为了解决在图像合成时候小物体容易消失,大物体经常作为块的拼接来生成的。本文提出DP-GAN在所有尺度下共同学习空间自适应归一化模块的条件。这样尺度信息就会被双向使用,他统一了不同尺度的监督。(重点看图和代码)
SPADE模块解释
GAN在生成包含许多不同物体的复杂场景时非常具有挑战,由于归一化的存在,分割图会退化。SPADE(《Semantic Image Synthesis with Spatially-Adaptive Normalization》)通过正向传递语义信息来解决上述问题。大多数的网络将标签作为输入,然后做一个全局的判别。因为一个全局的辨别器不会强迫生成器去学习和输入的语义标签图进行准确的对齐。
本文旨在从语义图不同的尺度生成类似真实的物体。这需要解决生成器和辨别器不同的图片尺寸问题。我们通过一个金字塔来使用每个尺度。
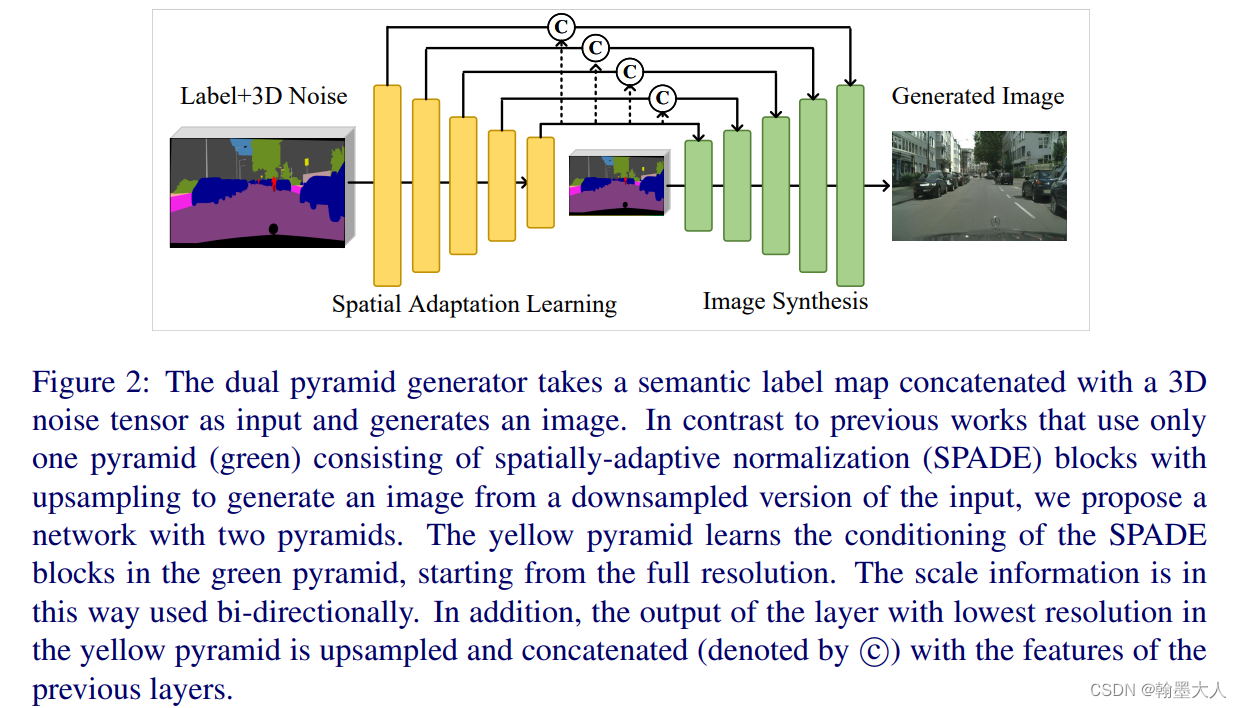
为了解决细小物体退化问题,我们在不同尺度引入了多尺度监督的不同类型。第一个是多尺度特征匹配损失,他鼓励生成器在所有尺度生成和语义图对齐的图片,第二个是在每一个块使用多尺度对抗监督。他鼓励在辨别器时重要的尺度信息可以保留。
总结:1:提出一个双金字塔生成器用于语义图像合成。2:在像素,块,特征三个层面促使生成器生成和语义图对齐的真实的物体。
方法:
双金字塔生成器,一个金字塔用于图像合成,另一个用于空间适应学习。生成器输入是标签图和3D噪声的逐通道拼接。不同的噪声可以产生不同风格的图片。

