降维
降维(dimensionality reduction)作为课程中所讲的第二种无监督学习方法。
降维的定义及作用一:数据压缩
我们假设一个数据集有很多特征,我们提取其中的两个,一个是物体的厘米长度,一个是物体的英寸长度。这其实是一种高度冗余的表现。那么我们可以将2D转化为1D。
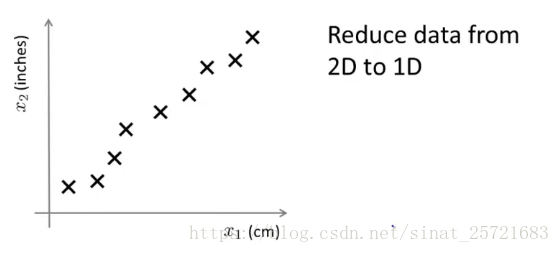
为什么上图的例子并不是一条直线:因为四舍五入到cm或者英寸。
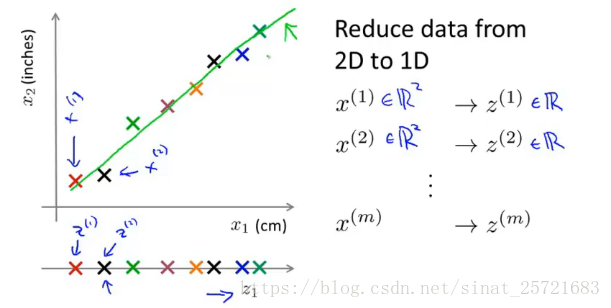
我们将x1和x2降维成z1,原来每个样本点的维度是2维,现在变成了1维。
下面介绍另一个例子:从3D到2D
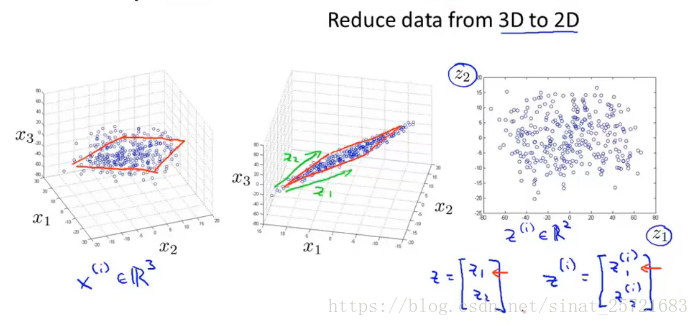
在左图中,数据基本上分布在一个平面上(一个斜着的平面,图中不容易看出来),我们将其投影到该平面上,形成中图,然后重新构建坐标轴z1,z2,形成右图。此时我们就实现了3D转2D。
通过这种方式我们可以进行数据压缩,降低在内存或者存储空间上的需求。另也可以加快学习算法的速度,这是更有趣的一个应用。
降维作用二:数据可视化
依然从例子入手:
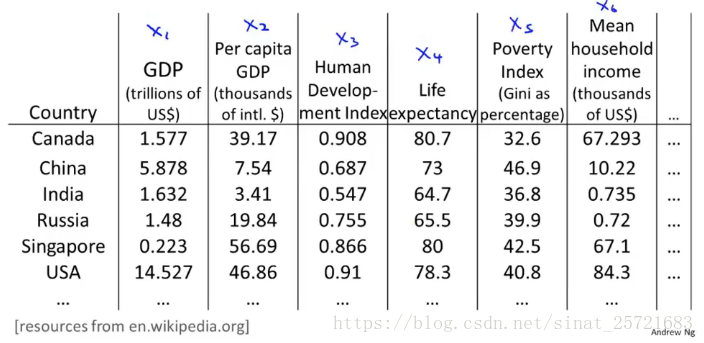
这里是国家数据集的一些特征,有50维,我们难以将其在坐标轴上显示出来。但是如果我们通过降维到2维,就可以轻易的显示出来:
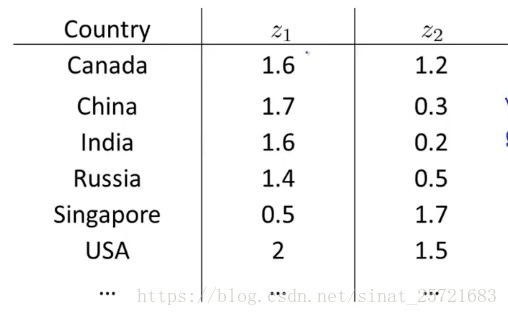
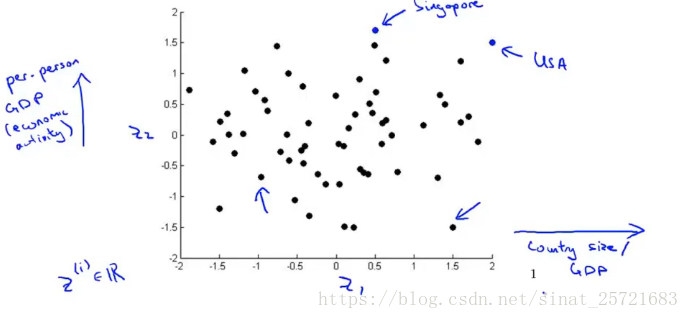
横轴表示国家的经济活跃程度(GDP)或者规模大小,纵轴表示个人的经济活跃程度或者幸福感等。分析上图可以发现,右上角的点USA国家和个人的经济活跃程度都很高。上面的点Singapore个人GDP很高,但是由于这个国家比较小,所以国家GDP较低。等等
降维算法:主成分分析(PCA)
主成分分析(principal components analysis)是降维问题中最流行最常见的一种算法。
假设我们有一个二维的数据集:
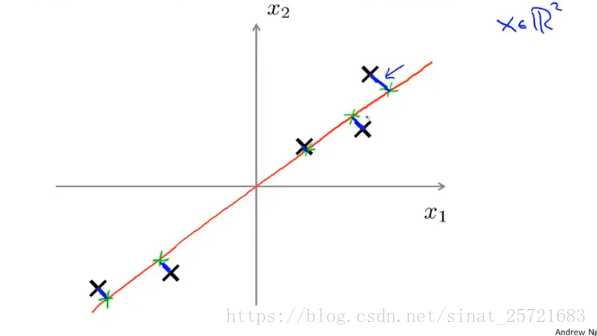
我们希望找到一条红色的线,使得二维数据映射到一维上并且使蓝色的线段长度(投影误差)平方最短。
PCA不等于线性回归
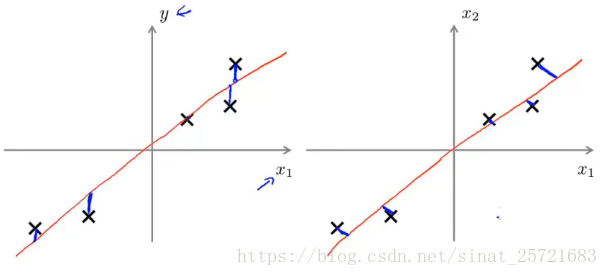
在线性回归中,我们最小化的是预测值与y之间的平方误差,即左图中的样本和红线之间在y轴上的距离。而在PCA中,我们最小化的是样本和横线之间距离的平方误差,是指映射到横线上所产生的误差。
PCA所做的事情就是找到一个低维的平面来对数据进行投影,以便最小化投影误差的平方,以及最小化每个点与其投影点距离的平方。
数据预处理
在运行PCA算法之前,我们要先进行数据预处理:

要进行的预处理过程是均值标准化或者特征缩放。
对于均值标准化过程,我们先计算每个特征的均值,然后用每个特征减去均值构造新的特征,这将使得每个特征的均值刚好为0。
然后,如果特征之间有差别很大的范围,则需要进行特征缩放到一个相对的价值范围。
简单数学推导
我们将数据从n维降到k维。
首先要做得是计算协方差矩阵
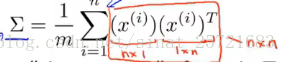
计算协方差矩阵的方法可以用svd(奇异值分解)。
其中U是n*n的矩阵,我们获取U的前k列,得到一个n*k的矩阵,我们称之为 矩阵。

我们将使用这个矩阵对数据进行降维:
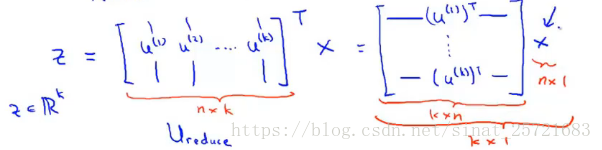
是n*k维矩阵,x是n*1维矩阵,所以z为K*1维矩阵,即我们想要得到的降维后的数据。
(这里的证明超出了课程要求)

压缩重现

这里我们可以用
来近似表示x,完成压缩重现的过程
在重现的过程中,99%的方差被保留表示的是:投影的均方误差除以数据总方差不会超过1%。
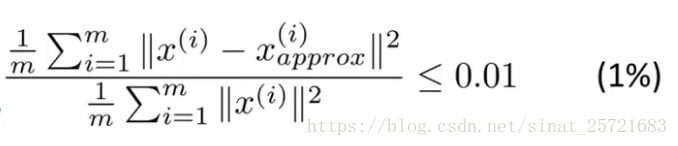
如何选择主成分数量k


运用PCA
在传统的逻辑回归任务中,如果样本点x的维度过高,速度会很慢,我们可以通过PCA进行降维来提高运行逻辑回归的速度。
这是之前提到过的运行PCA可以提高学习算法的速度的一种应用。
PCA的错误使用——来防止过拟合
使用z来代替x降维,特征数少了,更少可能过拟合。
这可能会产生一定的效果,但是不推荐这样去做。我们使用正则化来代替这种错误方法,正则化的效果更好。