there are a couple of ways to work with spark:
spark-shell and spark application
打开
spark-shell 在不同语言下的方式
scala
bin/spark-shell
python
bin/pyspark
R
bin/sparkR
以scala版本的spark-shell 举例:
可以通过执行一个命令文件的方式来执行一段程序,这一点redis也有类似的操作
有两种方式
bin/spark-shell -i aa.txt 这种方式在执行完了aa.txt中的程序后会进入spark-shell的交互模式
或
cat aa.txt | bin/spark-shell 这种方式在执行完aa.txt的程序后就退出spark-shell的交互模式
aa.txt 内程序命令的编写实例:
import sys.process._
val res = "ls /tmp" ! //注意本地文件 用 !
println("result = "+ res)
import sys.process._
val output = "hadoop fs -ls" !! //注意hdfs文件用!!
println("result= "+output)
spark application
spark application are used for creating and sheduling large scale data processing applictions in production
spark-submit is used for submitting a spark application as shown in the following Scala-based appliction example:
spark-submit -- class com.example.log.MyApp --master yarn --name "myapp" --executor-memory 2G --num-executors 50 --conf spark-shuffle.spill=false myApp.jar /data/input /data/output
python 版本
spark-submit --master yarn-client myapp.py
RDD
创建RDD的方法一:parallelizing a collection
val myRDD = sc.parallelize(List("hdfs","spark","rdd"))
创建RDD的方法二:reading from a file
val inputRDD = sc.textFile("/path/to/input") //本地路径,否则的话要配置好hdfs,才表示是hdfs上的路
从HDFS创建RDD
val inputRDD = sc.textFile("hdfs://namenodehostname:8020/data/input")
如果已经在spark-env.sh中配置了 HADOOP_CONF_DIR的环境变量
val inputRDD = sc.textFile("/data/input")
sparkContext.textFile calls org.apache.hadoop.mapred.FileInputFormat.getSplits which in turn uses org.apache.hadoop.fs.getDefaultUri . This method reads the fs.defaultFS parameter of Hadoop conf(core-site.xml)
当从HDFS的高可用版中读取数据时
when namenode HA is enabled ,don not use the active namenode hostname in URI, because HA will swith the active namenode to standby namenode in case of any failures .So use the value of the property
name fs.defaultFS from
core-site.xml Example : hdfs://Nameservice:8020
SparkContext
这个应用程序进入spark集群的入口。
Transformations and actions
有两种RDD的操作方式,transformation基于当前的RDD创建新的RDD,actions是返回RDD的值
Cache
将中间计算结果缓存下来
平行度

