这个问题其实还是很有趣的,我在上一篇文章中,写了:
1、为什么数据库索引不能用二叉排序树;
2、为什么数据库索引不能用红黑树;
本篇文章增加了:
1、为什么不能使用哈希表;
2、为什么不能使用B-树;
3、为什么能使用B+树。
一、为什么数据库的索引不能用二叉搜索树?
根据上面的演示,看着二叉搜索树也是可以的呀,也挺快嘛。
但是为什么用在数据库底层不合适呢?这也是面试时常问的。
我们可以演示一下:
https://www.cs.usfca.edu/~galles/visualization/BST.html
我们假设我们给Col1加上索引,那么依次对二叉搜索树插入:1、2、3、4、5、6、7;
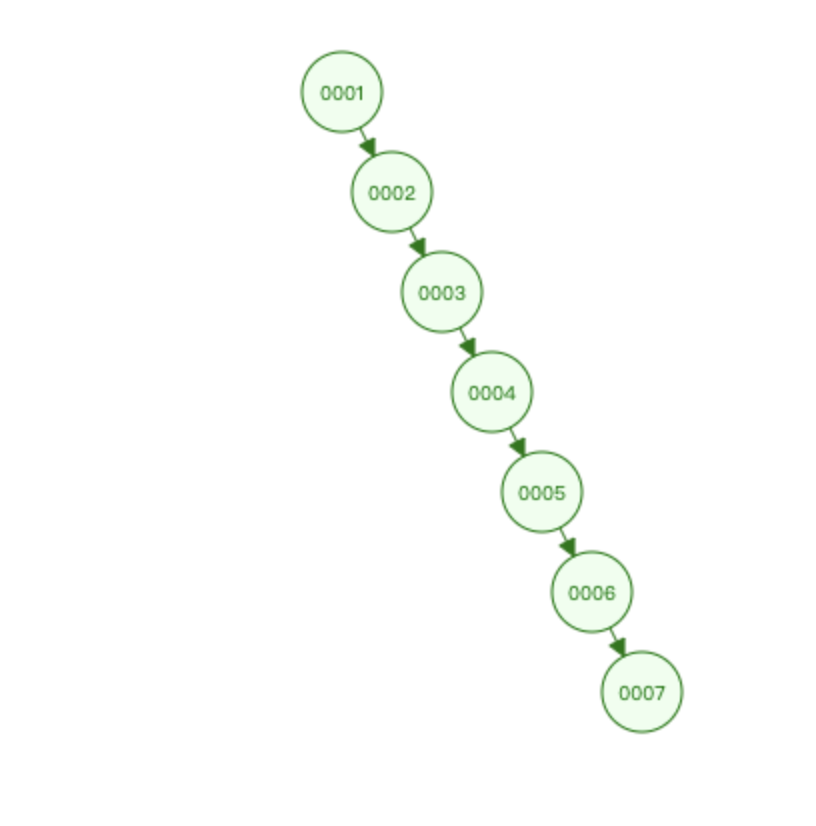
可以看到退化成了一个链表的形式。
当我们查询7的话,时间复杂度就变成了单链表一样了。
从大到小也是:
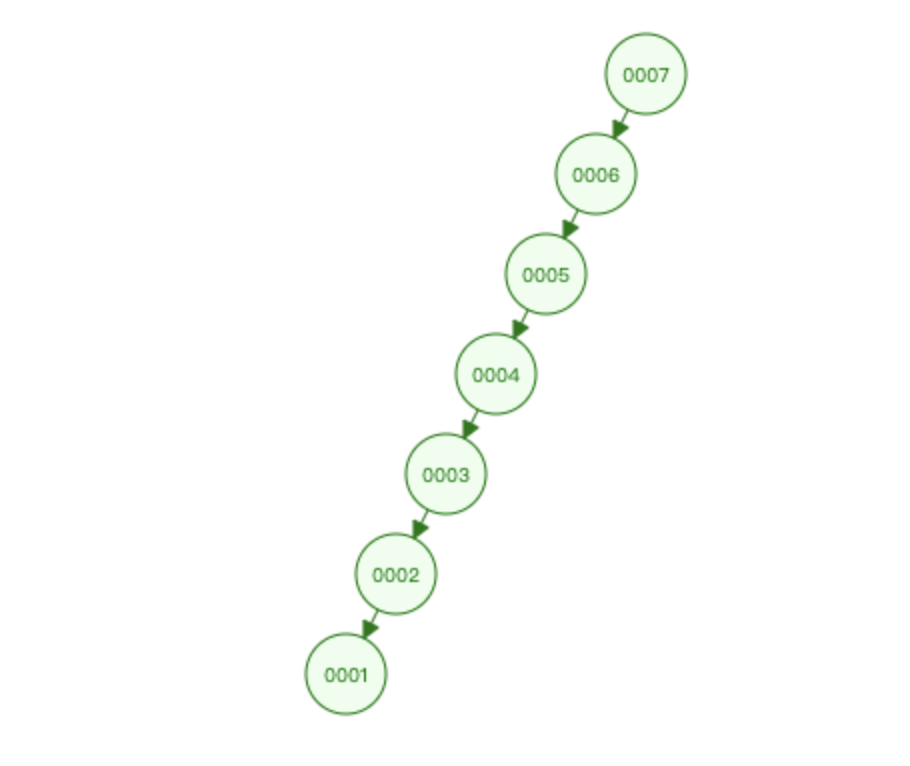
总结如下:
- 如果数据库底层使用二叉搜索树的话,遇到数据为极端的情况下会退化成单链表,所以不太合适;
可以想象一下,如果我们给自增的一列使用二叉搜索树的索引数据结构的话,是不是就很倒霉了。这就是极端的情况,都在一边。
二、为什么红黑树不适合数据库索引?
