快速取数据;
(2)保证数据记录的唯一性;
(3)实现表与表之间的参照完整性;
(4)在使用ORDER by、group by子句进行数据检索时,利用索引可以减少排序和分组的时间。
优点
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
缺点
1.索引需要占物理空间。
2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
2、索引的数据结构
B树、哈希表、R树
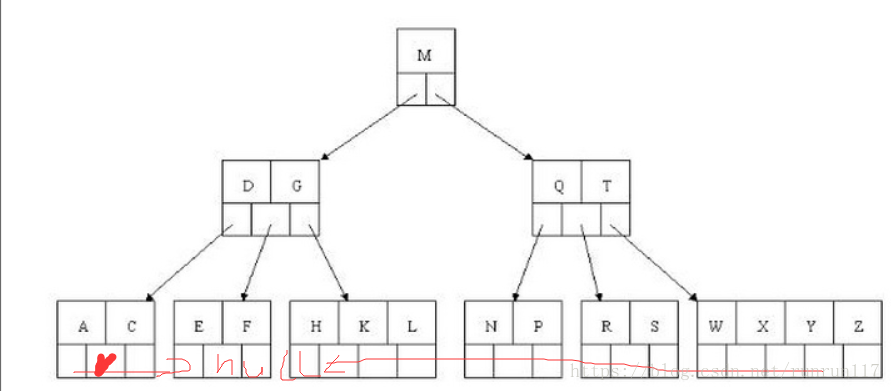
B树(B-tree):数据存储时有序的,灵活。B-树结构支持插入、控制操作以及通过管理一系列树根状结构的彼此联通的节点中来做选择。B-树结构中有两种节点类型:索引节点和叶子节点。叶子节点是存储数据的,而索引节点是用来告诉用户存储在叶子节点中的数据的顺序,并帮助用户找到数据。B-树不是二叉树,二叉树只是一种简单的节点层次结构的实现。

特点:m阶代表一个树节点最多有多少个查找路径,m阶=m路,当m=2则是2叉树,m=3则是3叉。上图最多是3,所以是3叉
1、是一个平衡多叉树(二叉排序树(二叉搜索树)+左右两个子树的高度差的绝对值不超过1)一个父亲节点下有多个子节点,子节点个数=父节点内的关键字个数+1
2、子节点个数=父节点内的关键字个数+1。因为父节点的关键字是子节点的索引。每个结点中关键字从小到大排列,并且当该结点的孩子是非叶子结点时,该k-1个关键字正好是k个孩子包含的关键字的值域的分划。
3、所有的叶子节点都出现在同一层,且有指向下一层的指针,只不过是null
4、节点中的关键信息是从小到大排列的
转载:
平衡二叉树、B树、B+树、B*树 理解其中一种你就都明白了
https://zhuanlan.zhihu.com/p/27700617
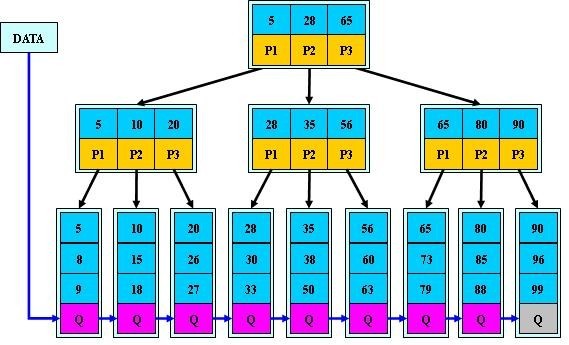
B+树:
B+-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+树和m阶的B树的异同点在于:
1.有n棵子树的结点中含有n-1 个关键字; (此处颇有争议,B+树到底是与B 树n棵子树有n-1个关键字 保持一致,还是不一致:B树n棵子树的结点中含有n个关键字,待后续查证。暂先提供两个参考链接:①wikipedia http://en.wikipedia.org/wiki/B%2B_tree#Overview;②http://hedengcheng.com/?p=525。而下面B+树的图尚未最终确定是否有问题,请读者注意)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
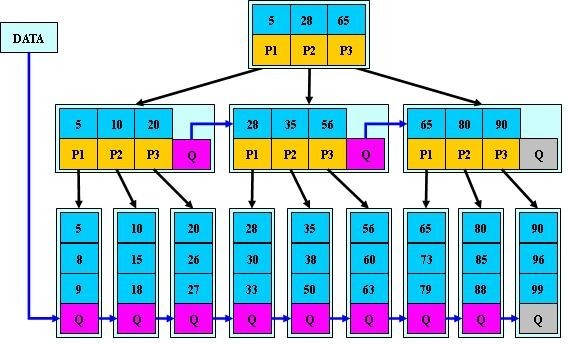
B*树:
B*-tree是B+-tree的变体,在B+树的基础上(所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针),B*树中非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。给出了一个简单实例,如下图所示:
转载: (JULY)从B树、B+树、B*树谈到R 树https://blog.csdn.net/v_JULY_v/article/details/6530142/
哈希:存储是无顺序的,适合查具体的值
R树:R-Tree作为数据结构的索引通常用来为空间问题提供帮助
R树在数据库等领域做出的功绩是非常显著的。它很好的解决了在高维空间搜索等问题。举个R树在现实领域中能够解决的例子:查找20英里以内所有的餐厅。如果没有R树你会怎么解决?一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满足要求。如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌地图这种超大数据库中,这种方法便必定不可行了。
R树就很好的解决了这种高维空间搜索问题。它把B树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性。因此,R树就是一棵用来存储高维数据的平衡树。
HashTree(转载:https://blog.csdn.net/yang_yulei/article/details/46337405)
我们选择质数分辨算法来建立一棵哈希树。
选择从2开始的连续质数来建立一个十层的哈希树。第一层结点为根结点,根结点下有2个结点;第二层的每个结点下有3个结点;依此类推,即每层结点的子节点数目为连续的质数。到第十层,每个结点下有29个结点。
同一结点中的子结点,从左到右代表不同的余数结果。
例如:第二层结点下有三个子节点。那么从左到右分别代表:除3余0,除3余1,除3余2.
对质数进行取余操作得到的余数决定了处理的路径。
结点结构:结点的关键字(在整个树中是唯一的),结点的数据对象,结点是否被占据的标志位(标志位为真时,关键字才被认为是有效的),和结点的子结点数组。

3、sqlserver数据存储结构
SQL Server数据库存储(结构)的最小单位是页,大小为8K,共8 * 1024 = 8192Byte,不论是数据页还是索引页都是以此方式存放
表中所有数据页的存放在磁盘上又有两种组织方式:
- 堆表;
- 索引组织表
如果表中所有数据页是以一种页间无序、随机存储的方式,则称这样的表为堆表;
否则如果表中数据页间按某种方式(如表中某个字段)有序地存储与磁盘上,则称为索引组织表。
平衡二叉树

B树、B-树、B+树与红黑树
https://blog.csdn.net/qq_17612199/article/details/50944413