1 前序
第一次遇到SVM,是在写爬虫作验证码的识别。做完预处理将数字弄成特征向量后,发现SVM能将其正确分类,从此对ML感兴趣。我第一步就想自己将sklearn实现的东西自己去写一遍,体会其中的精妙。结果过了一年半,即将步入本三,才敢说自己对机器学习,支持向量机有了浅显的认知。
当时在翻阅网上SVM的教程,发现到处充满了优化的痕迹:KKT, Slater强对偶条件,等等。现在认为混杂了太多优化和数学知识,门槛较高,会强迫读者去接受一些无法证明的结论。其中最有趣的,就是看各个教程各显神通从几何角度解释KKT条件了。然而,从建模角度看SVM,而非触及数值优化的部分,可以让读者清晰的知道SVM在做些什么。
2 介绍
本教程基于Learning from data一书第8章(电子版)整理所得。看懂教程需要:
- 基本的解析几何知识(例如知道三维空间平面可以表示为
等)
- 线性代数简单的运算操作(向量内积,矩阵乘法等)
- 证明中逻辑学的基本符号(因为所以等):
在本节教程你会学/不会学到:
- SVM的数学建模与推理√
- QP问题的数值求解方法×
- KKT条件,Slater强对偶情形×
- 使用python与cvxopt库的QP-solver去实现简单的SVM分类器√
- 步步推导,步步为营√
由于QP问题的数值解法(如内点法)学习门槛过高,也非我们主要关注对象。我引用布鲁斯·布坎南(Bruce G.Buchanan)对于计算机科学领域的分类方式,来说服你们:先别碰这些了。真要学,也不应该从SVM切入。
由于教程事先用letax格式书写,有些不方便迁移的部分用图片表示,敬请谅解。
4.2 支持向量(support vector)和分类间隔(margin)
3 SVM问题引入
3.1 SVM针对什么问题?
若读者学过PLA(perceptron learning algorithm),那么说明你能写一个可行的二元分类器了。若你没学过,问题不大。他们只比你们能多完成一件事:有一堆线性可分的数据,他们能寻找到一个超平面将数据分开。特别地,在二维情况下,超平面就是一根直线。让我们观察以下数据:
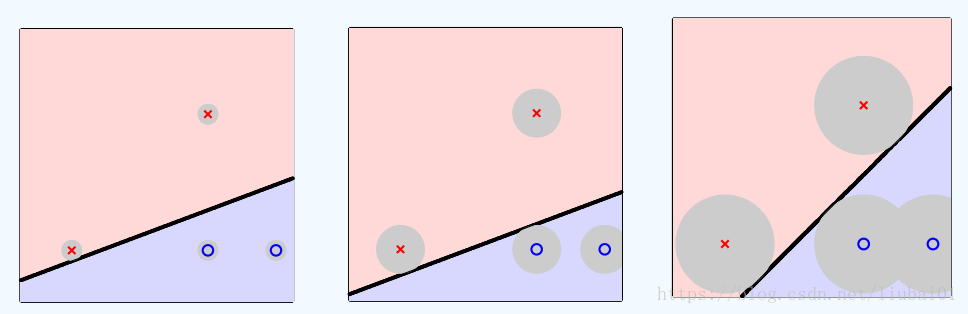
你发现什么?尽管都是行得通的分类器,然而他们给数据点舞动的空间不同。直觉上,若分类器能接受更大半径的噪音而不出错,那个分类就更鲁棒(robust),我们更喜欢。这里我们给出分类间隔直觉的上的定义:
Definition3.1.1 分类间隔(margin)直觉形式定义:给定有球形噪音的正负线性可分(linear sperable)样本,分类间隔为目标分类器所能接受的最大噪音半径。
基于直觉,给出最优分类器的两个基本假设:
- 能分类不出错(本博客介绍的Hard-Margin SVM只能分类线性可分的数据)
- 分类间隔最大
3.2数学记号
对于二元分类的问题,我们定义:
- 超平面对应的参数和偏置
- 第n个数据点/训练样本(data point, sample):
(维度为d),
。
- 线性分类器对应超平面为
- 分类器输出:
,sign(x)为符号函数。特别地,为避免混淆,定义sign(0)=-1。h(x)=+1我们认为分类器视x为正样本,h(x)=-1我们认为分类器视x为负样本。当
,我们就说分类器对于该样本分类正确。
4 SVM问题建模
4.1可行超平面
通过简单分类讨论,我们能得到:
Definition 4.1.1 可行超平面(separating hyperplane)全称量词定义形式:表示的超平面为可行超平面,当且仅当
:
...(1)
由于这一定义方式用到了任意符号。在逻辑学中是全称量词,为了方便记忆,称这种定义法为全称量词定义形式。这一定义基于的事实是:
与
同号时,分类视为正确

根据命题4.1.3,我们给出可行超平面存在量词定义形式:


结合这一结论,可以通过分类讨论得到:
Proposition4.1.6:对于任一可行超平面h和数据:
4.2 支持向量(support vector)和分类间隔(margin)

4.3 SVM优化目标

现在问题是,我们该如何将问题求解。在这里,我们希冀将问题转换为特定的标准QP问题。这样,我们实际coding时可以借助cvxopt框架求解。首先,我们介绍下有线性约束的QP优化问题:
,
若定义:,上述约束条件通过广义不等号等价于:
。往后的教程,我们定义一个Magic Box:
, 视作我们计算出了该问题。
Proposition 4.3.3将(4.3.2)化成QP标准型:
至此,我们完成了最简单的hard-margin SVM算法的建模过程,并用QP问题能够解决。
5 算法总结Summury
以下截图摘自LFD(Learning from data):

TBD用cvxopt实现SVM的Jupyter notebook正在完工中,敬请期待
Acknowledgement
1. Learning from data: Yaser S. Abu-Mostafa, Malik Magdon-Ismail, and Hsuan-Tien Lin
2. 《人工智能简史》尼克