基于分层循环神经网络的音频超分辨率
作者:Berthy Feng
摘要
本工作提出了一种用于音频超分辨率的循环模型,该模型的任务是推断低分辨率语音的高分辨率版本。鉴于缺乏基线方法和关于最适合此任务的深度学习方法的模糊性,我们将重点放在循环神经网络上。我们提出了一种分层循环神经网络(HRNN),它使用基于回归损失和感知损失相结合的损失函数进行训练。在本文中,我们提出了基线HRNN的体系结构和两种类型的感知损失,以便于改进基线。我们的基线模型优于插值方法,我们提出的感知损失通过提供可解释性和产生感知现实结果来改善基线。
一、引言
1.1 音频超分辨率
音频超分辨率的任务是提高音频记录的分辨率。无论是在时间域还是在频率域,都有各种各样的方法来概念化这个任务。
在时域上,任务是提高给定音频波形的采样率。例如,在16 kHz采样的音频的分辨率是在8 kHz时采样的音频的两倍。采样率越高,每个时间单位采集的样本越多,因此捕获的声音成分频率越高,可能包括语音的泛音和房间的混响。
在频域中,任务是扩大音频信号的带宽。也被称为带宽扩展,其目标是从给定的窄带信号中产生一个宽带信号,在该窄带信号中,宽带输出在较高的频带频率下恢复能量。
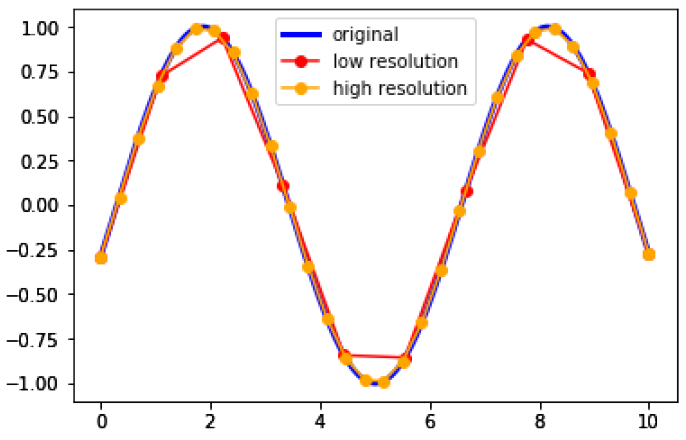
图1:采样率对波形分辨率影响的可视化。橙色线采样原始正弦波的频率是红色线的三倍,从而产生更准确的波形。我们的任务是根据红线推断橙色线。
两种关于音频超分辨率的思维方式都是有效的,因为它们都旨在恢复高频分量。然而,它们往往导致不同的结果。时域方法将音频建模为时间序列,从而更准确地再现信号的波形和相位信息。频域方法将音频建模为频率频谱,从而更准确地再现每个频率上的能量和音频的“颜色”。换句话说,时域方法可能会导致更真实的波形,而频域方法可能会导致更真实的频谱图。目前,大多数最先进的音频合成方法都是在频域工作的,使用的是前馈网络,而不是循环网络。
1.2 我们的工作
我们的方法是在时域中的,因为所提出的结构工作在波形级别。为了提高在频域内的准确性,我们提出了一种感知损失,以鼓励实际的频谱图结果。我们的任务特别是单声道语音的超分辨率,其中输入是一个8kHz的语音,输出是16kHz的版本,恢复了更高的频带频率。
单说话人的原因是很难建立一个代表所有人类声音的模型,因为一个声音以其音色为特征。将采样率增加到16 kHz的原因是为了给录音带来一种存在感。许多带宽扩展技术的目标是从很非常低的采样率(如3 kHz)扩展到中等采样率(如8 kHz)。达到8 kHz将恢复基本的语音质量,在许多电信应用中有助于使发送的语音可分辨。然而,超过8千赫的频率增加了更微妙的分辨率和颜色,使听者对场景和说话人有了更清晰的了解。

考虑到音频波形的时序性,我们对音频超分辨率的循环模型进行了实验。我们重点研究循环递归神经网络,它能够在多个时间尺度上对序列信息进行建模。
1.3 循环神经网络
循环神经网络(RNN)是一种具有反馈连接的神经网络[15]。在给定的时间步骤$t$中,RNN有一个隐藏状态$h_t$,它是根据先前的隐藏状态$h_{t-1}$和该时间步骤的特定输入$x_t$的函数计算的。此递推公式表示为:
$$h_t=f_W(h_{t-1},x_t)$$
参数为$W$的函数$f_W$,一旦学会,就会在所有时间步骤中保持不变。
RNNs对序列数据的建模非常好。它们广泛应用于与自然语言处理相关的任务中,包括机器翻译、图像字幕和文本生成。自从20世纪90年代流行起来[15]以来,出现了各种类型的RNN,包括长短时记忆(LSTM)网络[4]和门控复发单元(GRU)[1]。
1.4 分层循环神经网络
音频的连续性使其适合于一个循环模型。然而,一个RNN可能不足以捕获重建高分辨率信号所需的信息。音频包含低级信息,如精确的采样值,以及高级信息,如语音音素、回声和混响。层次RNN(HRNNs)提供了一种在多个层次上使用信息的方法。

