这篇论文产生sentence embedding的方法非常简单,但是效果并不差。整个方法完全避免了深度模型,个人认为在工业界会有好的前景。由于简单易操作,尽管过去一些论文自称为hard/tough-to-beat的baseline,作者仍然把它称为一个much harder-to-beat baseline。从实际效果看,此言不虚。
贡献
最简单的求sentence embedding的方法是对句子里所有的单词embeddings求平均,但是效果差,尤其是不能和复杂的模型比(比如第一篇文章介绍的InferSent)。在这篇文章里,作者把“对word embedding求平均”的操作泛化为p-mean的一类操作,进而推广到使用不同的p值产生不同的特征。
具体的,power-means定义为:
显然,当 时,它就是取平均的操作。另外,当 ,它是取最大(max)的操作,当 时,它是取最小值(min)的操作。作者实验了不同的 值,最终的结论是以上三种操作(平均最大和最小值)放在一起使用效果会非常好。
给定一个句子的word embeddings(假设有n个词,每个embedding有d维):
我们用 表示对其进行 p-means操作的结果。那么不同的 p-means操作的结果可以连接起来表达为:
这里 是连接符(concatenation), 是 K个不同的 power-mean 的 p值
仅仅对一种embedding采取不同的power-means还不够。作者使用了多种embeddings(Word2Vec,Glove等等),每一种embedding上都进行了power-means操作。把这些来自不同embedding spaces的
连接起来得到:
这个就叫做”Concatenated p-mean Word Embeddings”,作为一个多维度的向量,成为logistic regression的input。
实验结果
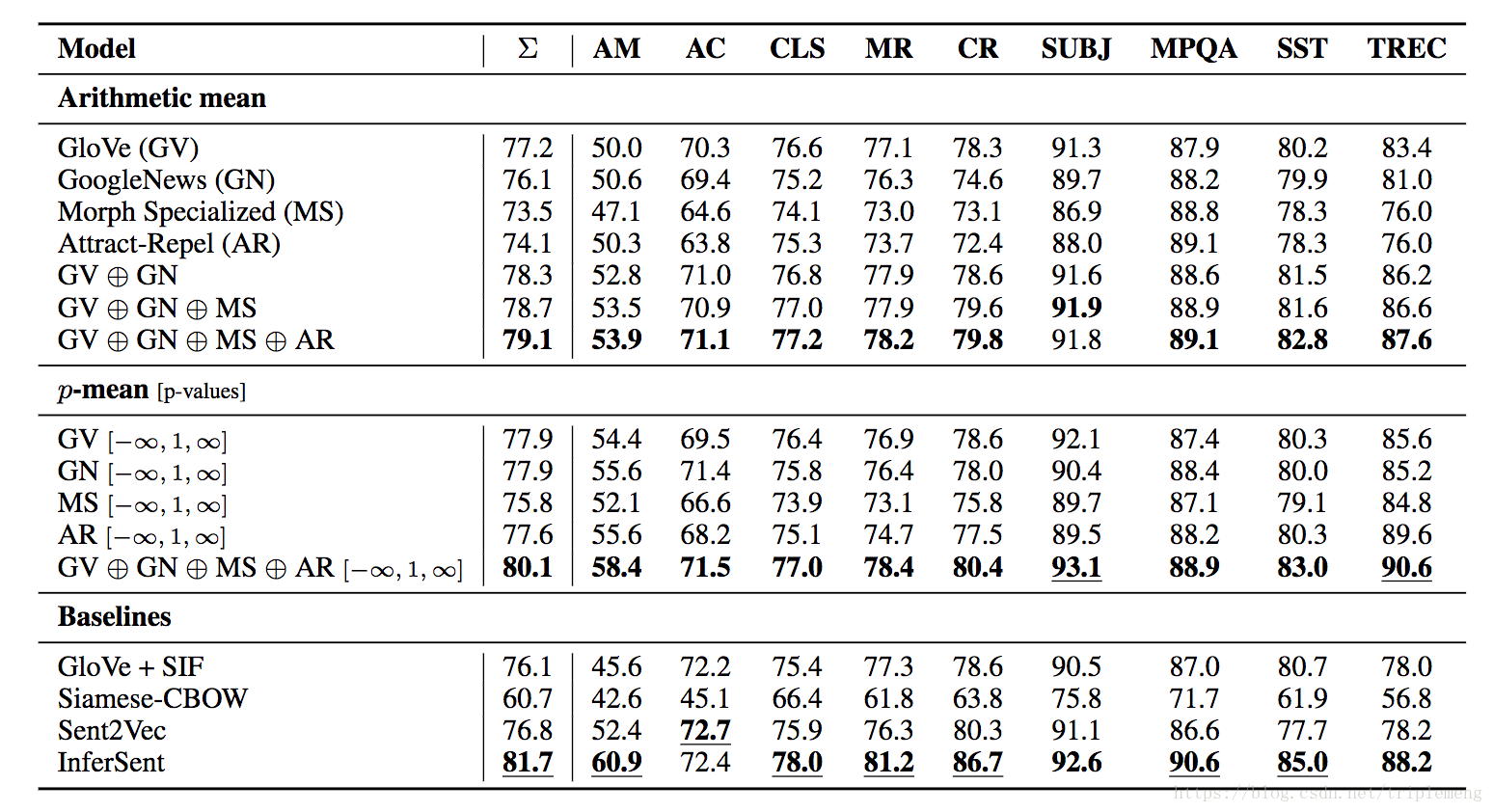
上图每一列代表不同的NLP的任务。为了和InferSent这样的经典工作对标,这些任务和InferSent的实验基本上一致的。第一列是各项任务的加权平均。实验中用到的算法主要分为三大类: 最简单的算术平均(即 ), (最大,最小,及平均),过去的经典算法(比如前文介绍过的SIF,InferSent等等)
从实验结果可以得到几个结论:
- 在第一类算法内部,很显然不同embeddings放在一起要好于单embedding,这个和过去的很多研究是一致的。有些深度学习的算法同时使用不同的embeddings并和CV类比的称为channels。显然不同的embeddings有互补的信息。
