逻辑回归是用于分类的算法。
平常的线性回归方程为f(x)=wx+b,此时f(x)的取值可以是任意的,要让预测的值可以分类,例如分类到class1是预测值为1,分类到class2时预测值为0。这时我们就要用到分类函数。
下面来介绍一个分类函数sigmoid:
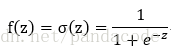
其中z=wx+b
f(z)的取值将在0与1之间,如下图

有:

设f(z)表示分类到class1是的概率,则分类到class2的概率为1-f(z)。
假设我们有如下数据集:
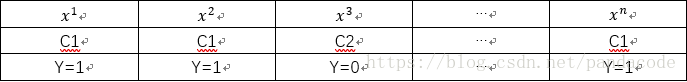
最大似然的意义是表示出现这组数据最大可能性。
由最大释然估计可得
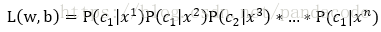
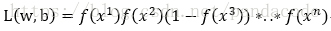
即求L(w,b)最大时的w和b的值
也就是求-ln(L(w,b))最小值时,w和b的值

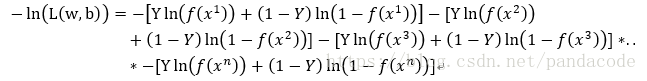
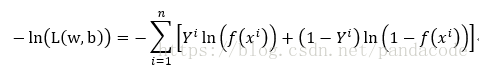
以下为上述公式的代码实现
cross_entropy = -1 * (np.dot(np.squeeze(Y), np.log(y)) + np.dot((1 - np.squeeze(Y)), np.log(1 - y)))求偏导可得:
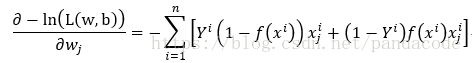
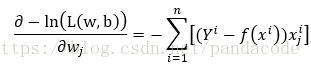
以下为上述求偏导的代码实现
w_grad = np.sum(-1 * X * (np.squeeze(Y) - y).reshape((batch_size,1)), axis=0)
b_grad = np.sum(-1 * (np.squeeze(Y) - y))可用梯度下降法求得目标函数最低时的w和b的值
以下为逻辑回归案例代码实现收入分类。
import os, sys
import numpy as np
from random import shuffle
from math import log, floor
import pandas as pd
#此函数用于加载训练和测试数据
def load_data(train_data_path, train_label_path, test_data_path):
X_train = pd.read_csv(train_data_path, sep=',', header=0)
X_train = np.array(X_train.values)
Y_train = pd.read_csv(train_label_path, sep=',', header=0)
Y_train = np.array(Y_train.values)
X_test = pd.read_csv(test_data_path, sep=',', header=0)
X_test = np.array(X_test.values)
return (X_train, Y_train, X_test)
#此函数用于打乱训练数据的排序
def _shuffle(X, Y):
randomize = np.arange(len(X))
np.random.shuffle(randomize)
return (X[randomize], Y[randomize])
#此函数用于将训练和测试数据特征归一化
def normalize(X_all, X_test):
#将训练集与测试集合并后归一化
X_train_test = np.concatenate((X_all, X_test))
mu = (sum(X_train_test) / X_train_test.shape[0])
sigma = np.std(X_train_test, axis=0)
mu = np.tile(mu, (X_train_test.shape[0], 1))
sigma = np.tile(sigma, (X_train_test.shape[0], 1))
X_train_test_normed = (X_train_test - mu) / sigma
# 归一化后将数据从新分为训练集和测试集
X_all = X_train_test_normed[0:X_all.shape[0]]
X_test = X_train_test_normed[X_all.shape[0]:]
return X_all, X_test
#此函数用于将训练集划分为要使用的训练集和用于选择模型的训练集
def split_valid_set(X_all, Y_all, percentage):
all_data_size = len(X_all)
valid_data_size = int(floor(all_data_size * percentage))
X_all, Y_all = _shuffle(X_all, Y_all)
X_train, Y_train = X_all[0:valid_data_size], Y_all[0:valid_data_size]
X_valid, Y_valid = X_all[valid_data_size:], Y_all[valid_data_size:]
return X_train, Y_train, X_valid, Y_valid
#定义sigmoid函数
def sigmoid(z):
res = 1 / (1.0 + np.exp(-z))
return np.clip(res, 1e-8, 1-(1e-8))
#验证模型的正确性
def valid(w, b, X_valid, Y_valid):
valid_data_size = len(X_valid)