SPADE实现过程:

在本文公式:

在原始SPADE中,γ和β是特征图经过卷积学习到的。在本文类似但是做了修改,修改的原因是特征图经过下采样,细小的物体已经消失,就会在不同尺度带来大量的冗余信息。作者将最后一层的输出上采样到之前层的大小,然后和原始的每一层输出相加再进过卷积。通过在不同尺度进行SPADE的学习,这样生成的结果就会更加的真实。

尺度增强辨别器:
使用一个包含resnet的编码解码结构,模型预测N+1个类别,N是语义类别数,1是假的类别。在训练时候,对于真实图片每一个像素都是由输入标签图定义,对于生成图片每一个像素都是由假类别定义。这样一个N+1类别交叉熵可以定义为:

逐像素的损失不够,我们还添加了另外两个损失。第一个是基于块的多尺度对抗损失,应用于低分辨率的特征图:

第二个是多尺度特征匹配损失,在真实图和预测图之间使用L2损失,用于训练生成器。


训练:
对于生成器使用损失:
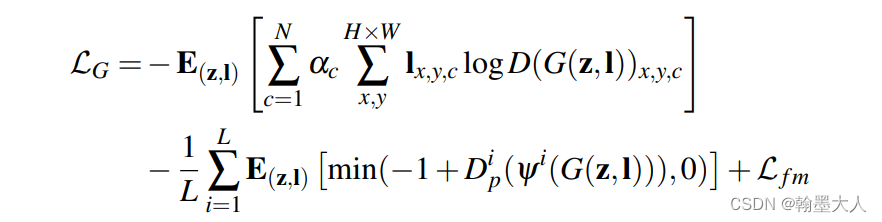
正则化:
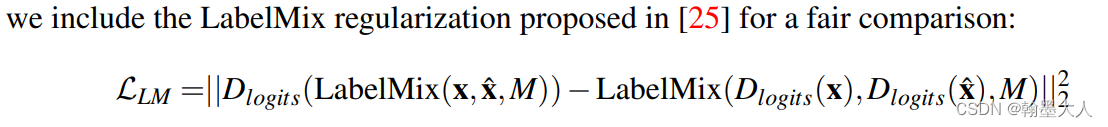
总损失:
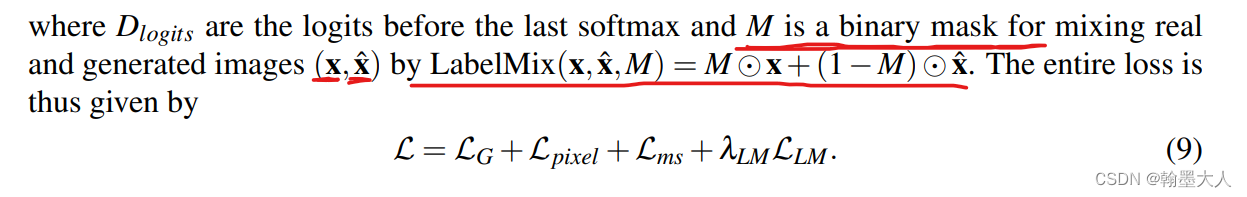
**实验:**使用mIoU和FID进行评估。
Dual pyramid GAN for semantic image synthesis
猜你喜欢
转载自blog.csdn.net/qq_43733107/article/details/132004632
今日推荐
周排行