图2:RNN可视化
一个HRNN包含多个RNN层,其中每个层的输入覆盖不同的范围。SampleRNN是一种最先进的音频生成方法,其体系结构为HRNN[12]。例如,具有三层的SampleRNN,可能会让顶层RNN一次处理八个样本,中间层RNN一次处理两个样本,而低层RNN一次处理一个样本。在HRNN中,较低层RNNs通常将较高层RNN输出作为附加输入。在这个层次结构中安排RNNs允许模型从多个层次的信息中学习。这种方法在音频中特别有用,因为在音频中有一个记录语音特征的层次结构。
1.5 概述
在第二节中,我们描述了我们工作的动机,包括音频超分辨率的应用,以及我们使用循环模型和感知损失的想法背后的灵感。
在第三节中,我们阐述了项目的两个主要和相互关联的目标。
在第四节中,我们回顾了带宽扩展和音频生成方面的相关工作。
在第五节中,我们解释了所提出的HRNN体系结构和两种类型的感知损失。
在第六节中,我们描述了我们的实施和训练方法。
在第七节中,我们展示了我们的结果,并证明了我们提出的方法实现了感知现实的输出。
在第八节和第九节中,我们为未来的工作提供结论和指导。
2 动机
2.1 音频超分辨率应用
传统上,音频超分辨率被称为带宽扩展。这项任务在电信领域有着重要的应用,在电信领域,提高低带宽设备上语音的语音质量非常重要。音频超分辨率也有更现代的应用。它在文本到语音合成中很有用,在这种合成中,语音可能首先以低分辨率合成。它对那些希望提高录音质量的人也很有用,这可能是因为音频最初是在低质量麦克风上录制的,也可能是因为音频被压缩为低采样率。由于我们的工作集中在8kHz以上的高频段,我们的目标是给录制的语音一种临场感。我们假设窄带语音已知,我们的目标是改善听力体验。
2.2 理解RNN的建模能力
WaveNET[17]是一种用于音频生成的前馈网络,它的成功促使许多研究人员默认使用前馈网络来执行音频合成任务。然而,一种基于时间的、循环的音频超分辨率方法的可能性还有待于充分探讨。需要用RNNs来进行超分辨率的实验,这是这项工作的动机之一。
2.3 来自机器视觉的启发
计算机视觉中的许多思想都可以转换成音频。目前已经有多种最先进的图像超分辨率方法被提出,因此从图像超分辨率的洞察可以帮助我们在音频领域。具体来说,增加一个知觉损失有助于显著提升图像超分辨率。感知丢失的关键思想是鼓励感知现实的结果,而音频超分辨率的目的也是为了产生感知现实的结果(例如相移等变换不会影响人耳感知的质量,所以我们不关心与地面真相精确匹配的问题)。考虑到感知损失这一前景光明的概念,可能有可能克服RNN的典型缺陷,例如过度平滑。因此,另一个动机是利用计算机视觉中的洞察力,并将它们应用于音频问题。
3、目标
本项目的目的是开发一种用于音频超分辨率的分层循环神经网络。具体来说,这意味着完成这两个步骤:
1、提出了一种基线HRNN方法,该方法能在单说话人语音上获得可接受的结果。
2、提出了一种感知损失改进的基线方法。更普遍的目标是找出基于RNN的音频超分辨率方法的优缺点,并为今后的工作提出方向。
4、相关工作
4.1 基于学习的声码器方法
声码器是一种常用的频域音频建模方法。在该方法提取了窄带输入信号的频谱参数,并将其映射到相应的宽带输出信号的频谱特征。现有许多基于机器学习的经典方法,包括码本映射、高斯混合模型和隐马尔可夫模型。神经网络也被用来编码输入特征并对其进行解码以产生宽带输出。为此提出了密集神经网络(DNN)[10]和循环神经网络[3]。尽管声码器的参数化,但这些方法的难点在于恢复相位谱并保持原始语音质量。
4.2 生成音频模型