红黑树又叫:二叉平衡树
红黑树作为Java开发人员应该很耳熟吧,JDK8中的HashMap中的底层数据结构就用到了红黑树。
这么牛逼的JDK中都用到了红黑树,为什么数据库中的索引数据结构不太适合呢?
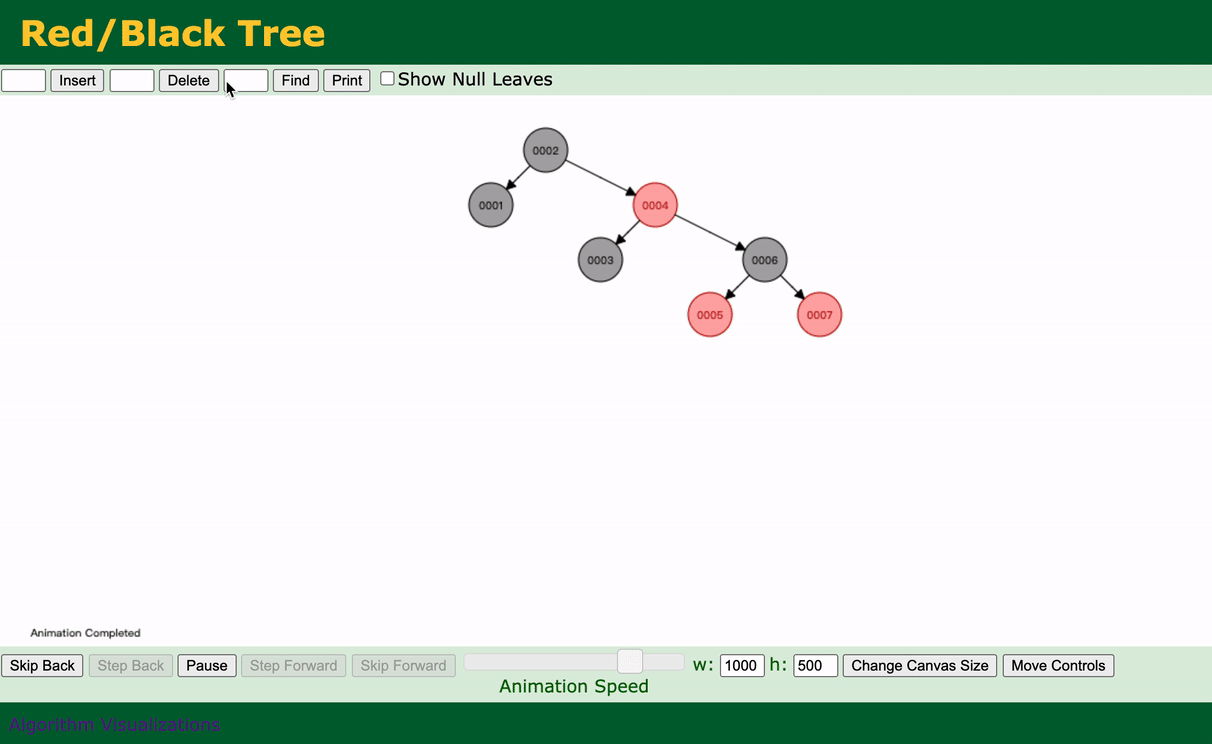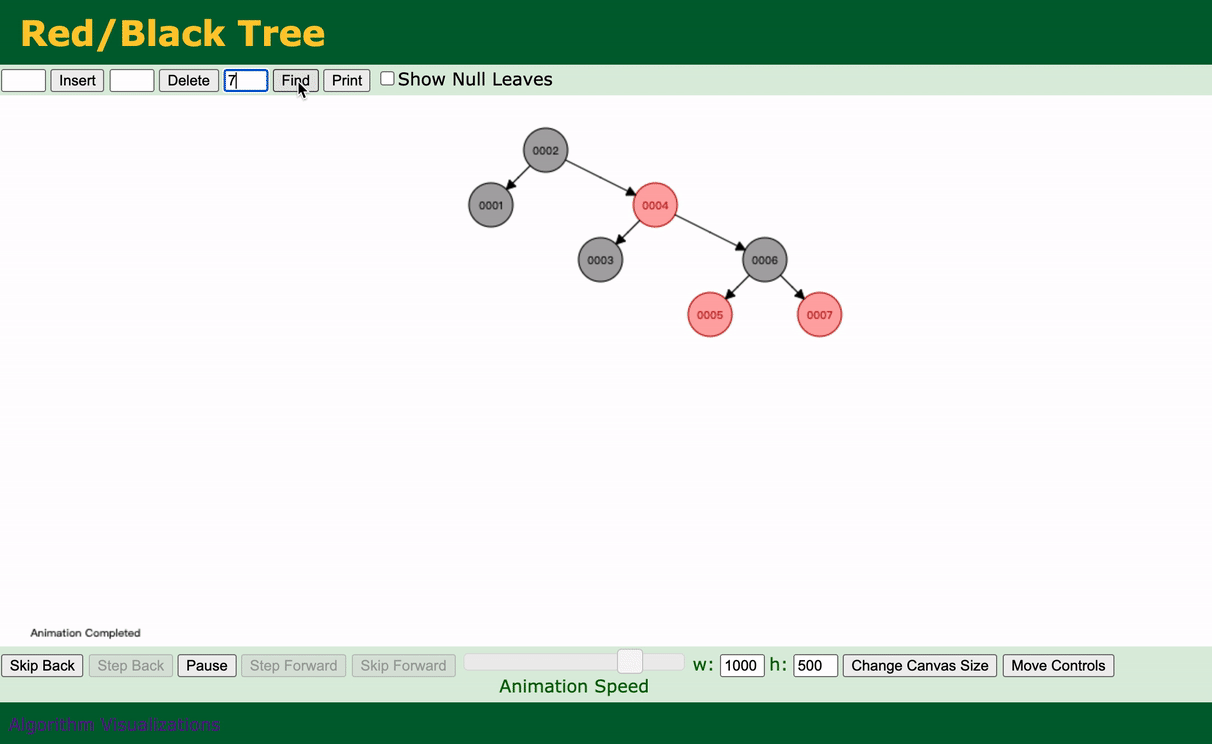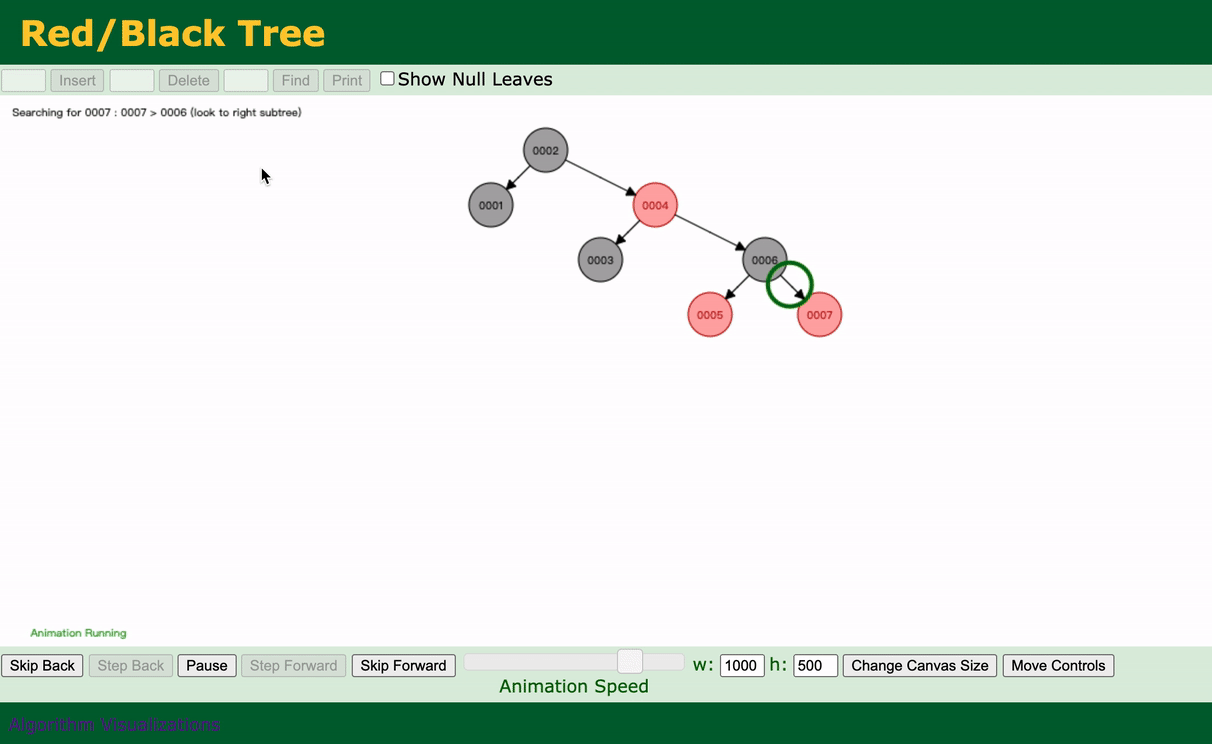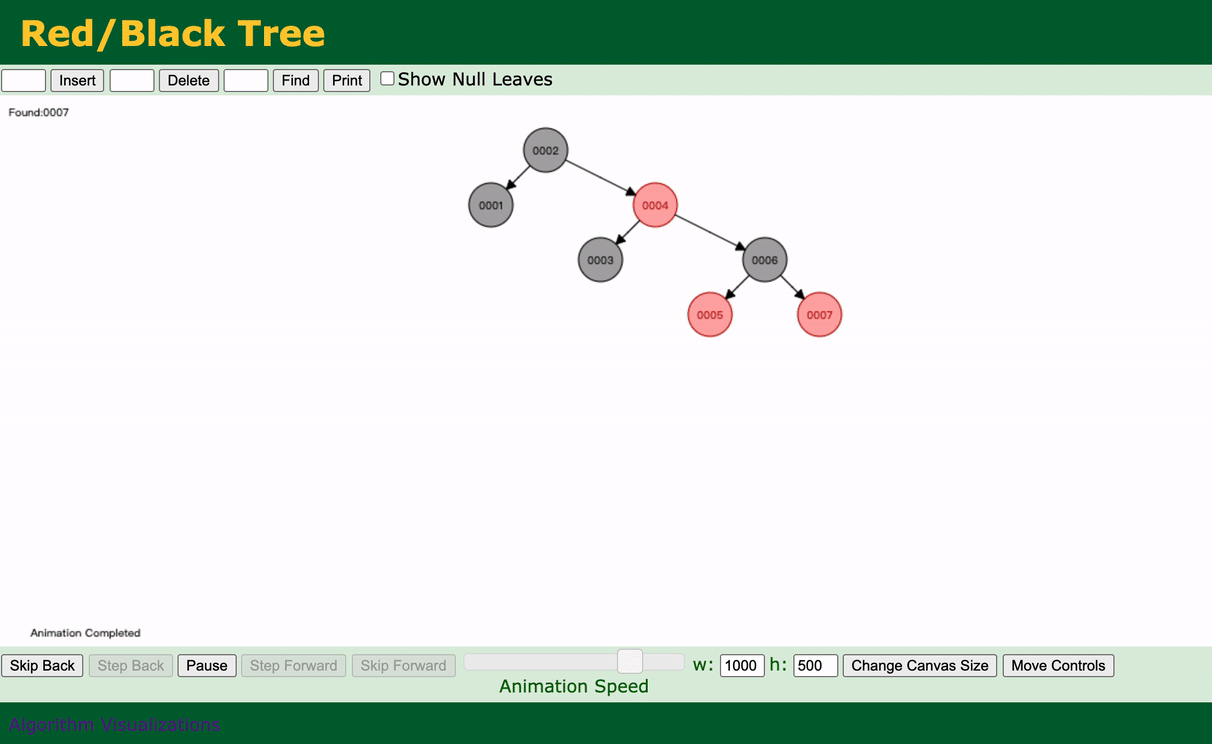
还是上面那个假设,假设我们给Col1加上红黑树的索引。
过程如下动态演示:
如果我们执行:
select * from table1 where Col1 = 7;
动态演示如下:
可以看到,我们一共查询了4次就查到了。与没加这个索引之前还是有比较大的效果的,至少没有全部扫描。
总结:
通过观察可以看到,每次插入几乎都会去调整这颗二叉树,保持高度是平衡的。
如果数据量非常大的话,也是非常耗时的,所以红黑树也是不太合适。
三、为什么不能使用Hash数据结构作为索引的数据结构呢?
