数据库索引的目的:提高数据查询的效率
可以用作索引提高查询效率的数据结构:
1.Hash
优点:kv结构,查询单个目标,时间复杂度O(1)
缺点:
需要范围查找,<,>,group by,order by等,会导致时间复杂度退化为O(n)(PS:此时树形依旧保持O(log(n)))
InnoDB不支持哈希索引,InnoDB会根据表的使用情况自动为表生成hash索引,不能人为干预是否在InnoDB一张表中创建HASH索引,如果InnoDB注意到某些索引值被使用的特别频繁时, 它会在内存中基于Btree的索引之上再创建一个HASH索引,这样BTREE索引也具备了HASH索引的一些优点
2.二叉树
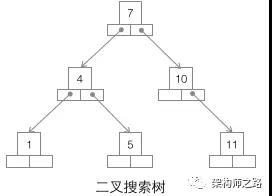
缺点:
索引不止存在于内存,也会存到磁盘,如果100万节点,树高20,一次可能要访问20个数据库,而从磁盘随机读一个数据库需要10ms左右的寻址,这也意味着需要很多次的磁盘查询,十分耗费时间。(这也是我们使用n叉树的原因之一)

3.B树
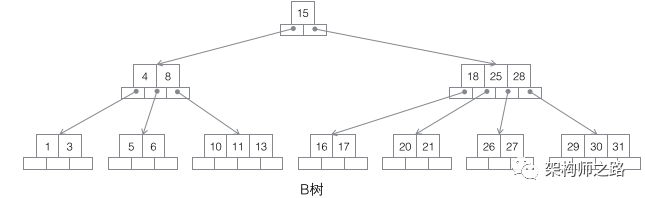
什么是局部性原理?
局部性原理的逻辑是这样的:
(1)内存读写块,磁盘读写慢,而且慢很多;
(2)磁盘预读:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,如果未来要读取的数据就在这一页中,可以避免未来的磁盘IO,提高效率;
画外音:通常,一页数据是4K。
(3)局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘IO
B树为何适合做索引?
(1)由于是m分叉的,高度能够大大降低;
(2)每个节点可以存储j个记录,如果将节点大小设置为页大小,例如4K,能够充分的利用预读的特性,极大减少磁盘IO;
4.B+树

InnoDB的索引类型分为主键索引及非主键索引:
主键索引(聚簇索引):叶子节点存的是整行数据
非主键索引(二级索引):叶子节点的内容是主键索引的值
所以通过非主键索引查询数据的顺序是,查询到费主键索引对应的主键,再通过主键查询一次,这个行为成为回表,这也是主键索引的查询效率优于非主键索引的原因。
B+树,如上图,仍是m叉搜索树,在B树的基础上,做了一些改进:
(1)非叶子节点不再存储数据,数据只存储在同一层的叶子节点上;
画外音:B+树中根到每一个节点的路径长度一样,而B树不是这样。
(2)叶子之间,增加了链表,获取所有节点,不再需要中序遍历;
这些改进让B+树比B树有更优的特性:
(1)范围查找,定位min与max之后,中间叶子节点,就是结果集,不用中序回溯;
画外音:范围查询在SQL中用得很多,这是B+树比B树最大的优势。
(2)叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的PK,用于查询加速,适合内存存储;
(3)非叶子节点,不存储实际记录,而只存储记录的KEY的话,那么在相同内存的情况下,B+树能够存储更多索引;
