通过索引对数据操作:
上一篇介绍了关于pandas中Series对象和DataFrame对象的基本概念,现在来介绍一下通过索引对这两个对象的基本操作,首先咱们看一下Series的基本操作:
Series赋值:
在series中改变数据就像给列表或者字典重新赋值一样,都是通过索引然后等号,写上想要改变的值:
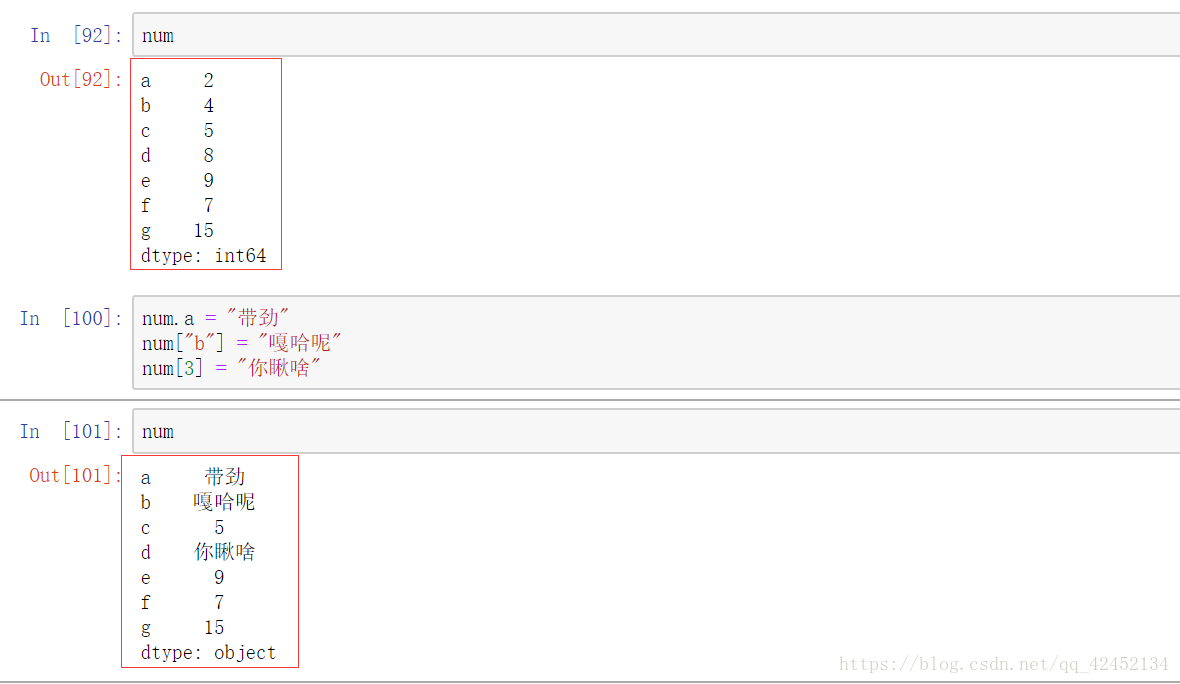
上图所示,在Series对象中 可以通过[索引] = 的方式改变该索引下的数据,也可以用过.+设定的字符类型的索引来更改对应的值,这个.+索引不可以直接用默认的数字索引。
DataFrame索引:
在dataframe里面他也可以通过索引的方式来修改或提取数据:
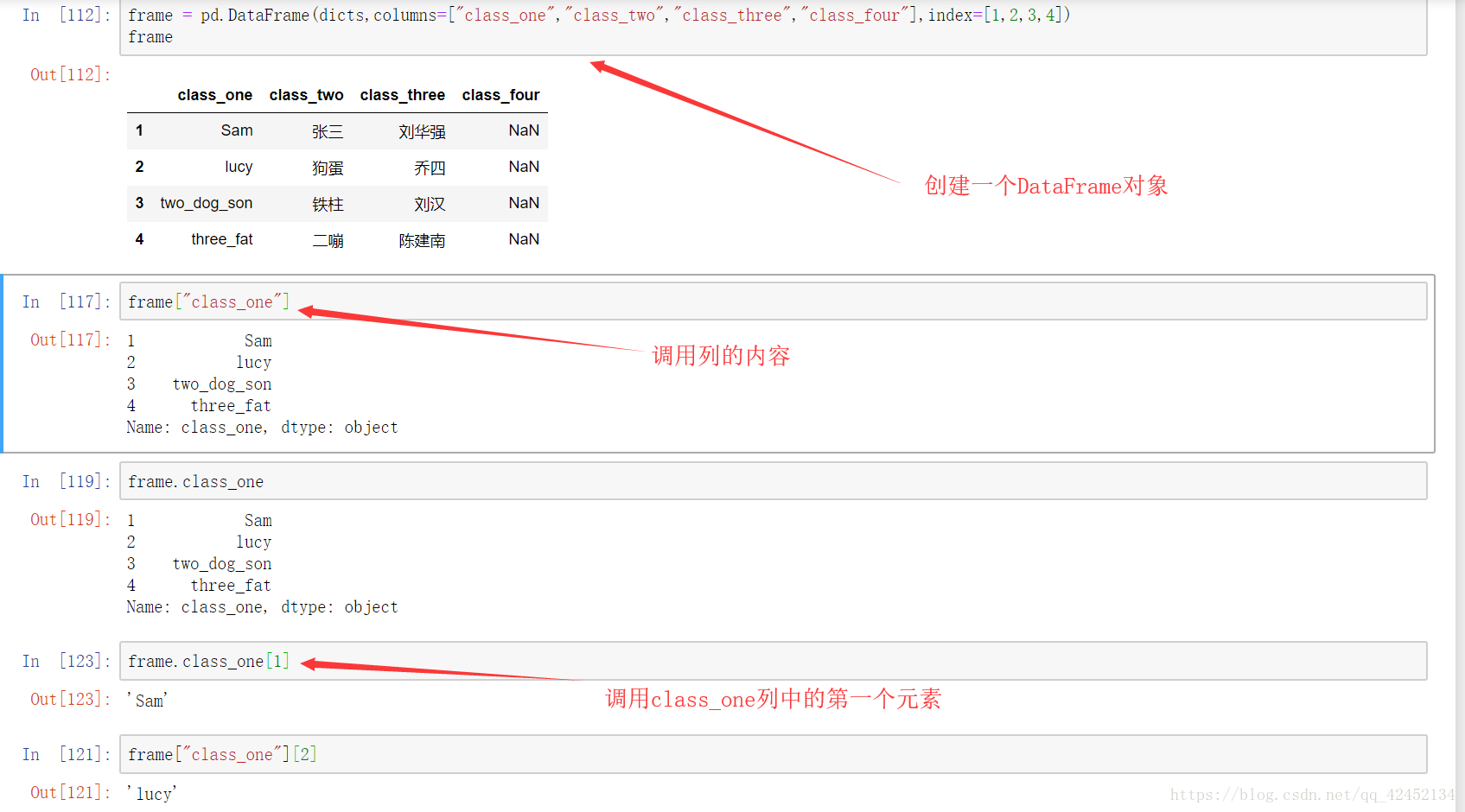
在dataframe中所用索引会和series稍有不同,在这里,dataframe对象后面第一个默认的索引是列,如果想精确到某个值,第二个索引是行索引,在这里行索引要与dataframe列表里面定义的一致才可以,不可以用默认的0起始的索引,除非你没有定义它,让它默认产生。。
如果你想要提取一行的数据的话,也是可以的调用.ix的方法就能做到:
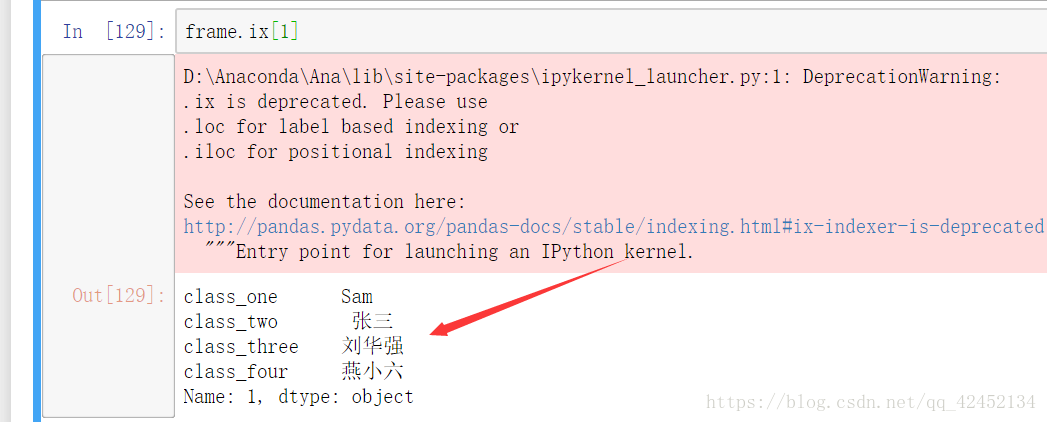
在图中红色的地方不是报错,不需要担心,通过.ix的方法然后直接加上索引就得到了咱们想要的内容,我们想要的是第一行的所有数据,在这里直接提取了第一行的数据,并自动以列作为索引出现了左侧,如果你想要精确的找出某个数据,可以在后面再加上列的索引。
Dataframe通过索引赋值:
当你想要给dataframe里面的数据修改的时候,通过索引也可以进行修改:
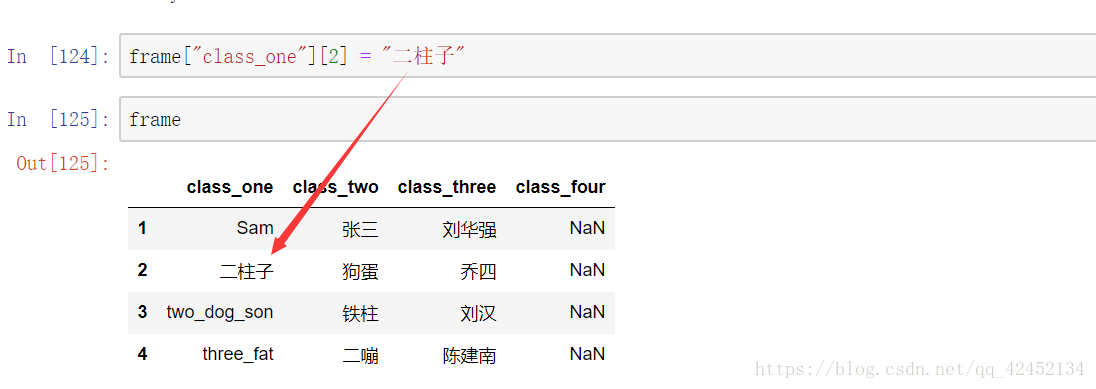
有一点咱们要特别的注意,如果你就调用的列索引而没有精确到某个位置的话,你赋值会把这列的数据都改了。
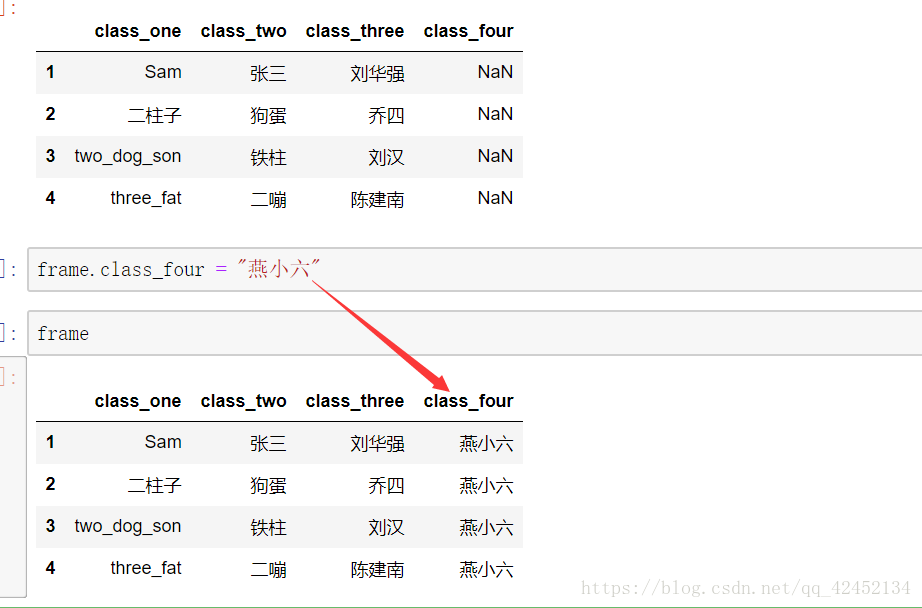
如果你想给一个数组批量附上相应的值,也是可以的:
比如我们把燕小六改成1,2,3,4:
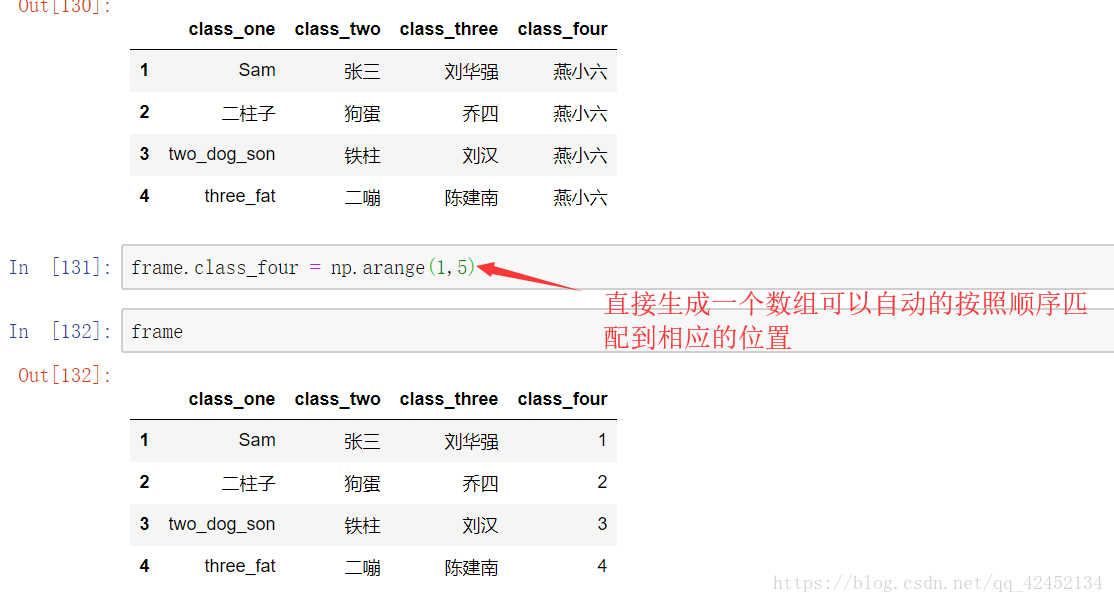
我们直接对dataframe批量修改数据的时候要注意元素的长度要对齐,直接用这种方式赋值多一个或者少一个都会报错,这时候我们用series对象给dataframe对象批量修改数据的时候就很方便了,即便是少数据,dataframe也会默认用空值把它填补上:
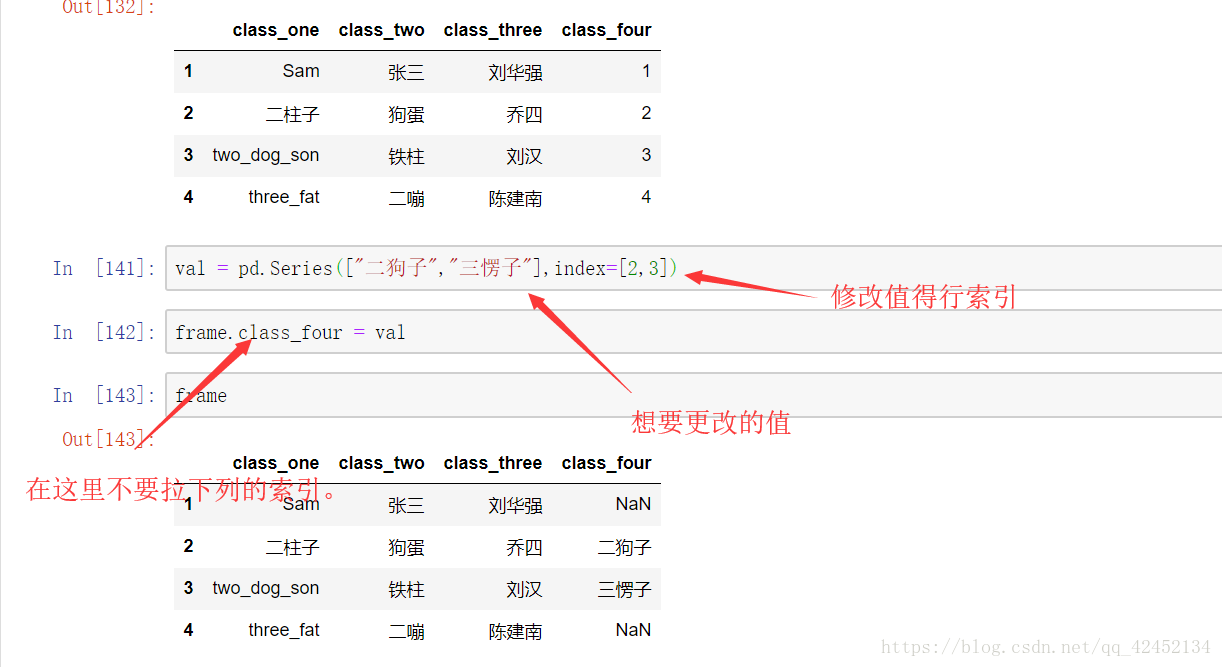
这里我们发现之前的 第1行 和第 4行的数据被NaN覆盖掉了,我们要注意一下,用series给该列赋值的时候如果没有填写上相应的数据,那么没有数据覆盖的地方会自动被NaN覆盖。
