import numpy as np
import pandas as pd
Series的索引操作
1.可以使用自定义的索引值,添加index参数
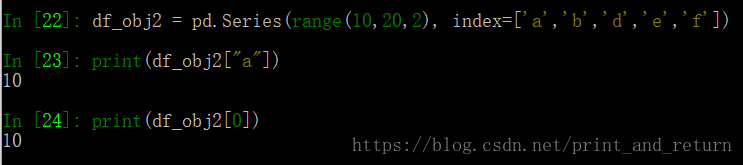
可以发现其实加了自定义索引之后既可以通过新索引来定位元素,也可以通过原来的下标定位
2.根据索引进行切片
可以发现,使用索引下标进行索引切片的时候结束位是不包含的,使用自定义索引的话结束位是包含的

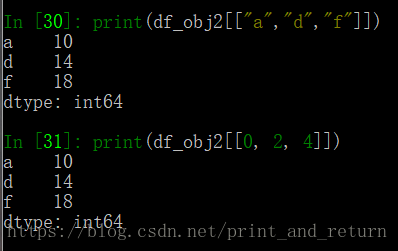
3. 不连续索引取值
参数是一个列表,包含了需要取值的索引下标或者索引名
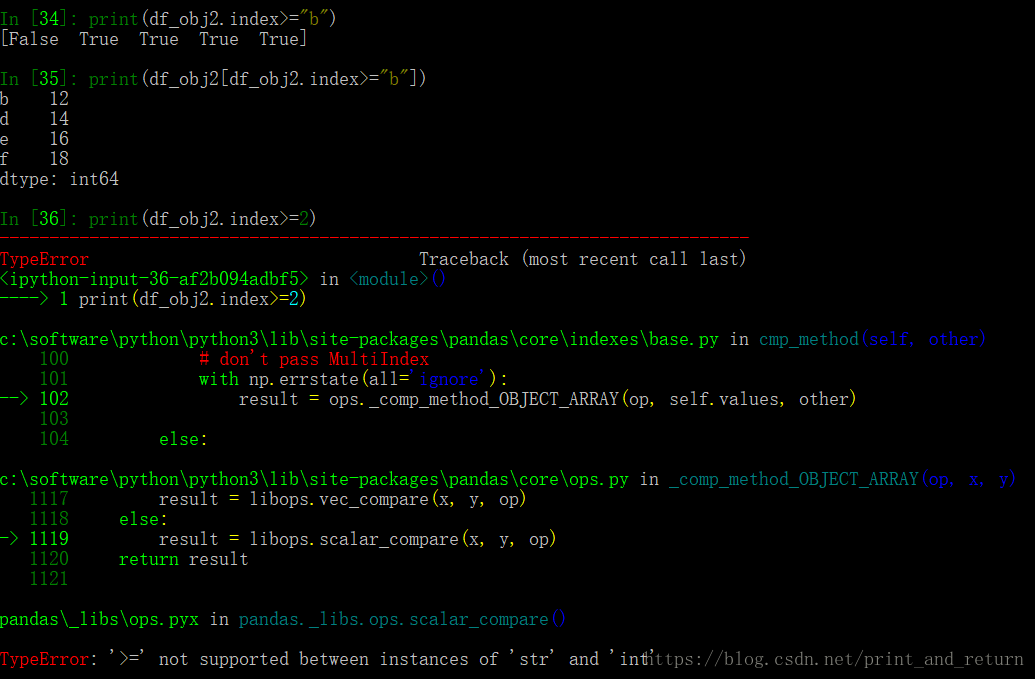
4.布尔索引
通过值进行判断
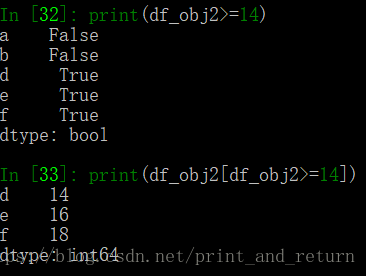
也可以通过索引进行判断,但是如果有了索引名了,就只能用索引名来判断,不能用索引下标,否则会报错
DataFrame的索引操作
新建DataFrame类型数据,index指定行索引的行名,columns指定列索引的列名

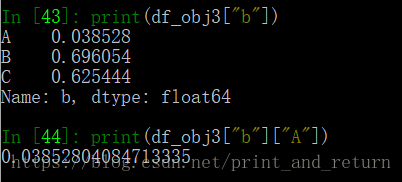
1.通过索引取值
先取列索引,每一列都是一个Series对象,再取行索引,就可以取到需要的值
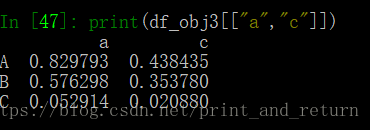
2.DataFrame的不连续索引
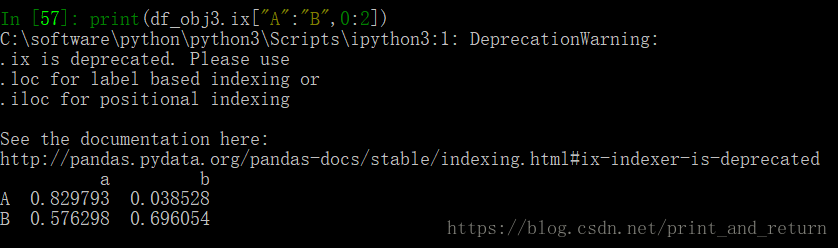
3.DataFrame的高级索引 loc, iloc, ix
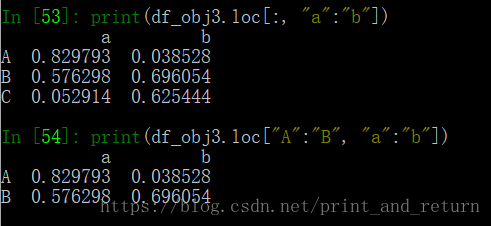
loc:DataFrame对象默认不支持切片索引取值,所以要用loc高级索引
loc:根据自定义的索引进行切片(包含两个参数:第一个 行的切片索引,第二个是列的切片索引)
注意:和Series切片一样的是,一旦是通过索引名进行切片,结束位会被包含
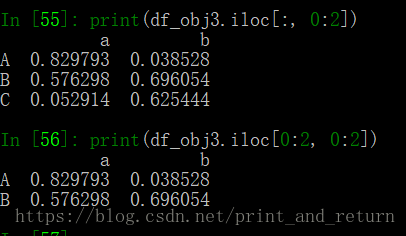
iloc:根据索引下标来做切片索引(也包含两个参数:第一个是行的索引下标切片,第二个是列的索引下标切片)
通过下标切片时,结束位是不被包含的
ix:混合索引--既可以用下标,也可以用索引名
但是会有提示不推荐使用ix,建议使用loc和iloc