z = (np.dot(X_valid, np.transpose(w)) + b)
y = sigmoid(z)
y_ = np.around(y)
result = (np.squeeze(Y_valid) == y_)
print('Validation acc = %f' % (float(result.sum()) / valid_data_size))
return
def train(X_all, Y_all, save_dir):
#划分0.1的训练集用于挑选模型
valid_set_percentage = 0.1
X_train, Y_train, X_valid, Y_valid = split_valid_set(X_all, Y_all, valid_set_percentage)
# 创建原始参数,设定学习速率、训练次数、每次训练用多少数据
w = np.zeros((106,))
b = np.zeros((1,))
l_rate = 0.1
batch_size = 32
train_data_size = len(X_train)
step_num = int(floor(train_data_size / batch_size))
epoch_num = 1000
save_param_iter = 50
total_loss = 0.0
#开始训练
for epoch in range(1, epoch_num):
# 模型验证与保存参数
if (epoch) % save_param_iter == 0:
print('=====Saving Param at epoch %d=====' % epoch)
if not os.path.exists(save_dir):
os.mkdir(save_dir)
np.savetxt(os.path.join(save_dir, 'w'), w)
np.savetxt(os.path.join(save_dir, 'b'), [b,])
print('epoch avg loss = %f' % (total_loss / (float(save_param_iter) * train_data_size)))
total_loss = 0.0
valid(w, b, X_valid, Y_valid)
#将训练集随机打乱
X_train, Y_train = _shuffle(X_train, Y_train)
# 每batch_size个数据为一组训练
for idx in range(step_num):
X = X_train[idx*batch_size:(idx+1)*batch_size]
Y = Y_train[idx*batch_size:(idx+1)*batch_size]
z = np.dot(X, np.transpose(w)) + b
y = sigmoid(z)
cross_entropy = -1 * (np.dot(np.squeeze(Y), np.log(y)) + np.dot((1 - np.squeeze(Y)), np.log(1 - y)))
total_loss += cross_entropy
w_grad = np.sum(-1 * X * (np.squeeze(Y) - y).reshape((batch_size,1)), axis=0)
b_grad = np.sum(-1 * (np.squeeze(Y) - y))
# 梯度下降迭代参数
w = w - l_rate * w_grad
b = b - l_rate * b_grad
return
#输入测试数据并输出测试结果
def infer(X_test, save_dir, output_dir):
test_data_size = len(X_test)
# 加载所得结果参数w和b
print('=====Loading Param from %s=====' % save_dir)
w = np.loadtxt(os.path.join(save_dir, 'w'))
b = np.loadtxt(os.path.join(save_dir, 'b'))
# 将w和b与测试集代入函数求得预测值
z = (np.dot(X_test, np.transpose(w)) + b)
y = sigmoid(z)
y_ = np.around(y)
print('=====Write output to %s =====' % output_dir)
if not os.path.exists(output_dir):
os.mkdir(output_dir)
output_path = os.path.join(output_dir, 'log_prediction.csv')
with open(output_path, 'w') as f:
f.write('id,label\n')
for i, v in enumerate(y_):
f.write('%d,%d\n' %(i+1, v))
return
#主函数
def main():
# Load feature and label
X_all, Y_all, X_test = load_data('E:\\kaggle\\income prediction\\X_train', 'E:\\kaggle\\income prediction\\Y_train', 'E:\\kaggle\\income prediction\\X_test')
# Normalization
X_all, X_test = normalize(X_all, X_test)
# To train or to infer
train(X_all, Y_all, 'E:\\kaggle\\income prediction')
infer(X_test, 'E:\\kaggle\\income prediction', 'E:\\kaggle\\income prediction')
return