由于WaveNet[17]及其后续产品Tacotron 2[14]的成功,基于波形的音频生成方法变得越来越流行。两种方法都使用扩张卷积来扩展卷积神经网络(CNN)的接收场,并且都是完全前馈的。Tacotron 2是基于梅尔频谱预测的,这个想法影响了我们基于频谱的感知损失的设计。WaveNet和 Tacotron 2用于随机音频生成和文本到语音合成,这两个问题都需要从头开始建模音频的分布。但是,这些方法并没有针对超分辨率任务进行优化,因此在训练期间可以进行更多的监督。虽然这些前馈网络实现了最先进的综合,我们的目标是提出一个替代,专门用于超分辨率的循环网络。
SampleRNN[12]是主要的循环生成模型,也是我们建议的灵感来源。然而,它并没有针对超分辨率进行优化,因为SampleRNN的目的是从头开始模拟音频分布,并允许输出的随机性。但是,超分辨率取决于输入信号,因此任务允许更有限的输出空间和有监督的训练方案。
4.3 深度学习的方法
直到最近,研究人员才专门为音频超分辨率设计了深度学习模型。kuleshov 等人提出了一种简单的卷积神经网络作为音频超分辨率的基线神经网络[8]。Ling 等人将SampleRNN应用于带宽扩展,并获得比完全前馈网络更好的结果[11]。这两项工作都提供了相当简单的模型,并提出了改进的机会。Ling等人的工作。为我们的方法提供了灵感,尽管我们修改和改进了它们的模型,使其更适合于音频的超分辨率。
5、方法
5.1 HRNN体系结构
一般情况下,分层循环神经网络可能总共有K层,其中顶层K-1层在帧级别上运行(其中帧是一组样本序列),底层一次处理一个样本。我们提出了一个三层循环神经网络作为基线模型,它包括两个帧级别层和一个样本级别层。
输入:窄带输入在8 kHz时采样,然后向上采样到16 kHz,使其与宽带16 kHz输出具有相同的采样长度。注意,即使输入每秒包含16000个采样点,其频率量仍然不超过8 kHz。然后使用mu-law编码将每个样本量化为0到255之间的值。这允许我们使每个输入样本成为一个长度为256的热编码向量,其中对应于样本量化值的索引被标记为“1”,所有其他索引都标记为“0”。设$\{x_1,...,x_T\}$表示长度$T$的整个输入序列(例如,对于在16 kHz采样的三秒音频,T=48000)。每个$x_t$表示一个热向量,表示样本在t处的量化值。
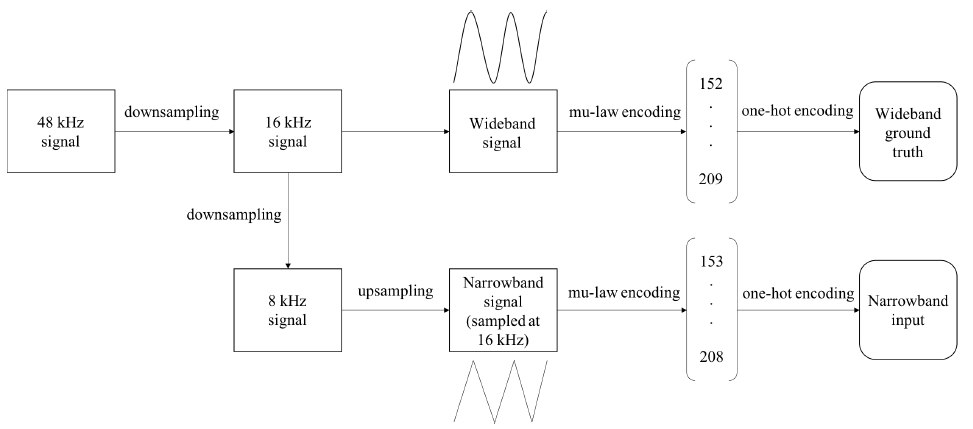
图3 准备输入
第三层:最高帧级别层一次处理8个样本。我们将其实现为单层RNN(尽管可以添加任意数量的层)。在$t$时刻,它的输入为:
$$f_t^3={x_t,...,x_{t+7}}$$
RNN的隐藏状态表示为:
$$h_t^3=g^3(h_t-1^3,g_t^3)$$
其中$h_{t-1}$是前一个隐藏状态,g3是已学习的RNN函数。
为了将信息传递到下一层,顶层为第2层生成条件向量。由于第2层每次处理2个样本,第3层没次处理8个样本,因此第3层每次输出4个条件向量(每处理两个样本就有一个)
每一时间步骤输出四个条件向量(每处理两个样本就有一个)。$t$时刻的条件向量表示为:
$$d_{t+j}^3=W_j^3h_t^3,j=0,2,4,6$$
所有$d_{t+j}^3$都成为第2层的输入。
在第三层中,我们为每一个新的时间步骤增加8个样本。这是因为我们希望第3层的每个时间步骤都有不重叠的输入序列。
第二层。中间层一次处理两个样本。也是作为单层实现RNN,它在时间$t$处的输入是样本输入和第3层的条件向量的线性组合:
$$f_t^2={x_t,x_{t+1}}+{d_t^3}$$
其隐藏状态表示为:
$$h_t^2=g^2(h_{t-1}^2,f_t^2)$$
第2级还为每个样本输出一个条件向量,然后将其用作第1层的输入。在每一步t中,RNN输出两个条件向量:
$$d_{t+j}^3=W_j^3h_t^3,j=0,1$$
在第二层中,我们为每一个新的时间步骤增加两个样本t,以便输入序列不重叠。
第一级。最底层,也被称为样本层,是一个完全前馈多层感知器(MLP)。我们将其实现为三个完连接的层(DNN)。在此阶段,输入样本被发送到一个已知的256维的嵌入层,因此每个输入样本$x_t$被嵌入为真值,(256维的向量$e_t$)。输入$i^1$是嵌入向量$f^1=[e_1,...,e_T]$和条件向量$d^2=[d_1^2,...,d_T^2]$的线性组合:
$$i^1=W^1f^1+d^2$$
对于每个输入样本$x_t$,MLP在输入信号的窄带版本中预测相应的输出样本$y_t$(注意$y_t$是一个标量)。总之,我们已经描述了用HRNN函数建模背后的体系结构:
$$y_t=HRNN(x_t),\forall t\in T$$
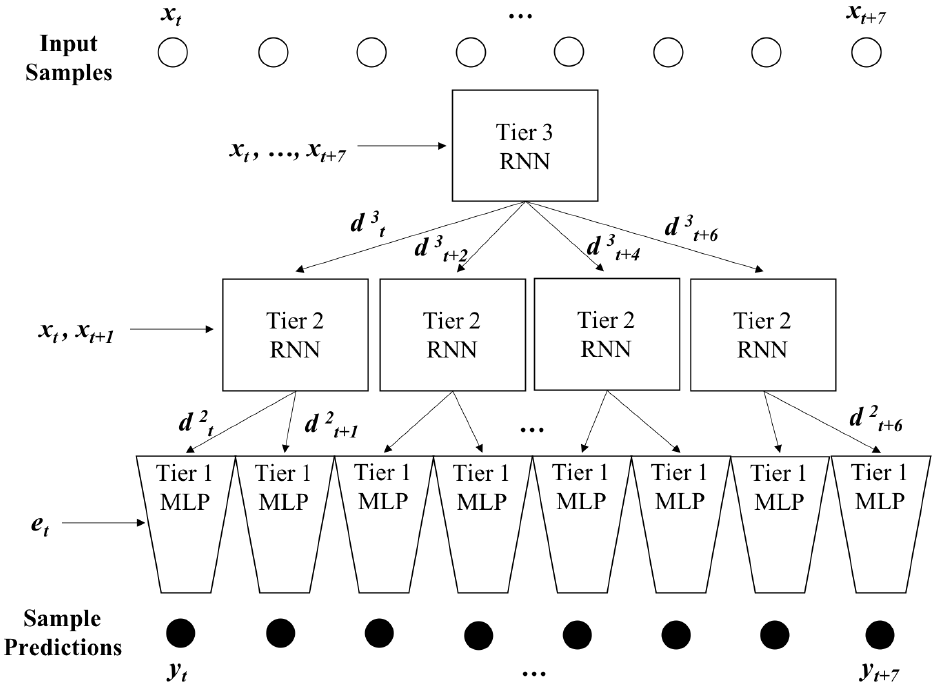
图4 HRNN体系结构
5.2.回归与分类
我们修改了Ling等人的SampleRNN架构[12]和HRNN架构。[11]把模型的功能从分类转换为回归。以前的HRNN模型输出每个时间步上的量化值的概率分布。也就是说,对于每个输入样本$x_t$,HRNN输出条件分布$p(y_t|x_1,x_2,...,x_t)$(考虑到第1层更宽的框架,分布实际上也取决于t之后的样本)。对于随机音频生成的分类比超分辨率更有意义。SampleRNN最初是为无条件音频生成而设计的,其目标是生成听起来像是从自然分布中随机抽取的音频。然而,超分辨率是以窄带输入信号为条件的,在结构样本中不需要随机性。
此外,将模型转换为基于回归的模型可以更容易地增加感知损失。如果输出是概率分布,那么要构造输出波形,必须在每个时间步选择一个离散值。这个样本选择步骤是不可微的,因为argmax或分布中的随机选择是离散的。因此,如果我们将任何网络添加到HRNN中,该模型将不完全可微。这就会导致训练问题,因为HRNN通过反向传播来学习其参数,而反向传播取决于网络中所有操作的可区别性。
通过修改HRNN进行回归,使模型从输出波形到输入波形完全可微分。我们还减小了模型的大小,使其更简单,内存占用更少。这是一个重要的方法来优化语音超分辨率的HRNN,因为基于回归的模型更适合任务的监督性质,并使更多的可能性和额外的损失在训练期间。
5.3.感知损失
受图像超分辨率中感知损失成功的启发,我们在HRNN的训练过程中进行了附加感知损失的实验。Johnson等人证明了感知损失在鼓励 图像样式转换和超分辨率 的真实结果方面的有效性[6]。我们的研究任务是设计一个适合音频的感知损失。
感知损失的目的是鼓励感知现实的波形或频谱。并且,我们面临着在时域或频域中工作的问题。我们设计了两种感知损失:一种是时域对抗损失,另一种是频域的频谱损失。
对抗性损失:生成对抗网络(GANs)为图像超分辨率产生了令人印象深刻的结果[9]。我们提出了一个用于音频超分辨率的GAN。
Goodfellow等人首先提出了GANs,它是由一个生成器网络和一个鉴别器网络组成[5]。生成器尝试产生真实的输出,而鉴别器尝试区分“真实”和“虚假”示例。例如,在用于图像生成的GAN中,生成器从随机种子中生成图像。该生成器的目标是学习图像特征的自然分布,并生成看似从该自然分布中采样的图像,而实际上这些图像是人工的。鉴别器的目标是将图像分为“真”或“假”。生成器的作用是愚弄鉴别器,而鉴别器的作用是识别生成器的输出,因此GAN训练本质上是一个两人的最大最小游戏,其中两个网络具有竞争目标[5]。
我们提出了一个GAN架构,其中生成器是HRNN,鉴别器是一个前馈CNN。对鉴别器的输入是由HRNN产生的波形(即量化样本序列),鉴别器的输出是输入为真实数的概率(即输出为“1”表示输入为实,“0”表示输入为假)。鉴别器CNN被实现为一系列的降采样模块。网络本质上将输入编码作为特征向量,然后将其分类为实或假。
