CVPR-2018
摘要
我们提出了一种从单个图像中分离 reflction(镜像)的方法。该方法使用了一个经过训练的全卷积网络,利用低级和高级图像信息进行端到端损失训练。我们的损失函数包括两种感知损失:一种是通过视觉感知网络的特征损失,另一种是 transmission layers 的图像特征编码的对抗性损失。我们还提出了一种新的 exclusion loss,实现像素层级的强制分离。我们创建了现实世界中带有 reflection 的图像数据集和 对应的 ground-truth transmission layers 进行定量评估和模型训练。我们通过全面的定量实验验证了我们的方法,并表明我们的方法在PSNR、SSIM和感知用户研究中优于最先进的反射去除方法。我们还将我们的方法扩展到另外两个图像增强任务,以演示我们的方法的普遍性。
Introduction
在本文中,我们提出了一个具有感知损失的完全卷积网络,它既编码了低层次的图像信息,也编码了高层次的图像信息。我们的网络以一幅图像作为输入,直接生成两幅图像:the reflection layer and the transmission layer(反射层和投射层,即镜像和非镜像)。我们进一步提出了一种新的 exclusion loss,可以有效地在像素级别上实现透射和反射的分离。为了全面评估和训练不同的方法,我们构建了一个包含真实世界图像和地面真实透射图像的数据集。我们的数据集涵盖了各种自然环境,包括室内和室外场景。我们还使用这个真实世界的数据集来定量地比较我们的方法和以前的方法。总之,我们的主要贡献是:
提出了一种具有感知损失的深度神经网络用于图像的反射分离。我们通过两种不同层次的图像信息损失来进行感知监控:视觉感知网络的特征损失和输出-透射层的对抗性损失。
我们提出了一个精心设计的 exclusion loss,强调在梯度域中分离的层的独立性。(透射信息与反射信息不共享边缘)
我们建立了一个现实世界图像的数据集,包含反射信息的图像与相应的只含有透射信息的图像。这个新的数据集可以定量评估和比较我们的方法和现有的算法。
我们的反射分离训练模型可以直接应用于其他两项图像增强任务,除焰和除雾。
OverView
理想的反射分离模型应该能够理解图像中的内容。为了训练我们的网络f对输入图像的语义理解,我们从ImageNet数据集上预训练的VGG-19网络中提取特征,形成超列特征。使用超列特性的好处是,输入被增强为有用的特性,这些特性抽象了大型数据集(如ImageNet)的视觉感知。在给定像素位置上的超列特性是在该位置上网络的选定层之间的激活单元的堆栈。在这里,我们在预先训练的VGG-19网络中采样了层“conv1 2”、“conv2 2”、“conv3 2”、“conv4 2”和“conv5 2”。超列特征总共有1472个维度。我们将输入图像I和它的超列特征连接(concat)起来作为f的增广输入。
- 超列(双线性插值,concat)
input = tf.concat([tf.image.resize_bilinear(vgg19_f,(tf.shape(input)[1],tf.shape(input)[2]))/255.0,input], axis=3)我们的网络f是一个完全卷积的网络,我们的网络有一个很大的感知野 513×513 (膨胀卷积)可以有效地聚合全局图像信息。关于网络设计的理解
- 第一层的f是一个1×1卷积,将(1472 + 3)减少到64个通道。
net=slim.conv2d(input,channel,[1,1],rate=1,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv0')
- 以下8层3×3 膨胀卷积。所有中间层都有64个特征通道。
net=slim.conv2d(input,channel,[1,1],rate=1,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv0')
net=slim.conv2d(net,channel,[3,3],rate=1,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv1')
net=slim.conv2d(net,channel,[3,3],rate=2,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv2')
net=slim.conv2d(net,channel,[3,3],rate=4,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv3')
net=slim.conv2d(net,channel,[3,3],rate=8,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv4')
net=slim.conv2d(net,channel,[3,3],rate=16,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv5')
net=slim.conv2d(net,channel,[3,3],rate=32,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv6')
net=slim.conv2d(net,channel,[3,3],rate=64,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv7')
net=slim.conv2d(net,channel,[3,3],rate=1,activation_fn=lrelu,normalizer_fn=nm,weights_initializer=identity_initializer(),scope='g_conv8')- 最后一层是线性变换为 RGB 通道的两张图像即 transmission layer 和 reflection layer.