当你点进这篇文章的时候,肯定对于Hash表是熟悉的了。
Hash表的话,简单点说有这么几个特点:
- 1、数据插入的位置由哈希值决定,顺序无序的;
- 2、插入很快;
- 3、查找也很快;
我们拿一组数据来插入哈希表试试:
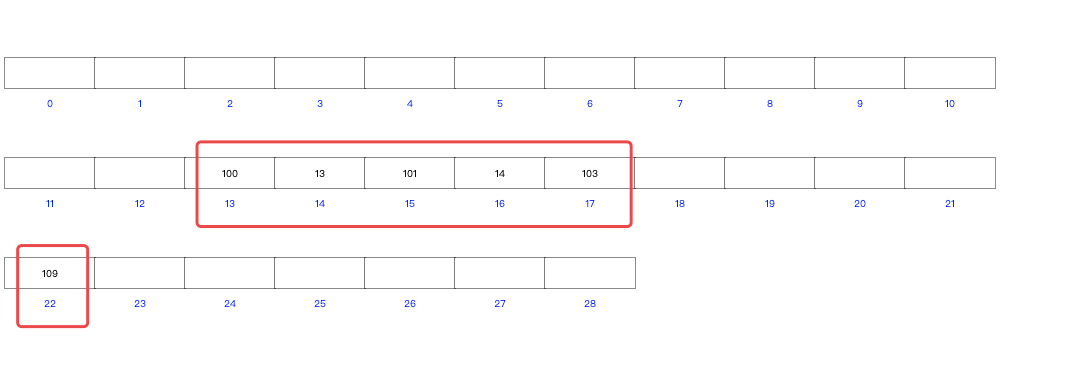
100、13、101、14、103、109
我们使用https://www.cs.usfca.edu/~galles/visualization/ClosedHash.html来动态模拟Hash表;
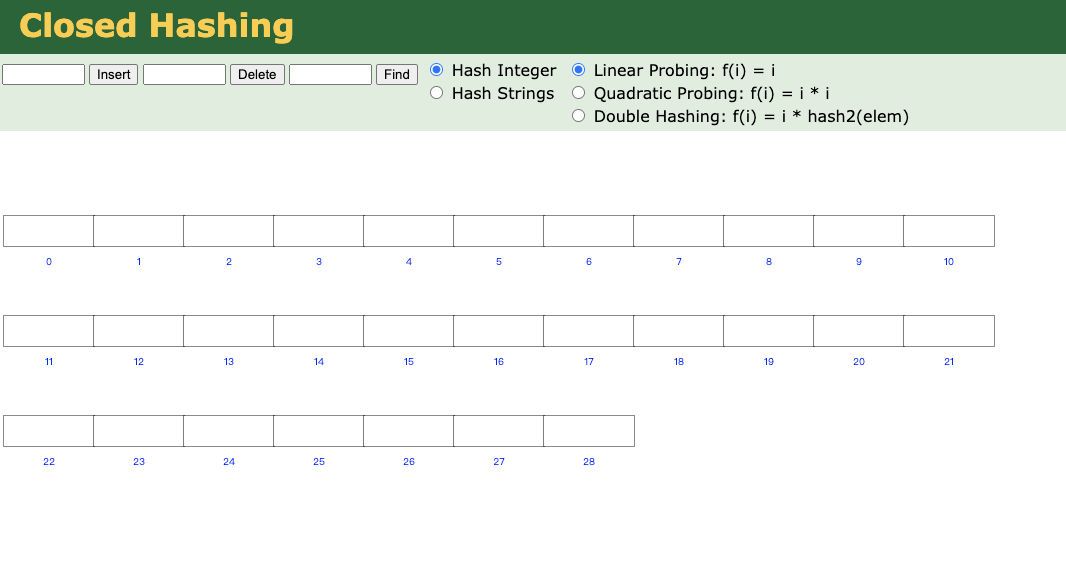
为了表现出来Hash表为什么不适用与数据库,我们顺序插入准备好的数据:
动态演示如下:
结果如下:
1、