对抗损失被定义为1.0和鉴别器输出之间的均差方。如果$y$是HRNN的输出,$D(y)$是鉴别器的输出,则对抗损失可以定义为:
$$adversarial loss=(D(y)-1.0)^2$$
由于基于回归的HRNN的可微性,$y$实际上是可微的,鉴别器$D$也是可微的。因此,$D(y)$在HRNN和鉴别器CNN中的所有参数端到端都是可微的。
频谱损失:我们也可以在频域中定义“真实”音频。也就是说,感知现实的音频应该产生可视化的光谱图。我们提出了另一种称为“频谱”损失的感知损失,定义为基态对数Mel频谱和预测对数Mel频谱之间的均方差。
我们首先通过对音频信号进行短时傅立叶变换(STFT)来计算该信号的对数梅尔频谱。我们取STFT的绝对值来计算量频谱。然后,我们使用线性到Mel权重矩阵(在TensorFlow Contrib包中提供)将这些转换为Mel光谱图。对数mel频谱是mel频谱的以10为底的对数。
我们将频谱损失定义为预测宽带信号的对数mel光谱图(LMS)与ground-truth(标注)窄带信号的LSM之间的均方差:
$$spectral loss=(LMS(y)-LMS(ground truth))^2$$
对抗损失和频谱损失都是额外的损失都是训练过程中额外的损失。我们使用一个简单的L1损失(预测输出和ground-truth输出之间差的绝对值)作为基于回归HRNN的输出。训练过程中应尽量减少的总损失为:
$$loss=L1+perceptual loss$$
6.研究方法
6.1.数据集
在训练和测试中,我们使用VCTK语料库[18],其中包括109以英语为母语的说话人的语音录音。此数据集包含超过18 GB的数据,并且每条语音都以48 kHz的频率采样。
为了对数据进行预处理,我们使用librosa python包中实现的插值滤波器,将所有语音从48kHz减采样到16kHz,以形成ground-truth宽带语音。然后,我们对所有48kHz语音下采样到8kHz,形成输入窄带语音。为了确保输入采样长度与输出采样长度相匹配,我们在不恢复高频成分的情况下,将窄带录音上采样到16khz。图3是输入管道的图。
我们将数据集拆分为80:20的训练:验证集。我们进行了各种规模大的实验,包括整个数据集、2/3的数据集和以一个说话人的所有语音为数据集。
6.2.实现
我们的模型定义、训练和评估脚本都是在python和tensorflow中实现的,可以在https://github.com/berthyf96/audio_sr上找到。大部分代码都是从unisound的SampleRN的实现中修改而来的[16]。鉴别器网络的实现借鉴了Pascual等人的工作,他们设计了用于语音增强的GAN[13]。
6.3.训练
我们用各种超参数来训练模型。我们首先为HRNN寻找合适的模型大小。模型大小被定义为RNN的维数(每个RNN的隐藏状态向量中的值的数目)。1024维相对较大,可能会导致过拟合,因此我们对1024、512和256维进行了实验。我们发现,在训练和验证损失曲线出现偏差之前,我们能够找到一个很好的停止点来训练1024维模型。考虑到最大的模型似乎没有与训练数据过度拟合,我们选择了1024作为模型大小。
有两种RNN类型会导致类似的性能。长短时记忆(LSTM)网络[4]和门控循环单元(GRU)[1]都具有选通功能,以确定从以前状态传递到下一状态的信息。实验表明,这两种RNN类型具有可比的性能[2]。
我们使用Adam优化器,它随着训练的进展而调整学习率[7]。时间反向传播(BPTT)是RNN的反向传播方法。我们使用截断的BPTT,每512个时间步更新一次HRNN权重。注意,由于每个RNN状态依赖于前一个时间步骤,因此我们无法预测前八个输入样本(第3层RNN的第一个输入序列)中的任何样本。因此,训练期间的输入序列长度为512+8=520个样本。