这个是和executor的总的计算核数有关的,如果在启动了spark时指定了executor的总的计算核数的话就变了
例如

或者

结果就都变成了

Let s created a list, parallelize it ,and check the number of partitions
val mylist = List("big","data","analytics","hadoop","spark")
val myRDD = sc.paralielize(myList)
myRDD.getNumPartitions 这个数和默认的executor总核数一样
也可以在创建RDD之初就指定分区数
val myRDD = sc.paralielize(myList,6) 增加了平行度
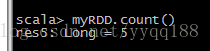
getNumPartitions方法说明了MyRDD有4个分区,所以作用于该RDD的任何action操作都会使用4个task,这就意味着count()的这个action操作要用4个线程,而且是在不同的机器上分别启动,每个线程.
每个task或者thread读取和计算其中一个partition上的数据,并发送到驱动主机上的JVM中,driver接着汇总所有的数
现在可以用mapPartitionsWithIndex transfromation算子获取每个分区的index 和 每个分区内的数据,
myRDD.mapPartitionsWithIndex(lambda index,iterator:((index,list(iterator)),)).collect()
[(0, ['big']), (1, ['data']), (2, ['analytics']), (3, ['hadoop','spark'])]
当重新分区后
val mySixPartitionRDD = myRDD.repartition(6)
mySixPartitionsRDD.mapPartitionsWithIndex(lambda index,iterator:
((index, list(iterator)),)).collect()
[(0, []), (1, ['big']), (2, []), (3, ['hadoop']), (4, ['data', 'spark']),
(5, ['analytics'])]
再重新分区后
myTwoPartitionsRDD = mySixPartitionsRDD.coalesce(2)
myTwoPartitionsRDD.mapPartitionsWithIndex(lambda index,iterator:
((index, list(iterator)),)).collect()
[(0, ['big']), (1, ['hadoop', 'data', 'spark', 'analytics'])]
两种分区方式的比较:
coalesce 函数在减少分区时不会引起shuffle ,repartition会导致物理shuffle。
注意一:
高分区数以及每个分区内有少量的数据,并行度会高,但是过于分散会加重调度的负担。
低分区数以及每个分区内数据量过大,并行度会降低,以及每个exceutor执行时间过长,一个合理的partition size 的大小是 100M 到 1G
注意二:
spark从HDFS创建RDD,会根据HDFS的每个block创建一个partition,如果block有8个,spark就会创建8个分区,这个分区数可以根据情况增加,但是不能低于8个。
Lazy evaluation
RDD are empty when they are created ,only the type and ID are determined
spark will not begin tp execute the job until it sees an action
Lazy evaluation is used to reduce the number of passes it has to take over the data by grouping operations together
In MapReduce ,developers have to spend a lot of time thinking about how to group together operations to minimize the number of MR passes
A task and all its dependencies largely omitted if the partition it generates is already cached
Lineage Graph
RDDs are never replicated in memory . In case of machine failures , RDDs are automatically rebuilt using a Lineage Graph ,When RDD is created ,it remembers how it was built, by reading an input file or by transforming other RDDs
and using them to rebuild itself,It is DAG based representation that contains all its dependencies .
toDebugString function ,we can find out the lineage graph of the RDD
println(myTwoPartitionsRDD.toDebugString())
spark 消除依赖关系的两种情形:
1 一旦cache了 ,就把依赖关系清除spark insternal scheduler may truncate the lineage of the RDD graph if an RDD has already been cached in memory or on disk
2 虽然没有cache,但是在shuffle的时候有部分数据溢出内存空间,写入到磁盘了,也会导致依赖关系清除 a second case when this truncation can happen is when an RDD is already meterialized as side-effect of an earlier shuffle,even if it was not cached。可以通过spark.shuffle.spill = false 把这个部分关掉
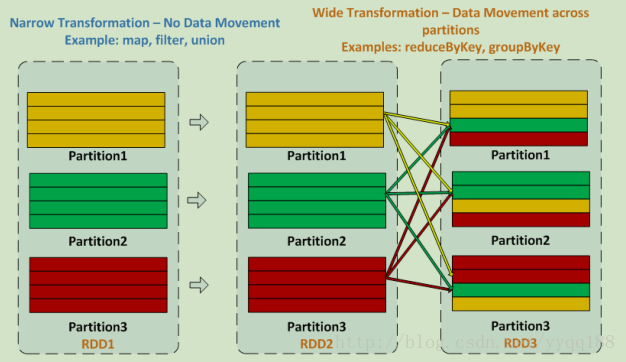
深入理解下什么是窄依赖,什么是宽依赖
窄依赖中,partition内的数据没有跨partition的移动 filter map union
宽依赖中,partition中的数据有跨partition的移动 reduceByKey groupByKey
序列化
Every task send from driver to executor and data sent across executors get serialized
It is very important to use right serialization framework to get optimum performance for application
spark提供了两种序列化库:java serialization 和 Kryo serialization
设置:
conf.set("spark.serializeer","org.apache.spark.serializer.KryoSerializer")
--conf spark.serializer = org.apache.spark.serializer.KryoSerializer
Kryo serialization in pyspark will not be useful because pyspark data as byte object
spark有内建的机制去读写以sequence file ,AVRO,parquet ,Protocal Buffer 序列化的数据。
使用hadoopRDD 和 newAPIHadoopRDD 方法可以去读任何hadoop支持的inputformat
使用saveAsHadoopDataset 和 saveAsNewAPIHadoopDataset
SparkSQL 也支持Hive支持的存储形式,例如sequence file ,Avro ,ORC, Parquet , Protocol Buffers
spark API 支持的其他几种数据格式:
- sc.wholeTextFiles 用于读hdfs目录下的小文件,文件名是key ,内容是value
- sc.sequenceFile 用于读取hdfs 的sequence file 还可以saveAsSequenceFile(xxx)
- hadoopFile 用于读老版本的hadoop文件
- newAPIHadoopFile
例如: python版本
fileLines = sc.newAPIHadoopFile('/data/input/*',
'org.apache.hadoop.mapreduce.lib.input.TextInputFormat',
'org.apache.hadoop.io.LongWritable',
'org.apache.hadoop.io.Text',
conf = {'mapreduce.input.fileinputformat.input.dir.recursive':'true'}
)
其他的可以在spark中配置hdfs属性的方式:
scala
sc.hadoopConfiguration.set("custom.mapreduce.setting","someValue")
python
sc._jsc.hadoopConfiguration().set('custom.mapreduce.setting','someValue')
总结:读取hdfs序列化格式的数据用 hadoopDataset 或者 newAPIHadoopDataset
写入hdfs序列化格式的数据用 saveAsHadoopDataset 或者 saveAsNewAPIHadoopDataset
scala or java 中 序列化Java object 用 RDD.saveAsObjectFile 和 sc.objectFile
python 中 the saveAsPickleFile and pickleFile methods are used with pickle serialization library
Data locality
Data locality determines how close data is stored to the code processing it
it is faster to ship serialized code rather than data from one place to another,because the size of the code is much smaller than the data.
下面是依据数据当前存储情况分成的几个本地存储级别,按照从近到远的顺序。