如果你想给dataframe对象添加一个新列的时候,咱们可以通过这种方法来操作:

通过这种方式可以直接给dataframe对象添加一个新的列。
Dataframe的转置:
dataframe转置与excel表格中的转置是一样效果的,其实就是行索引变为了列索引,列索引变成了行索引,当然,行索引和列索引互换的同时里面的数据也会相应的进行变换,最后保持数据的一致性。
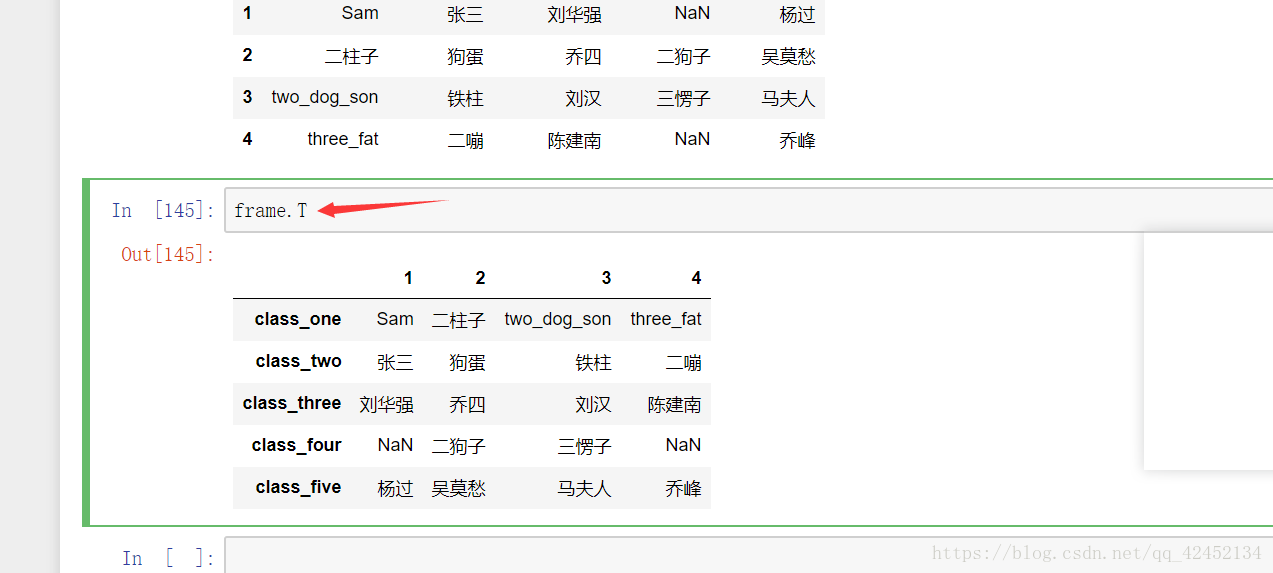
转置的操作很简单吧,就是.T注意T是大写的。
这一节完事了,希望大家喜欢。