我们主要使用以下参数设置来训练基线HRNN模型(没有感知损失)
| 参数 | 值 |
| RNN维度 | 1024 |
| RNN类型 | LSTM |
| 优化器 | Adam |
| 学习率 | 0.0001 |
| 截断的BPTT序列长度 | 520 |
| 采样率 | 16000个样本/秒 |
表1:训练超参数
7.结果
我们在单声道数据集上评估了HRNN基线、HRNN+频谱损失(HRNN+Spc)模型和HRNN+对抗性损失(HRNN+GAN)模型,特别是VCTK语料库中的“p225”说话人。训练集由223个wav文件组成,每个文件至少3秒长,验证集由8个wav文件组成,每个文件大约3秒长。注意,当训练序列序列长度为520个样本时,这意味着每个音频文件至少有90个训练样本。通过对单个语音的评估,我们可以更好地理解HRNN在这项任务中的性能上限,因为多说话人的HRNN模型最多只能执行一个专门的单说话人的HRNN。
我们首先比较了HRNN基线、HRNN+Spec和HRNN+GAN的训练结果。然后对模型性能进行定性和定量比较。
7.1.基线 与 频谱损失 与 对抗损失
我们发现,在训练过程中,HRNN基线和HRNN+Spec的收敛速度相当快。我们对这两种模型进行了700步的训练,批处理大小batch size为32,z这相当于有100个epoch周期。
通过绘制训练过程中的测试损失和验证损失,可以检查是否存在过拟合。我们发现,即使模型尺寸为1024维,验证损失曲线也不会偏离训练损失曲线。图5和图6分别显示了基线和HRNN+Spec的损失曲线(所有损耗曲线都是使用TensorBoard生成的)。
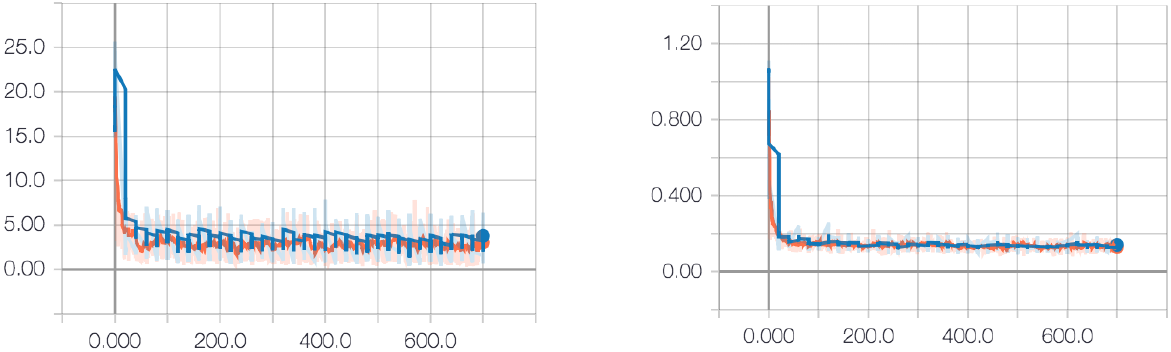
(a) L1损失 (b)频谱损失
图5:基线L1损失和频谱损失(不是损失函数的一部分)曲线。训练损失为橙色,验证损失为蓝色。基线模型自然地降低了频谱损失,而没有明显的感知损失。
训练GAN的挑战性体现在HRNN+GAN训练结果中。如图7中的损失曲线所示,鉴别器学习得更快。我们训练了学习率为0.0001(与HRNN基线和HRNN+Spec相同)的生成器和学习率为0.00001的鉴别器,降低了鉴别器的收敛速度。我们还允许生成器在每30步更新鉴别器参数之前训练100步。令人鼓舞的是,对抗损失和鉴别器损失似乎都在逐渐减少,虽然速度很慢。这表明需要更多 和/或 更好的训练才能取得更好的效果。我们将训练过程的改进留给将来的工作。

(a)L1损失 (b)频谱损失
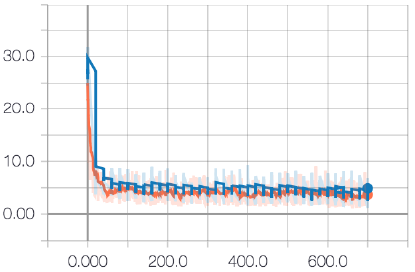
(c)总损失
图6:hrnn+Spec损耗曲线。训练损失为橙色,验证损失为蓝色。HRNN+Spec比基线更好地优化了频谱损失。

(a)L1损失 (b)对抗性损失

(c)鉴别器损失
图7:HRNN+GAN损失曲线。训练损失为橙色,验证损失为蓝色。即使在100步的提前启动情况下,由于鉴别器学习速度更快,生成器仍在努力减少敌方损失。
7.2.定性结果
我们发现,HRNN基线、HRNN+Spec和HRNN+GAN可以清晰地将高频内容还原为低分辨率音频。输出音频听起来更亮,表明频谱变宽。图8比较了我们的方法和插值方法的输出光谱图,并表明我们的方法产生了更具视觉说服力的结果。
对于这里描述的定性评估,我们使用来自单说话人验证集的三秒钟语音录音作为输入。为了生成输出wav文件,由于所有模型都是用520个样本的序列长度进行训练的,我们可以实例化一个序列长度更长的模型(48008个样本的模型),或者使用交叉淡出将512个样本的输出补丁缝合在一起。我们发现,后一种方法产生的噪声输出稍微小一些,因为随着时间的推移,模型会偏离ground truth值。本文中的输出示例是使用交叉淡入淡出方法生成的。我们可以通过改进512长片拼接的方法,来以获得更好的效果。波形和频谱图可视化的代码是由Zeyu Jin提供的。