我们在数据库中经常使用sql来查询一个范围的数据例如:
select * from t where id < 15;
我们知道哈希表是无序的,所以就凭借这一点,就比较困难。
心里应该也有数了,哈希表是肯定不可以的。
2、
从插入数据的动态演示中可以看到,100和13的哈希值都是13。
那么就会向后移动(这也是哈希表解决冲突的一种方式)。
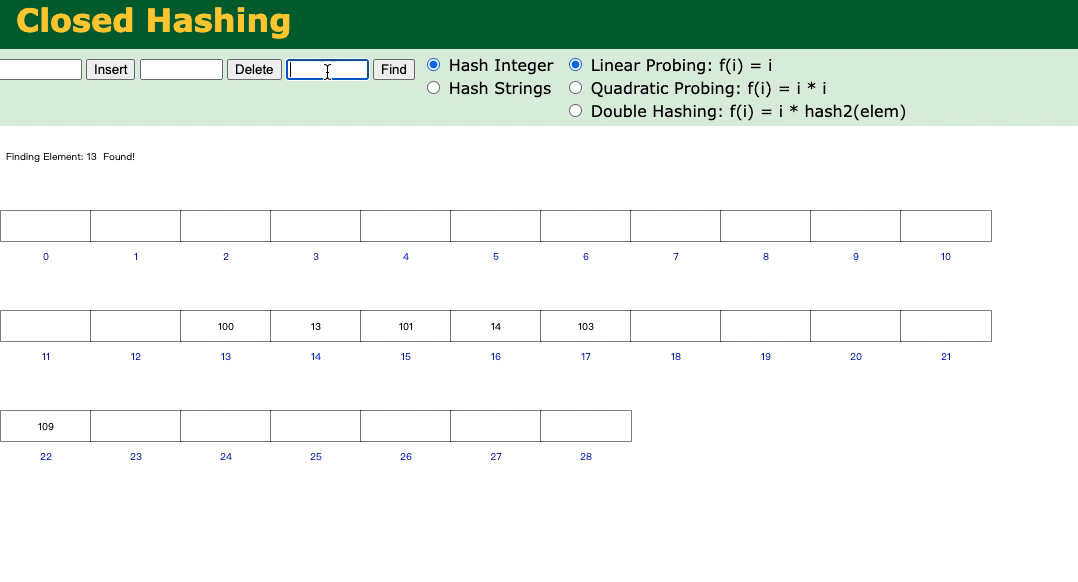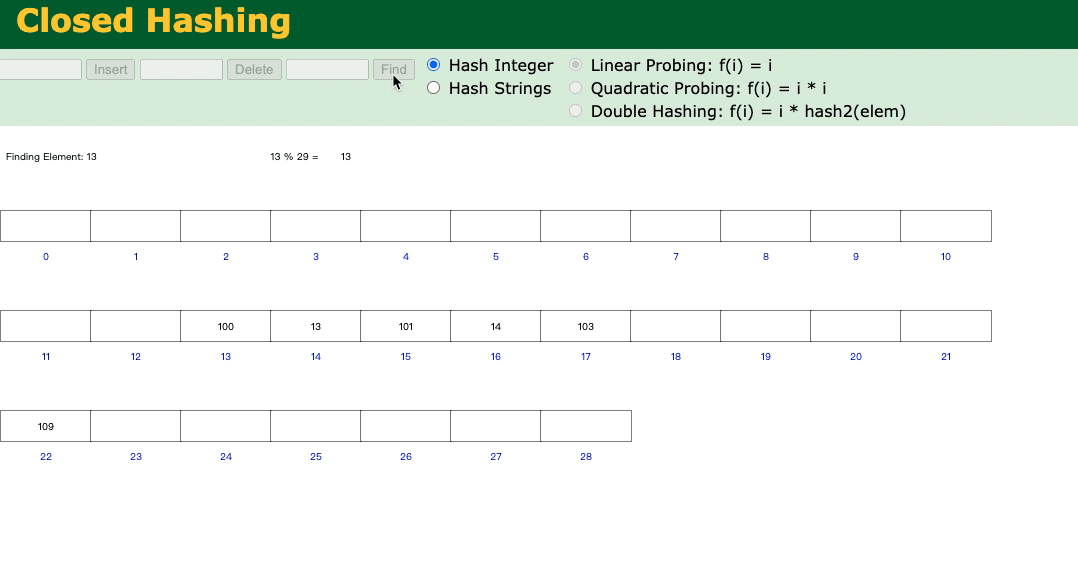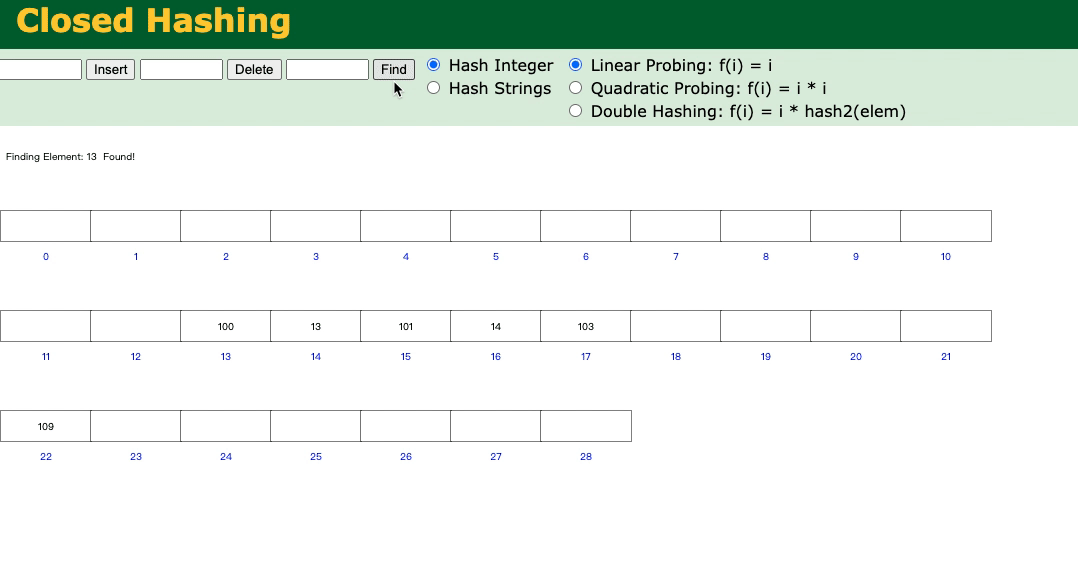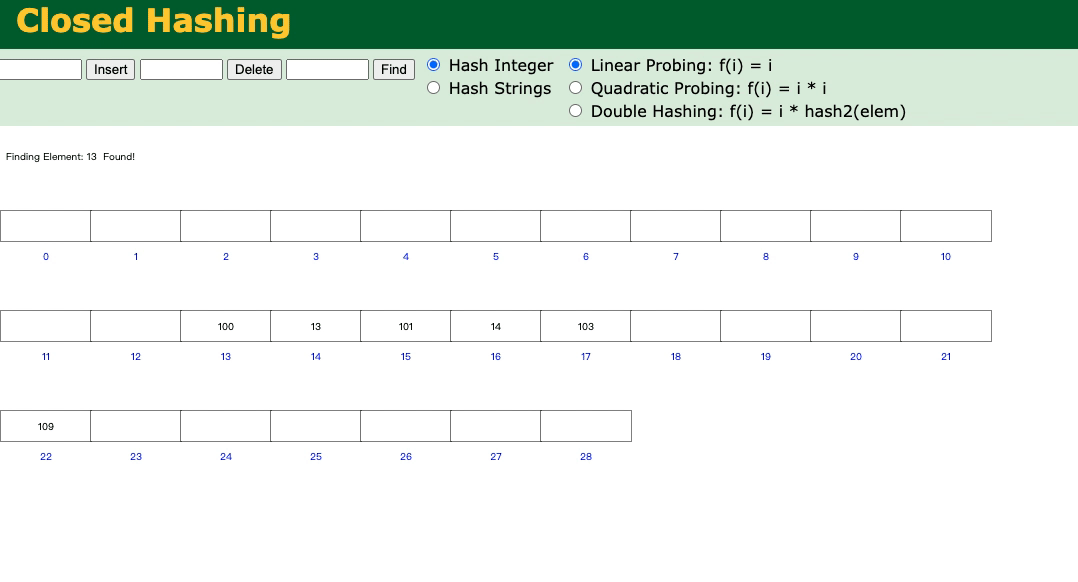
例如:我们先插入100,然后插入13;
