ICCV-2017
摘要
本文提出了一种利用边缘信息的深度神经网络结构,用于处理具有代表性的底层视觉任务,如分层和图像滤波。与在此上下文中应用的大多数其他深度学习策略不同,我们的方法通过估算边缘和仅使用层叠的卷积层重构图像来解决这些具有挑战性的问题,这样就不需要手工制作或应用程序特定的图像处理组件。我们将得到的可转移管道应用于两个对边缘都敏感的问题域,即单个图像反射去除和图像平滑。对于前者,采用一种温和的反射平滑假设和一种新型的综合数据生成方法作为一种弱监督,我们的网络能够解决以前的方法无法处理的更困难的反射情况。对于后者,我们也在很大程度上超过了最先进的定量和定性结果。在所有情况下,建议的框架都是简单、快速和易于跨非对位域进行传输的。
Introduction
本文提出了一种级联边缘和图像学习网络(CEILNet),该网络可用于解决不同的图像处理任务,如分层(如反射去除)和图像滤波(如图像平滑)。我们依赖于通过特定于域的边缘信息在每个实例中专门化的覆盖泛型结构。核心框架以一种非常直观的方式运行。总之,我们将直接预测图像的困难任务分为两个子问题:(1)通过深度监督子网络预测目标图像的边缘映射,(2)然后利用预测的边缘映射重构目标图像。这些任务通过级联两个类似的简单CNNs来学习,不需要手工制作模块。对于任务特定的目标图像,边缘映射表示每对相邻像素之间的任何颜色差异,而不是像边缘检测问题那样的稀疏显著结构。
当然,这些目标需要大量的训练数据才能在实践中可行。对于图像平滑来说,如果有足够的计算资源可用于跨图像集产生滤波器输出,这并不是特别的问题。然而,对于许多分层任务来说,Ground-Truth实例是很少的。因此,我们提出了一种新的弱监督学习方法来训练我们的反射去除pipeline。这涉及到通过模拟自然场景的物理特性的反射来综合破坏图像的使用。
我们的贡献可以总结如下:
我们提出了一种新的、通用的级联边缘和图像学习网络(ated Edge and Image Learning Network, net),它仅依赖于卷积层,专门设计用于处理边缘敏感的图像处理任务,而不需要使用任何手工制作的、特定于应用程序的组件。这种结构快速、可扩展、易于复制,便于无缝转移到不同的低层次视觉问题。
我们是第一个使用深度学习技术解决从单个图像中去除反射的分层问题。提出了一种新的弱监督学习策略。
除了反射去除,我们在图像平滑任务中使用了CEILNet,展示了最先进的视觉和数值性能,在很大程度上超过了以前的方法。
Network Structure
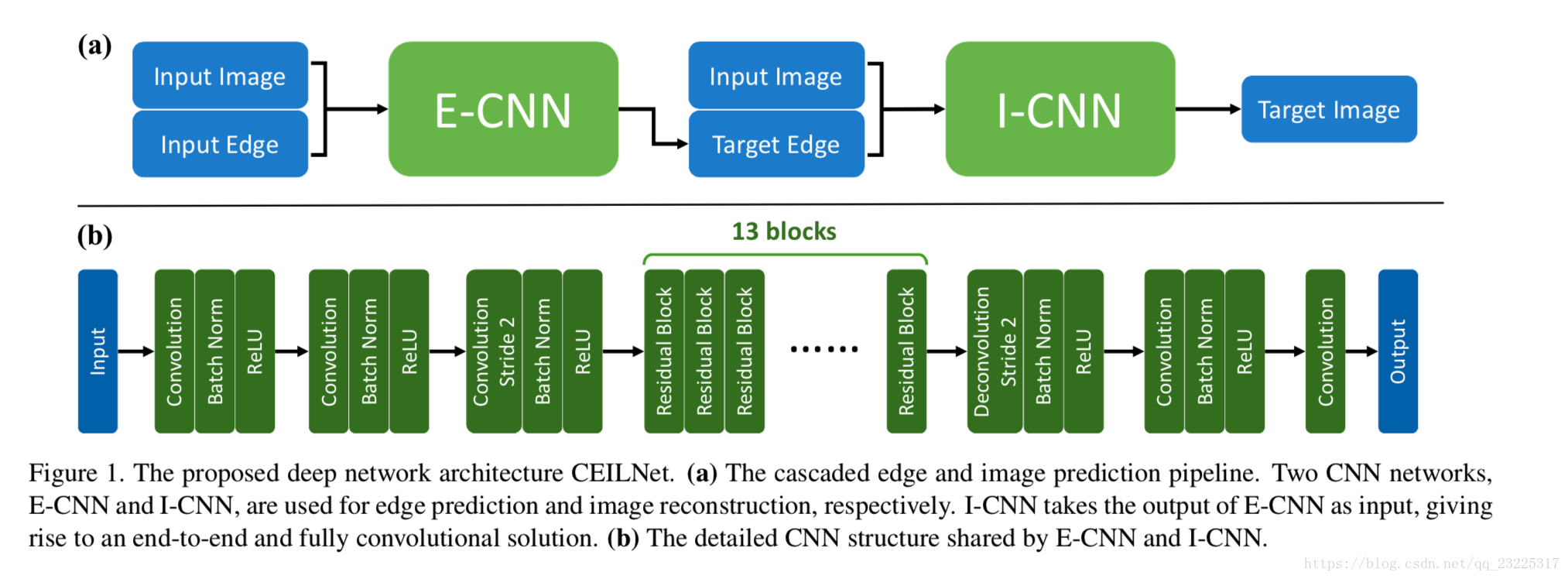
我们的网络由两个级联子网络组成:边缘预测网络E-CNN和图像重建网络I-CNN。图1是该体系结构的示意图描述,对于反射去除和图像平滑应用程序来说都没有变化。
Details of CNN Layers