(a)线性插值 (b)三次样条插值

(c)HRNN基线(我们的) (d)HRNN+Spec(我们的)

(e)HRNN+GAN(我们的) (f)Ground truth
图8:插值方法和我们的方法之间的频谱输出比较。插值方法低估了高频段的能量,在低波段和高波段之间留下了一条清晰的低能量线。我们的方法覆盖了整个频谱。
基线:图9显示了经过700步训练的HRNN基线的输入和输出示例。输出波形比输入波形更为详细,输出的频谱在高频带频率的能量得到了恢复。虽然很难分辨出ground-truth波形和输出波形之间的差异,但ground-truth频谱和输出频谱之间存在明显的差异。输出频谱在低频带和高频带之间有一条清晰的线。高频带中的能量出现过平滑现象,这是由于RNN的过平滑趋势所导致的。
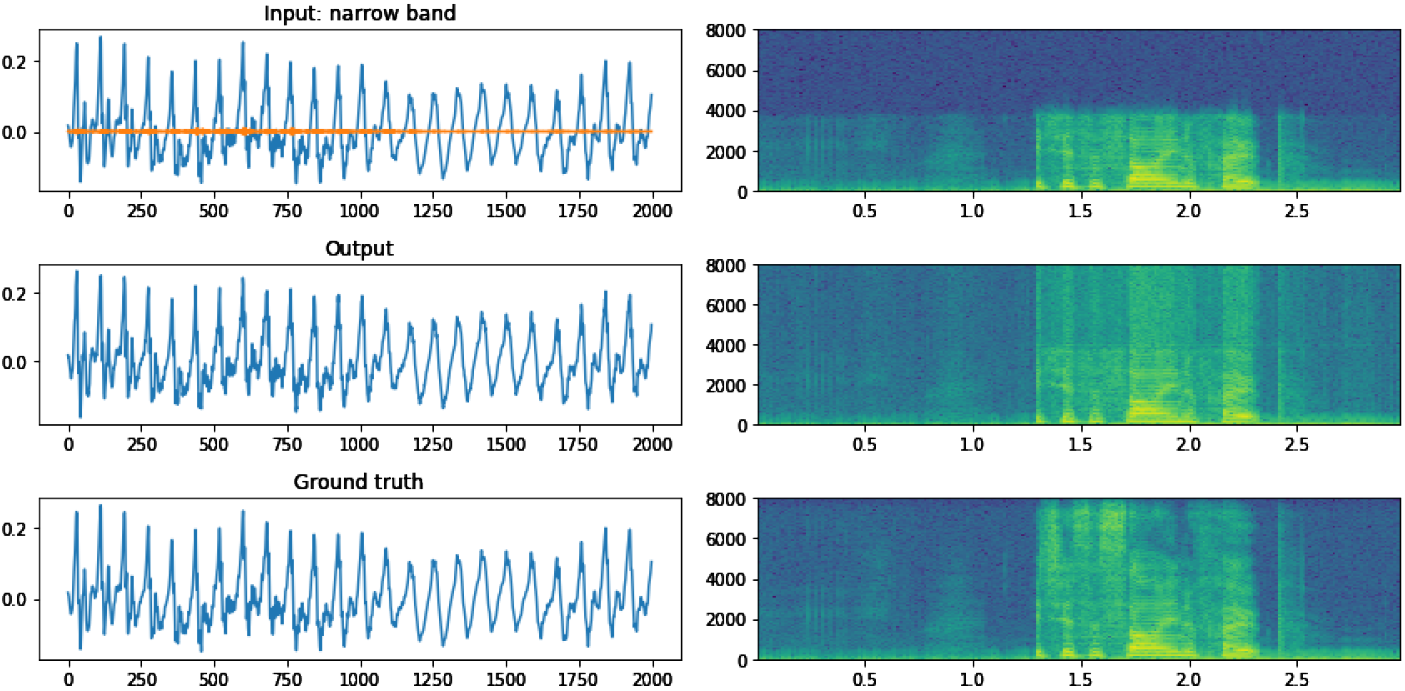
图9:基线HRNN输出波形和频谱图与输入和接地真值比较。橙色线表示窄带输入和宽带ground truth之间的差异。
HRNN+Spec:图10显示了HRNN+Spec的一个示例输出。低频带和高频带频率之间的差异比基线稍平滑一些。图12和13比较了HRNN基线和HRNN+Spec低频带和高频带频率谱平滑边界的能力。该模型在静默状态下也表现得更好;基线过高估计了静默期间的高频带能量,而HRNN+Spec模型更接近于ground truth。然而,在发声部分,仍然存在过度平滑。结果表明,估计一个音素中泛音的强度是困难的,因此该模型似乎保守地估计整个高频范围内的均匀能量。
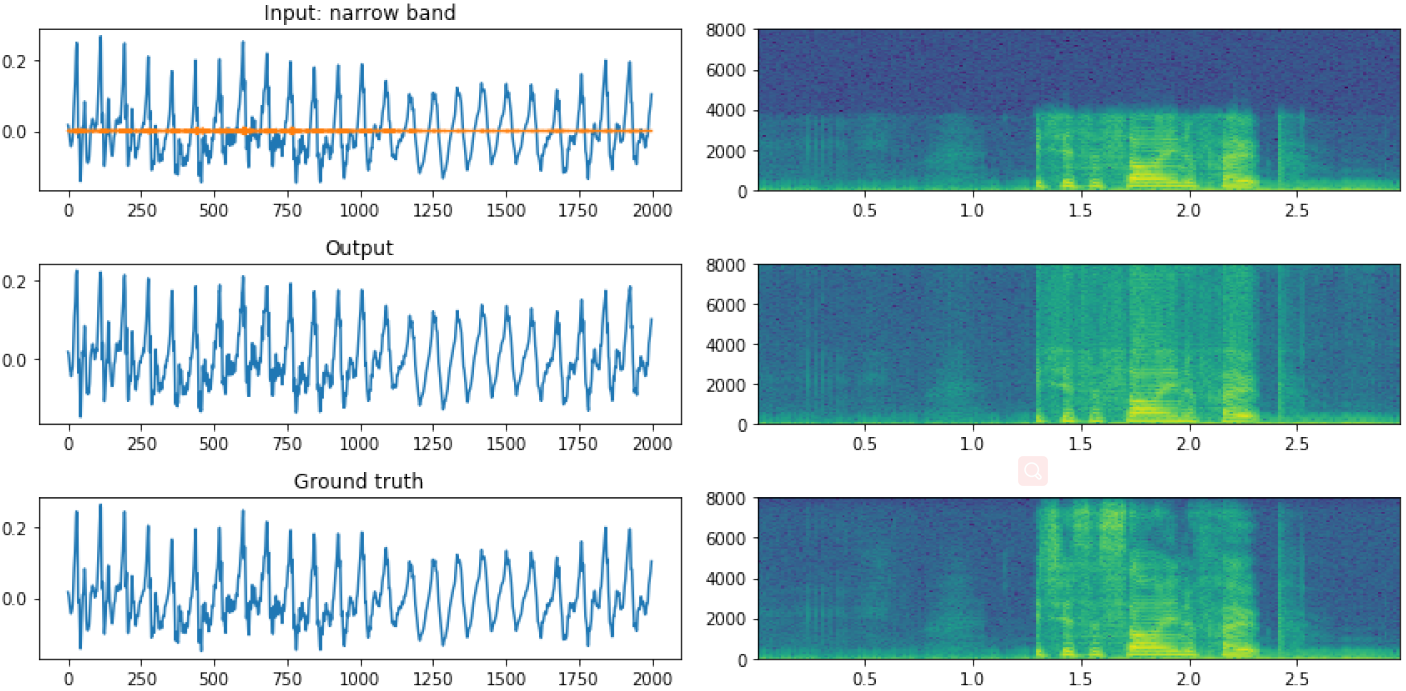
图10:HRNN+Spec输出波形和频谱图与输入和ground truth的比较。
HRNN+GAN:尽管很难将对抗损失降到最低,但HRNN+GAN的结果与HRNN+Spec相当,优于HRNN基线。如图11所示,HRNN+GAN不会像HRNN+Spec那样对上频带进行过平滑处理,但它也会对语音的某些部分的能量进行反转。例如,在图11所示的示例录音进行到一半时,HRNN+GAN高估了音节开头的上频带能量,但低估了浊音部分的上频带能量。由于过平滑较少,由HRNN+GAN生成的频谱在视觉上更为逼真,但与ground truth相比,我们发现该模型遗漏了一些原始的高频。对抗性损失当然还有改善的余地。
7.3.定量结果
我们将HRNN基线、HRNN+Spec和HRNN+GAN的性能与线性插值和三次样条插值两种非学习型方法的性能进行了比较。我们使用平均绝对差与ground truth和平均对数谱距离(LSD)的度量来测量精度。我们对单说话人验证集进行了评估。表2和表3比较了不同方法的这些指标。注意,绝对差值远低于训练中的差,因为我们对-1.0和1.0之间的mu-law解码样本值进行评估,而在训练过程中,损失是由0和255之间的mu-law编码的量化值计算出来的。

图11:HRNN+GAN输出波形和频谱图与输入和ground truth的比较。输出高估了能量,但似乎接近正确的比例能量。

(a)100步 (b)200步
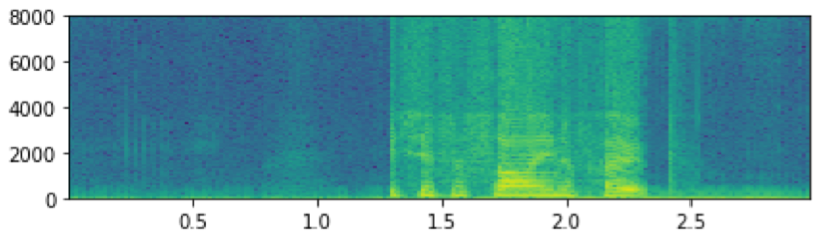
(c)300步
图12:HRNN+Spec频谱图在前300步训练中的输出进度。在步骤100和200中,在低频和高频之间有一条清晰的线。在第300步,当模型平滑从低频带过渡到高频带时,线条开始消失。
