线性回归的目标是确定一条直线,让所有样本点到这一条直线的距离之和最小。通过这一句话我们就可以自然而然地根据样本点列出目标函数
现在我们有一组高维样本点 (其中每一个x都是m维列向量)。
我们设目标直线方程为 y = (这个等式里面全是单个数字没有向量)
把这个方程写作向量的形式 y = (其中X是m+1维的列向量,W也是)
(对于
是在每一个n维样本点的首位补充了一个1形成的m+1维的向量) 这个式子表示n个样本点到目标直线的距离之和。此处的方程就是线性回归的损失函数。
接下来我们就要最小化损失函数来求取未知量 W 对于方程 我们可以得知他存在一个全局最小值(具体证明请自行百度)
所以方程导数为0处必定是全局最小值处。 可以得到等式 下面对方程进行变换
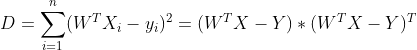
(其中的X为(m+1)*n的矩阵。
每一列为一个样本。
)
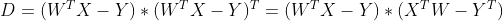
(因为是一个常数,所以
=
)
(这里需要用到矩阵求导的知识,下面给出常用的公式)
由
得
则
但是这个等式成立的条件是
必须可逆。即给定的样本集中不能出现重复数据,样本特征数量不能大于所给训练集样本个数。
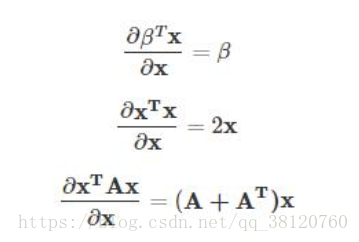
利用最大似然估计推导出损失函数
首先给定一个先验假设,样本真实值与预测值的差值服从
的正态分布
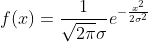
对于连续性随机变量,其在某一点处的概率可以表示为
(f(x) 为随机变量的概率密度函数 dx代表x轴上的微分)
所以样本的联合概率为
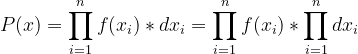
由于
近似常量,所以对于 P(x) 求极值没有影响。所以 可以写作
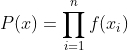
(由于
和
是常量所以在求
时无影响可以去掉 )
(此时就得到了上述的损失函数)