每个级别的后退等待超时可以用spark.locality.wait 配置。默认是3秒
当使用yarn调度,executor会被分配到block数据块所在的节点。可以通过 getPreferredLocations函数实现。
shared variables 共享变量
driver向executor传递function时,假如有4个task,会复制出4个独立的变量,并行的运行。
但是当driver发送一个包含大量数据的对象时,就有问题了
所以spark创建了两个共享变量:
broadcast variable : 允许一个只读的变量缓存在一个机器上,而不是发送到每个task上。例如有20个节点的集群中有200个task,只要广播20个而不是200个。
python写法:
broadcastVar = sc.broadcast(list(range(1,1000)))
broadcastVar.value
Accumulators 允许task写数据到一个分享变量而不是对每个task独立看待。 最后driver能获得这些累加器的值
myaccum = sc.accumulator(0)
myrdd = sc.parallelize(range(1,100))
myrdd.foreach(lambda value:myaccum.add(value))
print myaccum.value
Pair RDD
spark provides special transformations and actions on RDDs
containing key-value pairs
There RDDs are called Pair RDDs. Pair RDDs are useful in many spark programs .as they expose transformations and actions that allow you to act on each key i
n parallel or regroup data across the network(只有pair RDDs才能shuffle) . For example ,Pair RDDs have a reduceByKey transformation that can aggragate data separately for each key,and join transformation that can merge two RDDs tegether by grouping elements with the same key
spark项目的生命周期
接下来解释下spark应用在standalone资源管理下的生命周期
1 用户submit一个spark应用
2 在driver主机上启动driver program
3 driver program 中的cluster manager(yarn/mesos) 根据配置的要求为executor JVM 申请资源
4 接着cluster manager 把executor JVMs 发送到worker 节点
5 driver 基于程序中的transformations 和 actions 去创建执行graph
6 当action动作被响应,就把graph提交给DAG scheduler ,DAG scheduler把graph分割为stages
7 其中某个stages就是一组tasks,它的并行度依据的是输入的数据,同时DAG scheduler会把操作优化,例如多个map的操作会合并成一个stage,这样最后形成的就是stages 的集合
8 这写stages会传输给task scheduler,task scheduler通过cluster manager(yarn/mesos)发送tasks,task scheduler并不知道这些stagas的依赖关系。
9 task 在executor 中被处理
10 如果main方法退出或 sc.stop ,就会中断executor的执行并释放资源。
spark-submit
如果有个配置参数,可以把这些参数都放入到一个文件中,并通过 --properties-file来配置
spark-submit --class com.example.MyApp --properties-file my-config-file.conf myApp.jar
my-config-file.conf的内容有:
spark.master spark://x.x.x.x;7077
spark.app.name "my spark app"
spark.ui.port 36000
spark.executor.memory 2g
spark.serializer org.apache.spark.serializer.KryoSerializer
spark 配置的优先级的顺序,由高到低
1 在程序中通过SparkConf的set方法定义的
2 通过spark-submit 或 spark-shell 定义的
3 在spark-default.conf 文件中定义的
4 spark的默认设置
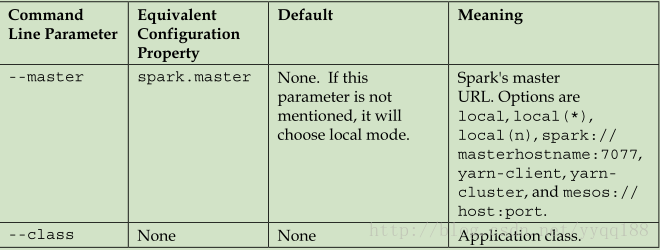
启动spark程序时导入的一些参数说明