net=slim.conv2d(net,3*2,[1,1],rate=1,activation_fn=None,scope='g_conv_last')
# output 6 channels --> 3 for transmission layer and 3 for reflection layerTrain
使用特征损失来表示我们预测(生成)的透射图像与ground truth图像(预先准备的无反射图像)在特征空间中的差异。
特征损失(Feature Loss)主要的计算方式:
- 将生成的透射图像 transmission_layer 与target一起丢进VGG19的网络提取特征,紧接着计算他们之间的L1 Loss(计算’conv1 2’, ’conv2 2’, ’conv3 2’, ’conv4 2’, and ’conv5 2’的特征图差值,计算时不同层赋予不同的权重)。
p0=compute_l1_loss(vgg_real['input'],vgg_fake['input'])
p1=compute_l1_loss(vgg_real['conv1_2'],vgg_fake['conv1_2'])/2.6
p2=compute_l1_loss(vgg_real['conv2_2'],vgg_fake['conv2_2'])/4.8
p3=compute_l1_loss(vgg_real['conv3_2'],vgg_fake['conv3_2'])/3.7
p4=compute_l1_loss(vgg_real['conv4_2'],vgg_fake['conv4_2'])/5.6
p5=compute_l1_loss(vgg_real['conv5_2'],vgg_fake['conv5_2'])*10/1.5
return p0+p1+p2+p3+p4+p5笔者训练时没有用root_training_synthetic_data
loss_percep_t = compute_percep_loss(transmission_layer, target)Adversarial loss
这里其实可以类比pix2pix,与pix2pix中的判别器网络一致,基于条件GAN,与patchGAN,使得生成的折射层图像更像真正的无反射图像,其实可以理解为生成图像后的一个判真判假过程,使生成图像更像真的。
训练过程对损失函数作了优化,-logD代替log(1-D),避免梯度消失。
# Adversarial Loss
with tf.variable_scope("discriminator"):
predict_real,pred_real_dict = build_discriminator(input,target)
with tf.variable_scope("discriminator", reuse=True):
predict_fake,pred_fake_dict = build_discriminator(input,transmission_layer)
d_loss=(tf.reduce_mean(-(tf.log(predict_real + EPS) + tf.log(1 - predict_fake + EPS)))) * 0.5
g_loss=tf.reduce_mean(-tf.log(predict_fake + EPS))Exclusion loss
为了更好的分离transmission layer和reflection layer,这个损失是关键的。因为这两者不共享边缘,我们的任务就是要使得这两者在梯度域上的相关性最小。
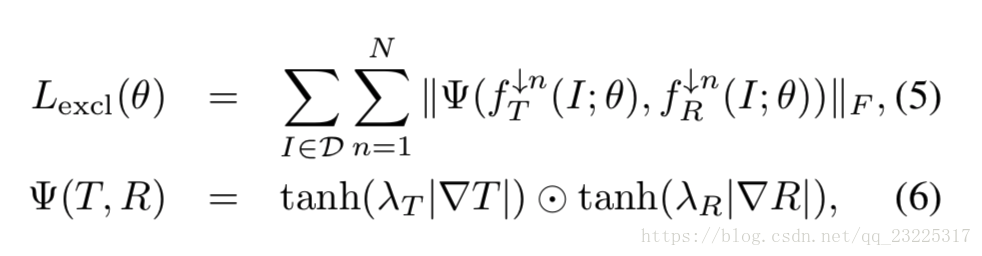
where λT and λR are normalization factors, ∥ · ∥F is the Frobenius norm, ⊙ denotes element-wise multiplication,and n is the image downsampling factor: the images fT and fR are downsampled by a factor of 2^(n−1) with bilinear interpolation.
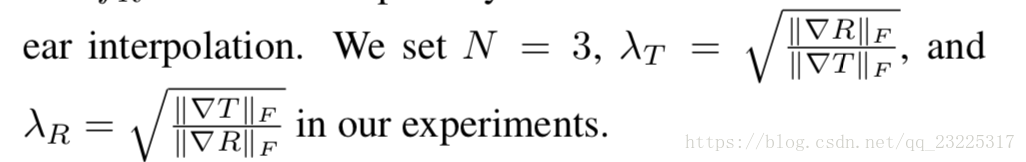
注意正则化因子λT和λR方程中至关重要,由于传输和反射层可能包含不平衡梯度大小。反射层可以是低强度的模糊,由小的梯度组成,也可以反射非常明亮的光,组成图像中最亮的点,产生高对比度反射,从而形成大的梯度。规模差异|∇T |和|∇R |两层预测会导致不平衡的更新。我们观察到,如果没有适当的归一化因子,网络会抑制梯度更新率较小的层,使其接近于零。
# Gradient loss
loss_gradx,loss_grady=compute_exclusion_loss(transmission_layer,reflection_layer,level=3)
loss_gradxy=tf.reduce_sum(sum(loss_gradx)/3.)+tf.reduce_sum(sum(loss_grady)/3.)总的loss
loss=loss_l1_r+loss_percep*0.2+loss_grad