一、B+树定义
在数据结构中我们经常用到二叉树,这种数据结构的时间复杂度是O(logn),相对于数组、链表有较好的 读、写效率。B+树是二叉树的一种变种,它既有 二叉树 数据有序性、良好读写效率 又可以控制树的高度,避免二叉树退化为链表。
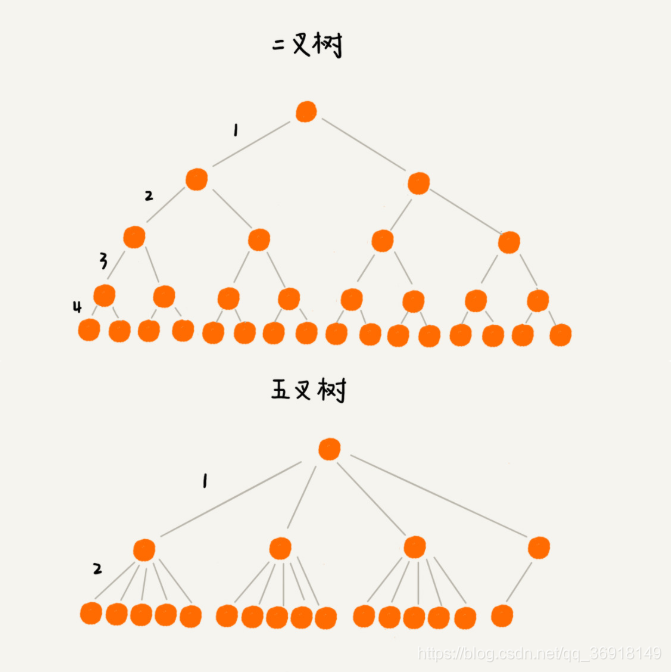
- B+树就是M叉树,其必须符合如下条件:
- 每个节点个数不能超过M,但不能小于M/2;
- 根节点的子节点树可以小于M/2;
- 通过链表将叶子节点连在一起,这样方便区间查找;
二、为什么选用B+树作为索引
我们知道的 散列表、平衡二叉树、跳表 都有较好的读写效率,为什么非要用一个M叉树呢?
-
散列表:在MySQL中,是有这种HASH索引方法,这种数据结构读取数据效率非常高,时间复杂度O(1),但是不支持按区间快速查询数据;
-
平衡二叉树:查询效率比较好,时间复杂度是O(logn),而且数据具有有序性便于区间查询,但无法支持区间快速查询;
-
跳表:跳表是在链表之上加上多层索引构成,它支持快速的
插入、查询、删除数据对应的时间复杂度是O(logn),且支持区间查询只需要定位到起始节点,然后这个节点开始,顺序遍历链表,直到区间终点为止。跳表需要将所有数据都存到内存,需要消耗较大的内存空间。
三、B+树构建索引过程
1)将叶子节点串在一个链表上,链表上的数据是从小到大有序的,这样查询区间数据的时候, 拿到起始数据向后遍历到截至数据,就是所需数据。
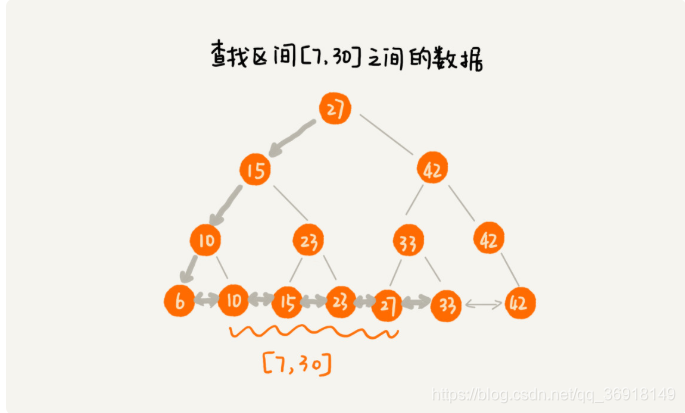
2)一般情况, 根节点被存储在内存中,其它节点存储在硬盘中。
M叉树,如果高度是N,读取数据的时候需要与硬盘有N次IO,这样比二叉平衡树少了IO次数,且节约了内存空间 。
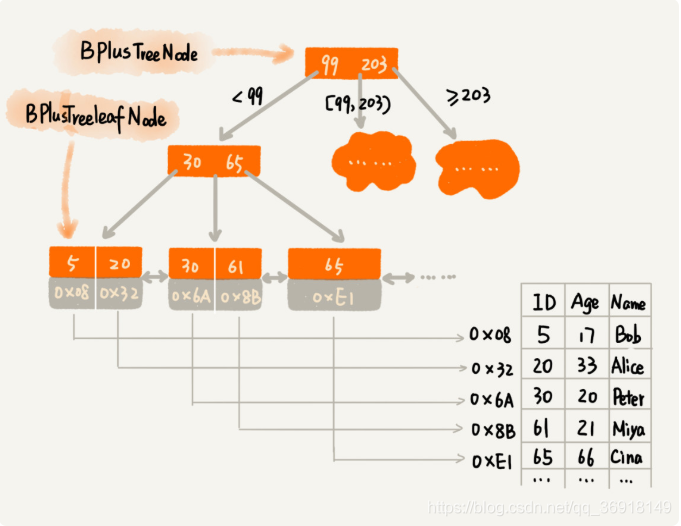
3)数据写入,会导致索引更新,导致写入变慢
在B+树中,M(树高度)值是已经计算好的,在数据写入过程中, 可能会到值子节点数量大于M,这个节点大小大于页的大小,需要对B+树结构进行更新。需要将一个节点分裂为两个节点,这样分裂后上级节点可能超过M个,用同样方法将父级节点分裂为两个节点。这种反映是 之下而上,一直影响到根节点。

3)B+树会导致删除数据变慢
删除数据的时候, 需要更新B+树中的节点信息。如果某节点子节点少于M/2,就需要将相邻的兄弟节点合并,如果在合并后节点的子节点数超过了M,那就需要要在分裂节点。