为了简单起见,我们将如图1 (b)所示的深度CNN结构用于E-CNN和I-CNN。这两个子网络只在最终输出层的通道数上有所不同,即E-CNN输出一个通道(提取的边缘), I-CNN输出3个通道(生成的图像)。在每种情况下,我们采用32个卷积层,3×3卷积核(除了第三层;见下文)。中间的30个卷积层都有64维的输入和输出特征图。前31层由批处理标准化(BN)和ReLU组成。为了保证更好的上下文信息,我们降采样中间层到一半大小并且通过改变第三层卷积层的步长为2,将第三层最后一个卷积层换成反卷积层,步长为2,使用4x4卷积核。通过这种方法,有效地扩大了感知野,而不会丢失太多的图像细节,同时将计算成本减半。为了获得更好的性能和更快的收敛速度,我们将中间的26个卷积层实现为13个残差units。
Finally,解决颜色衰减问题[16,17],通过轻微的放大预测图像来实现,这种全局颜色校正是在I-CNN之后作为一个无参数层实现的。它的计算成本可以忽略不计。
Network Training
本节介绍训练pipeline,它独立于数据源。稍后我们将描述生成训练样本的特定于应用程序的方法。
在图像预测时,我们不仅最小化颜色差异,也最小化梯度差异。(MSE)梯度损失,虽然看起来是多余的,但是其有助于防止深度卷积网络产生模糊的图像。
Training Data Generation
Reflection Image Synthesis:具有ground-truth背景层的真实图像很难获得。为了生成足够的训练数据,简单地混合两幅不同系数的图像(比如背景系数为0.8,反射系数为0.2)似乎是一种直接可行的折衷方案。事实上,这一策略已经被广泛应用于以往的研究[34,29,12,23,41],用于分析和定量评价。然而,我们发现在这些图像上训练的网络对真实照片的泛化效果很差。因此,我们提出了一种新的合成方法来更好地近似真实世界的反射。
正如前面提到的,我们假设反射相对于背景层有点模糊,而背景层往往更清晰和清晰。对于许多情况,这是一个有效的假设,因为相机通常聚焦于背景目标。此外,摄影师可以很容易地扩大相机的光圈和模糊的反射。[23]使用了类似的假设。
我们用一个简单的补充观察来扩展这个假设。首先,根据菲涅耳方程,我们知道当入射光以不同折射率(例如,玻璃和空气)穿过感兴趣场景前的介质时,其中一部分光线将被反射回像平面。然而,这种反射光对人眼或摄像机的实际可见性取决于从背景场景传输的光的相对强度。因此,即使反射层在整个场景中都是均匀存在的,我们也可以预期只有部分背景层通过反射层来传输适度的光线,将会明显地被遮挡。然而,在反射明显的区域,它们的强度仍然可以任意地大(即使部分模糊),所以一个纯加性模型与弱比例反射分量在物理上并不总是合理的。
基于以上的观察,我们开发了一种新的方法来合成具有真实背景和反射层的图像,如图3所示。与初始图像混合的一个关键区别是,亮度溢出问题不是通过缩小亮度来避免的,而是通过减去自适应计算值后的裁剪来避免的。这样:(i)很可能出现与自然图像一致的无反射区域;(ii)在其他地方也可能出现强反射,(iii)反射对比度得到更好的保持。还要注意,我们随机选择高斯模糊的σ(2、5)之间的内核,与一个固定的较大的值(σ= 5)测试[23]。我们感兴趣的是处理范围更广的真实案例,包括那些反射不太模糊的案例。图6(顶部)显示了我们的方法生成的4个合成图像,图5显示了与初始图像混合的结果对比。有关合成过程的更多比较和细节,请参阅补充材料。