我们发现,通过对数谱距离,我们的方法大大优于插值基线,这表明我们的方法产生的结果更加直观、真实。所有的模型都是以绝对差分的方式执行的。重要的是,输出波形和地面真值波形之间的绝对差异并不总是反映它们的感知相似性。在图8中,我们看到我们的方法产生的光谱图比插值方法更具视觉说服力。因此,我们认为LSD是一个更好的感知质量的度量。
(a)步骤100(b)步骤200
(c)步骤300
图13:培训前300步的基线HRNN谱图输出进度。与HRNN+规范相比,基线模型在频谱的下半部分和上半部分之间产生更明显的能量差异。
HRNN+GaN在基线上同时通过绝对差分和LSD得到改善。这意味着对抗性损耗会促使网络预测更精确的波形样本,从而产生更真实的频率内容。HRNN+SPEC在光谱距离上优于其他所有方法,这证明了显式光谱损失的有效性。
| 模型 |
损失 |
| 线性插值 |
0.00188 |
| 三次样条插值 |
0.00239 |
| HRNN基线(我们的) |
0.00249 |
| hrnn+规格(我们的) |
0.00319 |
| hrnn+gan(我们的) |
0.00247 |
表2:平均绝对差。
| 模型 |
损失 |
| 线性插值 |
0.24256 |
| 三次样条插值 |
0.71407 |
| HRNN基线(我们的) |
0.16217 |
| hrnn+规格(我们的) |
0.09444 |
| hrnn+gan(我们的) |
0.15770 |
表3:平均LSD。
8. 结论
我们提出的HRNN架构和感知损失在音频超分辨率任务上实现了令人印象深刻的性能。基线会产生可接受的听力结果,加上知觉丧失会鼓励更具知觉说服力的输出。具体来说,频谱损失将输出与地面真值之间的频谱距离最小化,而对抗性损失则鼓励感知现实的输出,而不管地面真值如何。由于对抗性损失提高了波形级别的性能,频谱损失提高了频谱级别的性能,因此是时间域和频率域中超分辨率模型音频的最佳方法。我们相信,我们对感知损失的建议可能会改善任何音频生成模型,重复或前馈。
在研究RNN的性质时,我们发现我们的方法容易受到RNN的一些常见缺点的影响。我们注意到结果过于平稳,遇到了序列长度大于520个样本的训练网络问题。我们相
信,更复杂的感知损失和训练模式,以及生成更长序列的更好方法,可以缓解这两个问题。
我们的结论是,我们成功地开发了一个强大的基线HRNN方法,并改善了基线与知觉损失。我们相信增加感知损失不仅提高了性能,而且增加了可解释性和透明度,因为它清楚地定义了模型的目标。
9. 未来的工作
未来的工作包括改进HRNN+GAN训练方案,更好地平衡发电机鉴别器的收敛速度,更明确地调节地面真实情况下的敌方损失。也需要一种更好的方法来生成更长的音频序列。这可能需要制定一种好的“修补”方法,将短序列缝合成长波形。这将使模型不是端到端的,但它可能允许HRNN在更小的序列上训练,这将减轻过度平滑。另一种解决方案是允许HRNN对较长的序列进行训练。一个音素的长度至少是2000个样本,但是超过2000个样本的序列长度会在训练过程中引起记忆问题,而且大多数RNN不能精确地为这许多时间步建模时间序列。改进HRNN+GAN训练方案和生成长序列的方法将显著改善我们提出的方法。
我们提出的模型可以很容易地扩展到多扬声器数据。虽然我们对整个VCTK数据集进行了许多实验,但是将模型扩展到许多声音需要进一步的工作。
我们鼓励探索其他知觉损失。正如本文前面所讨论的,无论是在时间域还是在频率域,都有多种接近音频超分辨率的方法。最佳的知觉损失反映了实际的听力体验,并鼓励自然发声的音频。
确认
感谢我的顾问亚当·芬克尔斯坦在整个项目中的宝贵支持。也感谢金泽瑜、苏佳奇和埃德勒,他们总是愿意回答问题(不管他们多么愚蠢),并分享他们的专业知识。我感谢普林斯顿大学计算机科学系和工程与应用科学学院提供学术、财政和道德支持。
荣誉守则
我保证我的荣誉,这篇论文代表我自己的工作,符合大学的规定。