RDD的缓存存储
spark有两种命令 RDD.cache 或者 RDD.persist 都表示存储在内存级别(MEMORY_ONLY)
不同点是cache本身就只有MEMORY_ONLY这一种语义,
而persist可以有多种选择定义

如果要求更快的失败重启,就用RDD复制的存储方式,否则就最好别用。
Spark的资源管理器---standalone,Yarn Mesos
spark本身有四种资源管理模式:
Local mode 在本地模式下,所有的处理过程都在单独一个JVM这种,没有数据的shuffle
standalone mode 将spark程序提交给spark内建的集群管理器
YARN mode 将spark程序提交给yarn资源管理器
Mesos mode将spark程序提交给mesos资源管理器
具体来说:
在standalone的模式下,默认情况是每个executor给予1G的内存(spark.deploy.defaulyCores的参数配置)
给予的总的executor的数
在spark-submit操作下用 --total-executor-cores命令来配置
在spark的配置文件中 用 spark.cores.max的参数来配置
给予每个executor的内存配置
在spark-submit的情况下,是用 --executor-memory 参数配置
在spark的配置文件中,用spark.executor.memory来配置
举个例子:
如果有20个节点每个节点有4个CUP的核
如果没有特殊配置的情况下,会有20个executor,每个executor有1G的内存和4个核
--executor-memory 1G 和 --total-executor-cores 8
在多任务的情况下,表示给予这个任务程序 8个executors 和每个executor 1 G的内存
如果在spark conf中把spark.deploy.spreadOut 改成false的话, spark将给予两个executor 每个executor给予1G内存和4个cores
在yarn的模式下
--master yarn-client 是客户端模式 --master yarn-cluster是集群模式
在yarn模式下可以自定义executor的数量,cores的数量
--num-executors executors的数量 默认是2,可以在配置文件中用 spark.executor.instances定义
--executor-memory 是每个executor的内存
--executor-cores 是每个executor的的计算核数
例如 在20个节点 每个节点有4个计算核数
默认情况是有2个executor 每个executor有1个core 和 1G内存
--num-executors 8 --executor-memory 2G --executor-cores 4
表示有8个executors 每个有2G内存,有4个cores
yarn的资源动态分配:
为了开启这个动态分配功能要打开或设置一下的配置
spark.dynamicAllocation.enabled
spark.dynamicAllocation.minExecutors
spark.dynamicAllocation.maxExecutors
spark.dynamicAllocation.intialExecutors
spark.shuffle.service.enabled
如果要使用yarn的资源动态分配,就不要使用--num-executors 这个参数了,否则动态规划不起作用,而会使用--num-executors的参数。
yarn的Client mode 和 Cluster mode是区别
在Client mode下 driver是运行在客户端的主机上
application master 和 executors 运行在集群上
在Cluster模式下,driver 是 在application master 内的,是运行在集群中的
yarn-cluster 是用于生产任务
而 yarn-client是用于交互环境,为了立即看到应用的输出。
Mesos模式下
spark-submit --master mesos://masternode:5050
mesos有两种调度模式:细粒度和粗粒度
细粒度是mesos的默认模式,类似于yarn
粗粒度要配置,类似于standalone
-- conf spark.mesos.coarse=true 开启粗粒度模式