我们想查找13的话,就会比较慢了。
两个数可能体现不出来,1万个?10万个?100万个数呢?可想而知,就相当于进行了全表扫描。
所以,哈希表总体来说,不合适。
四、为什么不能使用B-树
B-Tree就是B树,不叫B减树。
我们继续来模拟:
https://www.cs.usfca.edu/~galles/visualization/BTree.html
插入1-10,10个数后:
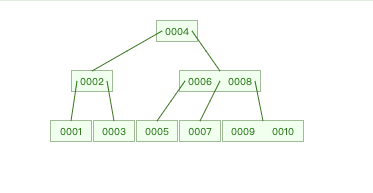
B树确实解决了我们上面所说的哈希表的查找范围的问题。
我们执行下列sql:
select * from t where id > 5;
(1)首先查找到5
查找路径为:4–>6–>5;
(2)然后返回上一层查找到6
(3)然后查找到6
(4)…
可以看到会有一个回旋的过程,随着数据量的增长,回旋的过程也就越多,那么所浪费的时间也就越多。
五、为什么能使用B+树
我们使用这个来模拟:
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
构造一个1-10的数的B+树;
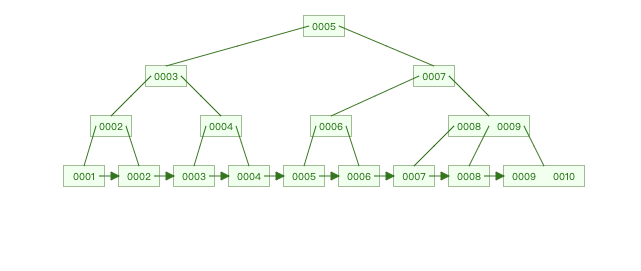
先来介绍以下这颗树:
一共分为两部分,叶子节点和非叶子节点。
- 叶子节点是由链表实现的,凡是插入的数据,全都链接在一起。
- 非叶子节点只存key;
- 叶子节点即存key又存value;
key:0-10这个数字;
value:0-10的数字的地址。
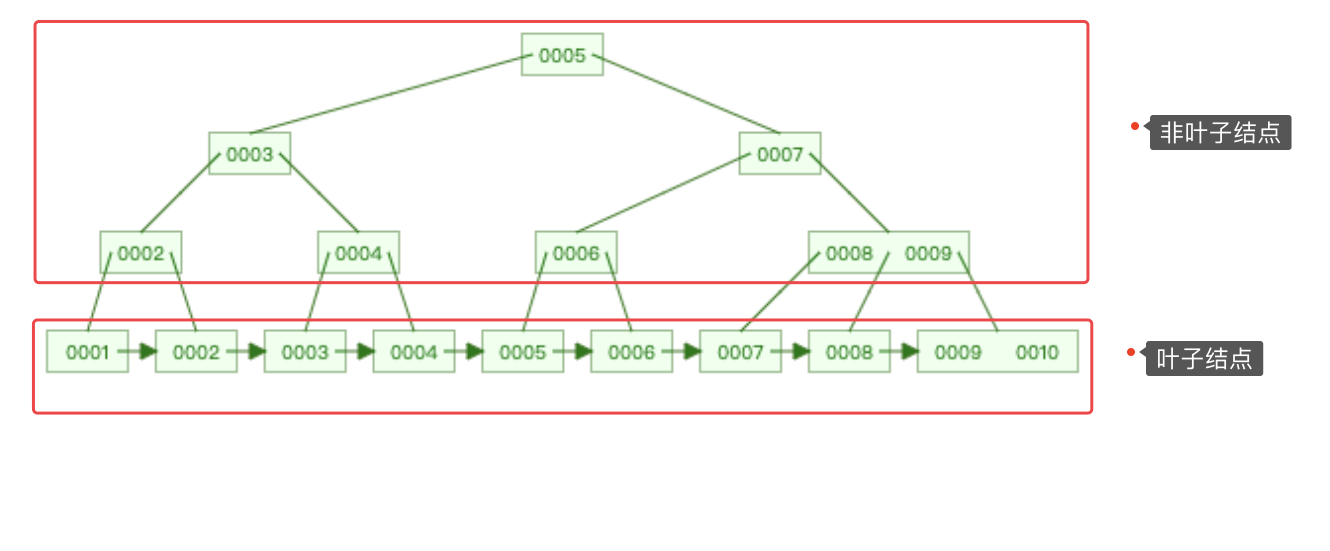
解决了B树中回旋查找的问题。查找效率也整体提高了。
例如:
select * from t where id > 5;
看下图:
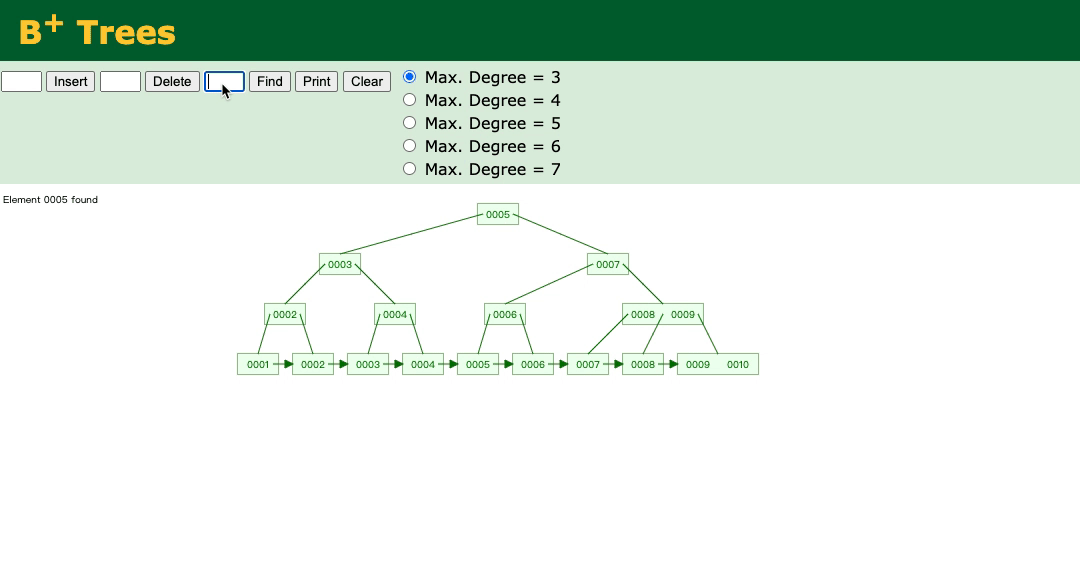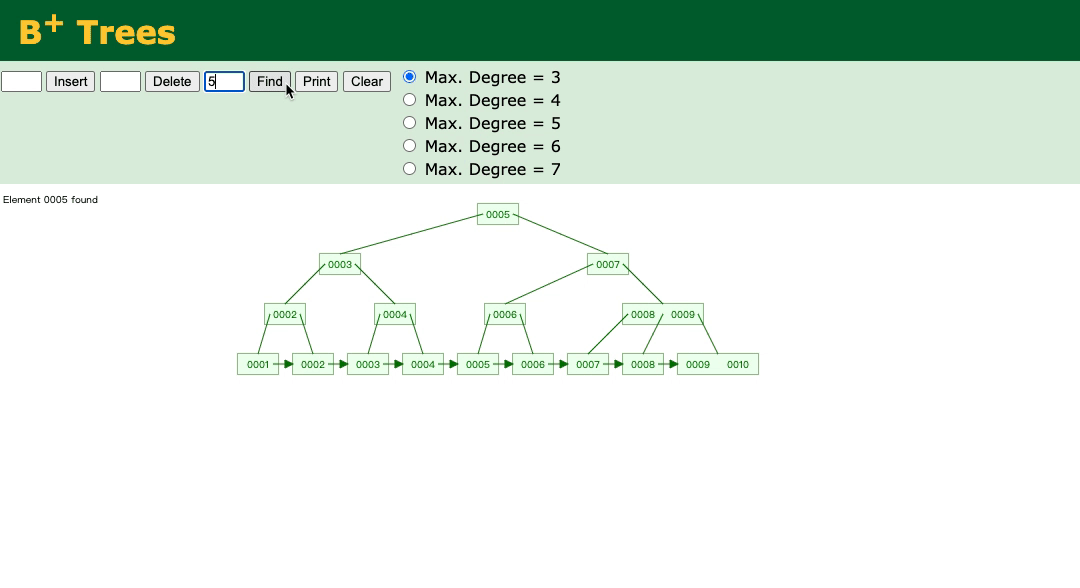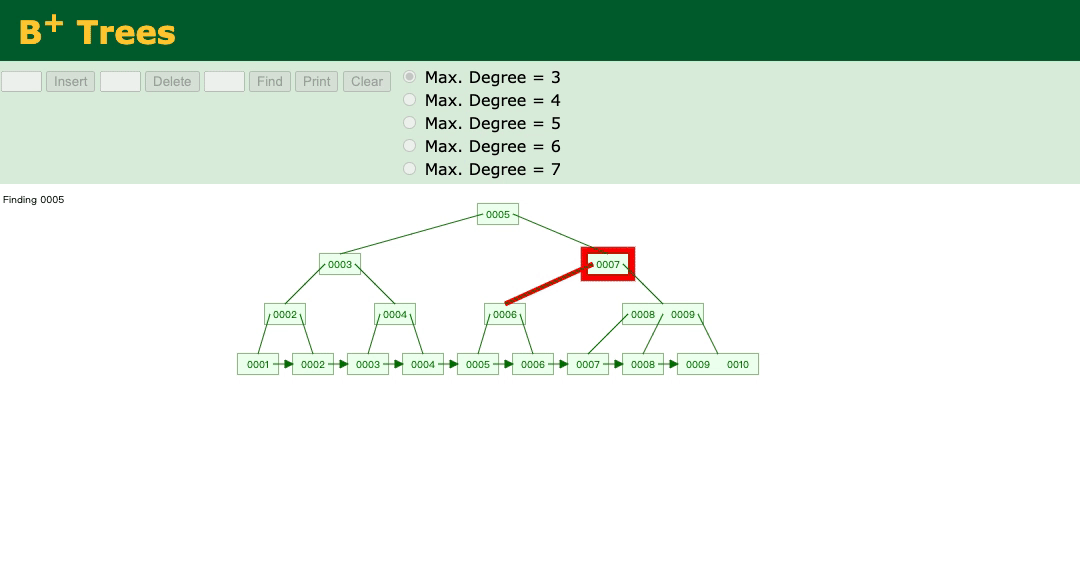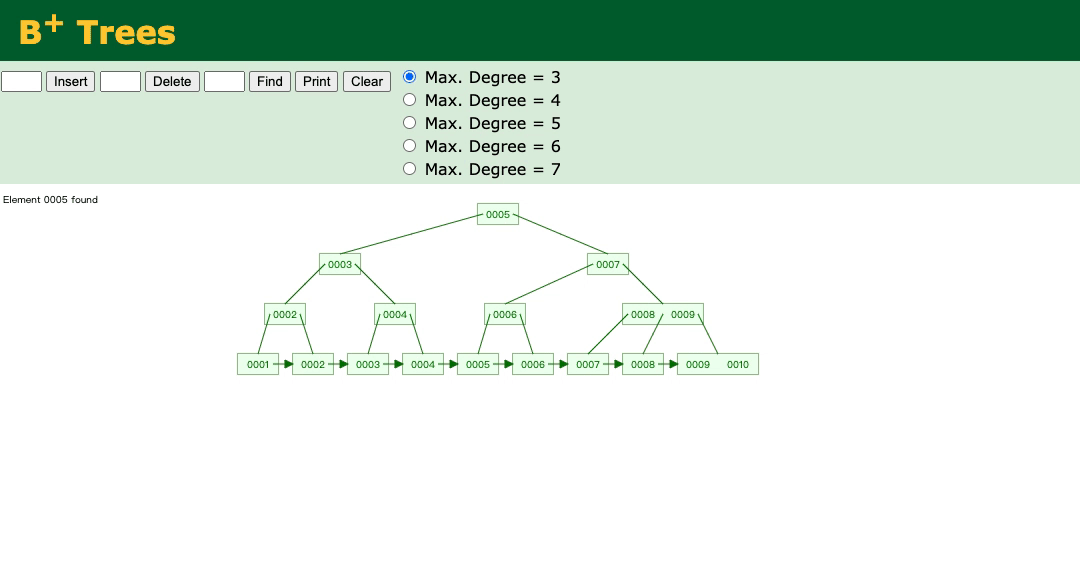
可以看到,先查找非叶子节点5、然后7、然后6,最终查找到叶子节点5。
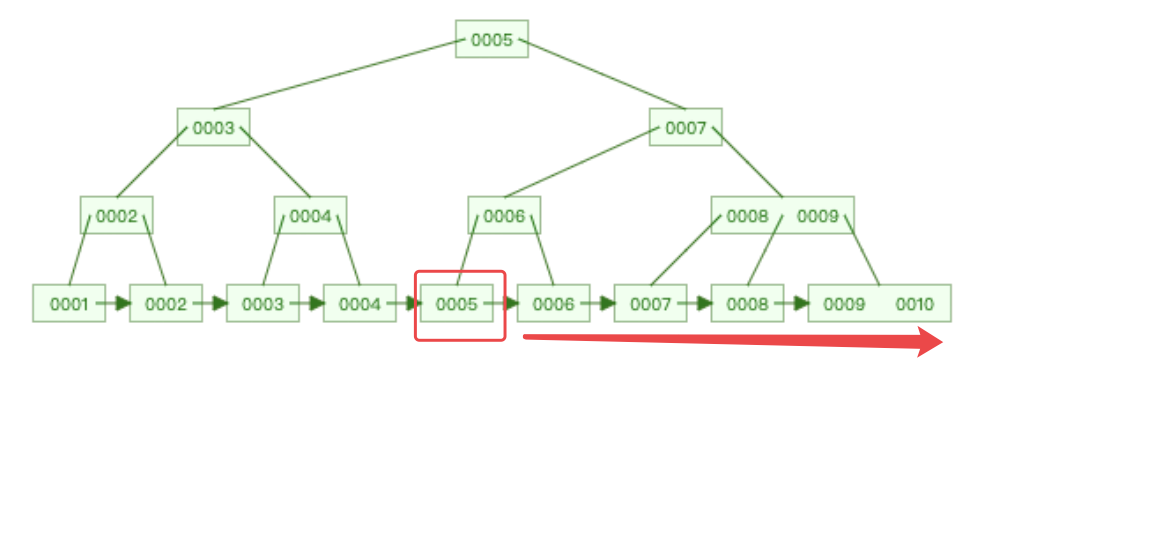
查找到之后,就可以顺序取出了,就不必继续回去上一层了。