- 比较第一和第二类算法,显然不同的 值引入了更丰富的信息。直观上讲最大和最小值的确能提供最显著(数值上)的特征,这和过去的经验相符。当然,把1和2合并起来使用,则包含不同 值的不同embeddings串在一起时效果最好。
- 作为第三类算法,只有InferSent效果要略好于作者的算法。特别是其他的第三类算法综合表现都逊于第一类算法中的GloVe。
综上,作者自我标榜为hard-to-beat的baseline的说法是可以成立的。
另外作者还进行了Cross-lingual的实验,这里的效果比InferSent还要好。篇幅所限,这里略过。以后有空专门写一下cross-lingual。
关于
的取值带来的影响,如下图所示:
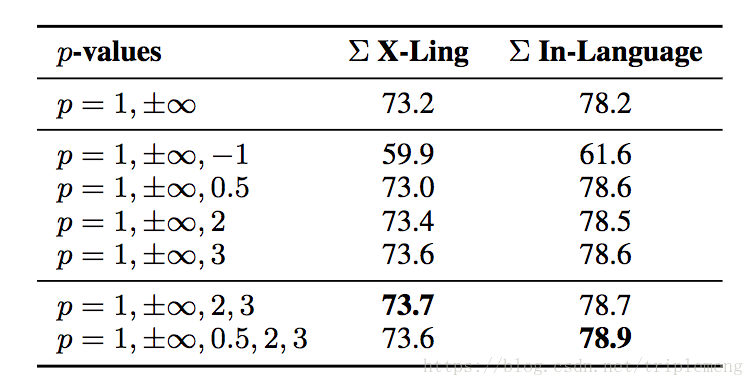
第二列是在Cross-lingual上的结果。第三列是在英语上的各任务的综合成绩。
注意
时算法受到了负面的影响。这说明只有额外提供了有用的,互补的信息的
值才有帮助。
时影响是正面的,其中
时边际效应最高。
分析
有实验结果就得有相应的分析。作者主要讨论了两点:
- 为什么把
连接起来有用?
显然不同的 值会提供不同的信息。平均值能够提供一些信息。但是不同的句子可以给出一样的平均值,这时给定max和min的值就能够限定句子里面embeddings的取值范围,减少了不确定性。 - 哪些
值会更有效?
大的 会很快的收敛到 和 。所以除了取最大和最小值之外,能够提供有用信息的 值一般较小。当 是整数时,奇数比偶数要更有用,因为偶数 值会丢失符号信息。另外 为正数时比负数时更好(比如以上实验中 带来了负效果)。
说下我个人的想法。这个工作的成功之处主要在于利用了两点。第一是利用了不同的embeddings的信息的互补。过去的研究常建议多个embeddings混用,这就是一个成功的例子。这些互补信息的embeddings直联以后增大了输入的维度,更加方便logistic regression去找到separating hyper-plane。 第二是利用了不同的简单操作。比如取平均是简单操作,取最大和最小值都是简单操作,多个简单操作放在一起(concatenation)就是复杂操作。这个复杂操作的结果就是对句子整体信息的有效压缩,可以看到这种做法成功了。
产生句子embedding的方法未必就非要经过LSTM和CNN之类的深度学习模型,这篇文章展示了不用深度模型也一样可以做好。在工业界,假设使用3种embeddings,每种就算300维,再利用平均,最大和最小对应的3种 值,总共的输入维度也就是 而已,这么一点维度对于熟练使用logistic regression算法的工业界根本就是小菜一碟。
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关计算机视觉
