开始之前,先讲一个故事
A国家里面,有甲、乙2个人,他们想在电脑上显示字符‘a’,甲认为用0101010来表示a,乙认为用1010101,A国家为了解决这个问题,有关部门经过研究自己所有用过的128字符,制定一个规则,认为用7位就可以表示所有的字符,并且认为a应该用1100001表示。
无独有偶,B和C国家有同样的问题,但是B国家不止127字符而是256,并且包含A国家的128个字符,同时又想保持能和A国家一样,所以B国家想到用8位来表示,以前的127字符的最高位置0,形成8位,其他的字符用128-255(0x80-0xFF)编码。C国家就不止255个字符,而是有几万个字符,所以想到用2个字节,16位来表示一个字符,并且也和B一样,保持前128字符不变,后面的所有字符都用2个字节表示。
A和B、A和C打交道都没问题, 对于A来说,一切都很和谐,但是B和C就有问题了,因为C没有B中128-255那些字符,B仅仅只有256个字符,于是为了大家都可以交流无障碍,所以就指定一个通用的规则,可以表示A、B、C国家的所有字符,通用的规则是想能表示全世界所有的字符,目前全世界超过137000个字符,所以2个字节不能做到了,于是就考虑4个字节。
用4个字节表示所有字符,好像很完美,所有字符都可以表示了,这个时候,A、B、C国家不开心了,A说:我以前1k内存可以存1024个字符,现在只能存256字符,这是多么大的资源浪费。
针对这个情况,想到了一个比较nice的办法,就是某些字符用一个字节,某些字符用2个字节,就是用一种可变长的编码
看完上面的故事,我们再来对号入座一下,但是首先要知道字符集和字符编码2个概念
字符集:所有字符的集合
字符编码:某个字符在电脑存储时的字节序,某一个字符集一般都会对应一套字符编码
A国家指的是美国,128个字符是ASCII字符集,包括不可显示的控制字符和可显示字符,用8位,7位表示字符,最高位置0,用ASCII编码
B国家指的是欧洲地区,256字符,实际没有这么多,这个是用ISO-8859-1字符集,用ISO-8859-1编码
C国家指的是我国,gbk字符集,gbk编码,用的也是可变长编码,前128个字符是1个字节,汉字2个字节
统一规则是Unicode编码,Unicode字符集包含世界所有的字符,上面想到的一个比较和谐的字符编码是对Unicode字符集的一种最受欢迎的实现utf-8,实现规则如下

Unicode还有其他2种实现方式,utf-16和utf-32,一个是用16位,一个用32位,目前来看,这2种和utf-8比较,都落入下风。
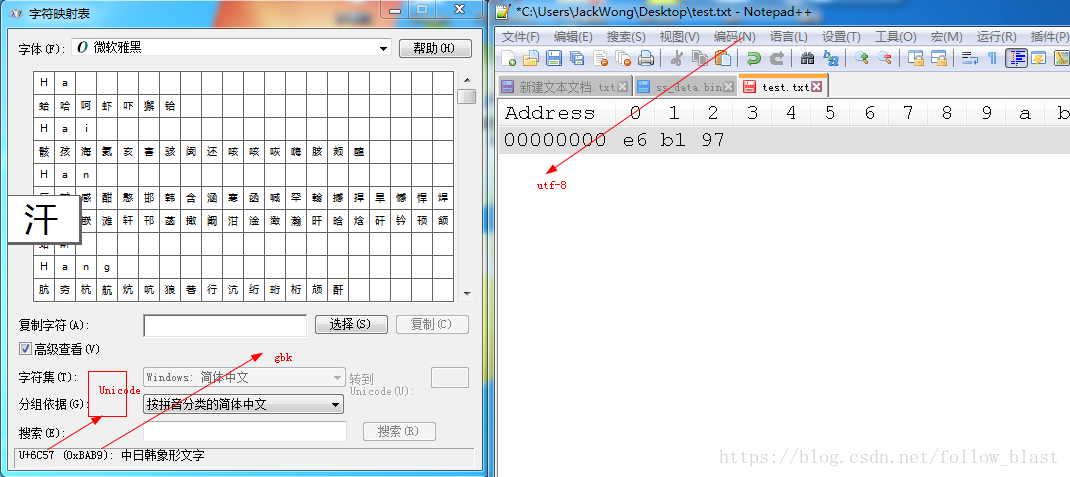
可以看到上面图,左边的图可以在Windows-》控制面板-》字体-》查找字符打开,右边是使用notepad++,利用notepad++可以用不同的编码存储,notepad++需要装一个查看16进制的插件
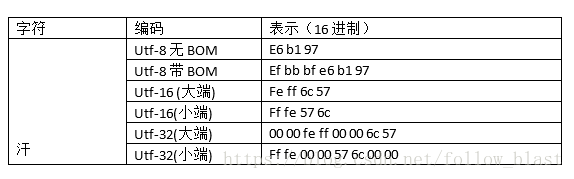
汗这个中文字的unicode是6c 57,utf-8是e6 b1 97,根据转换规则看一下
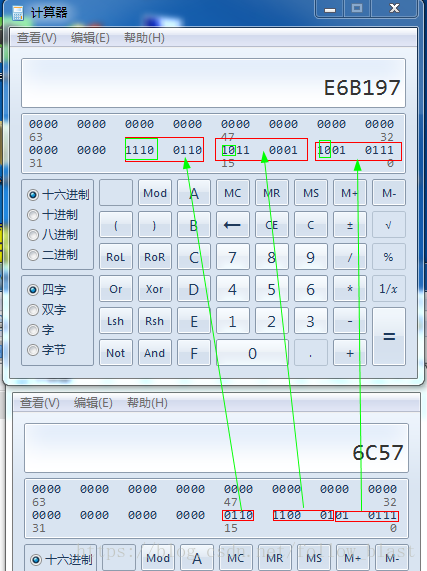
完全符合这个规则
Windows是采用Unicode编码,不同的语言采用不同的代码页进行适应。假如你来一个gbk编码的字符,它就会去找简体中文这个代码页,找到了,就转换成Unicode。
这里面还涉及到一个字节序的问题byte-order mark(BOM)
同时我们还有可能看到ISO-8859-2、ISO-8859-3等ISO-8859系列标准,这个系列是完全和ASCII兼容的,所以前128个字符不能动,其他定义一些扩展字符,用8位表示的,所以一共最多256个字符
有可能还看到Windows-1252 Windows-1253等,这些是Windows针对某一地区采用的字符编码,例如gbk对应Windows中936代码页也就是windows-936
出现乱码的情况:就是我用a规则编码,你用b规则是解码,这样肯定会出现乱码,但是有些是因为我们没有a规则代码页,这个时候需要自己去添加,或者自己写一段代码去转换成自己系统的内码,当然内码的字符集里面肯定要存在这个字符才行
还有在Windows下的记事本工具的时候,存储的时候,有一个编码选项,叫ansi编码,这个千万不要理解为ascii编码
ANSI编码是不同国家和地区的编码,例如你用的简体中文版的Windows,就是gbk