一些别人总结的Faster R-CNN后续改进:
[目标检测] Faster R-CNN 深入理解 && 改进方法汇总
Faster R-CNN改进篇(一): ION ● HyperNet ● MS CNN
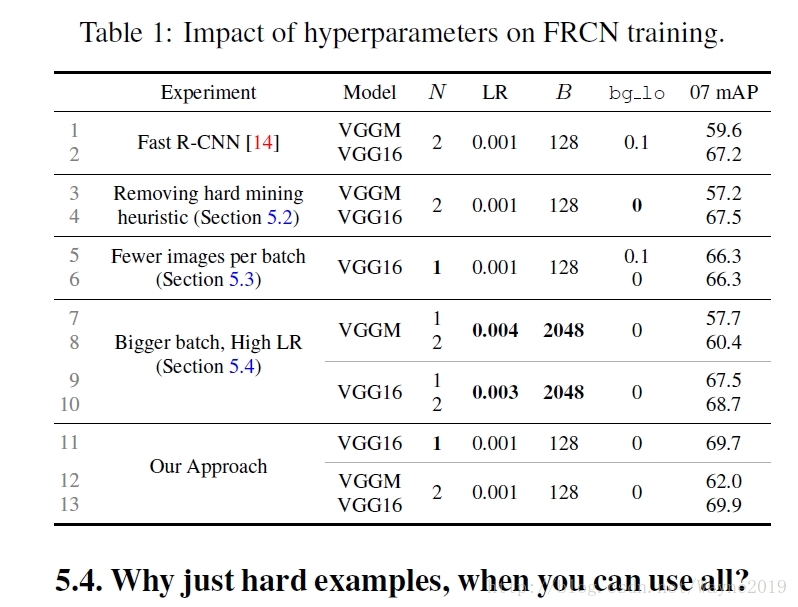
Training Region-based Object Detectors with Online Hard Example Mining
最好先阅读之前博文: Tensorflow object detection API 源码阅读笔记:RPN
- 知乎文章中ProposalTargetCreator从2000/300候选中选择一部分(比如128个)pooling出来用以训练Fast
R-CNN,对应: 不使用hard_example_miner
_unpad_proposals_and_sample_box_classifier_batch second_stage_batch_size=64
这里的正负样本比例1:3很重要。OHEM就是为了消除掉这个超参数,做法和triplet loss文章中经常见到的思路差不多(比如只选取一个batch中最难的作为负样本啥的)。
如果使用了hard_example_miner,则在_postprocess_rpn函数中保留first_stage_max_proposals=300个RoIs,即上述ProposalTargetCreator不再按1:3的比例sample出64或128个正负样本,而是将ProposalCreator中NMS得到的全部RoIs都放过去。paper中NMS阈值是0.7,与tf中的配置相同。
_loss_box_classifier调用_unpad_proposals_and_apply_hard_mining,进行难样本挖掘。具体实现在losses.HardExampleMiner。
看起来实现的是paper中说的直观方案,即先计算所有RoIs的损失函数值,然后排序,选择难样本,将不是难样本的loss重置为0。paper中说这部分在BP时还是要占据显存和计算量,inefficient。但是在tf实现中,就是计算标量loss时只对选出的难样本求和,这样其实没被选中的loss不会参与BP。
"""
losses.HardExampleMiner
排序,选择num_hard_examples个难样本。 a newly selected region cannot have an IOU > iou_threshold with any of the previously selected regions
"""
selected_indices = tf.image.non_max_suppression(
box_locations, image_losses, num_hard_examples,
self._iou_threshold)思考: hard example mining为啥会使得精度提升(相比于启发式的sample和使用全部RoIs进行BP)?
OHEM的后续改进: https://zhuanlan.zhihu.com/p/28202204(S-OHEM等)
In Defense of the Triplet Loss for Person Re-Identification
更好的理解难样本(回想猪识别竞赛):
在triplet loss训练中,三元组组合数太多,不挖掘难样本则效率太低;只挖掘最困难样本可能会受噪声影响较大;所以挖掘中等难度,如Batch Hard。实现都比较简单。
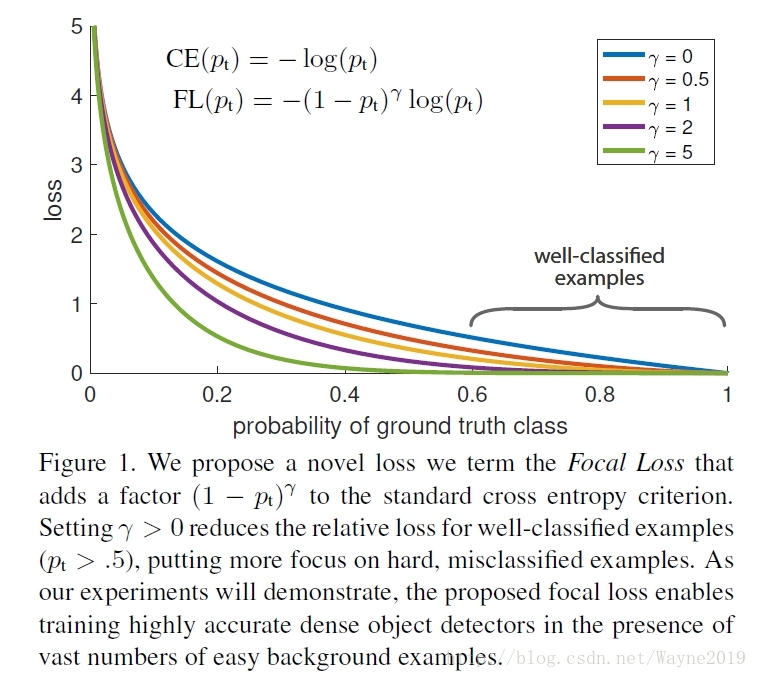
Focal Loss for Dense Object Detection
备受关注的文章:如何评价kaiming的Focal Loss for Dense Object Detection?
RetinaNet啥的先不管了,这篇主要看和OHEM的联系。
文章指出Single stage detector精度问题在于easy example dominant。Focal Loss可以看作是sort OHEM: