说是有选择和循环分支,,也实在没有什么比较大的坑要注意的,所以就直接进入比较令人困扰的地方
unicode和字符串
这个地方是一直以来我比较头痛的地方,因为坑比较多而且python3和python2在编码和解码方面有着很大的差异,所以我尽量按照自己的理解写一遍,如果有谬误望不吝赐教。
先安利一个资料 https://docs.python.org/2/library/re.html 这里讲解的比较详尽
先来谈谈对编码的理解吧
首先我们要明析两个东西
1.unicode
2.编码方式
这里借一篇文章中的一段话来解释,原文讲的很清晰,建议大家去看一看:https://pycoders-weekly-chinese.readthedocs.io/en/latest/issue5/unipain.html
我们从 Unicode 基本知识开始。
事实之一:计算机中的一切均为 bytes(字节)。硬盘中的文件为一系列的 byte 组成,网络中传输的只有 byte。所有的信息,在你写的程序中进进出出的,均由 byte 组成。
孤立的 byte 是毫无意义的,所以我们来赋予它们含义。
为了表示各种文字,我们有大约 50 年的时间都在用 ASCII 码。每一个 byte 被赋予 95 种符号的一种,所以,当我给你发送 byte 值为 65 的时候,你知道我想表达一个大写的 A。
ISO Latin 1,或者 8859-1 对 ASCII 的 96 种字符进行了扩展。这也许是你用一个 byte 可以做的最多的事情了。因为 byte 中没有容量可以存储更多的符号了。
在 Windows 中增加了另外 27 种字符,这种叫做 CP1252 编码。
事实之二是,世界上的字符远远比256个要多。一个简单的byte不能够表达世界范围内的字符。在你玩”编码打地鼠”的时候,你多么的希望世界上所有的人都说英语,但是事实并不是这样,人们需要更多的符号来交流。
事实一和二共同造成了计算机设备结构与世界人类需求的一个冲突。
当时为了解决冲突尝试了多种途径。通过一个 byte 来与符号或者字符进行对应的编码,每一种解决途径都没有解决事实二中的实质问题。
当时有很多一个 byte 的编码,都没有能够解决问题。每一个都只能解决人类语言的一部分。但是他们不能解决所有的文字问题。
人们开始创造两个 byte 的字符集,但是仍然像碎片一样,只能够服务于不同地域的一部分人。
当时产生了不同的标准,讽刺的是,他们都不足以满足所有的符号的需求。
Unicode 就是为了解决之前的老的字符集问题。Unicode 分配整形,被成为代码点( UNICODE 的字符被成为代码点( CODE POINTS )用 U 后面加上 XXXX 来表现,其中, X 为16进制的字符)来表示字符。它有 110 万的代码点,其中有十一万被占用,所以它可以有很多很多的空间可供未来的增长使用。
Unicode 的目的是包含一切,它从 ASCII 开始,包含了数以千计的代码,包含这著名的—-雪人??,包含了世界上所有的书写系统,而且一直在被扩充。比如,最新的更新中,就有一大堆没用的词汇。
这里有六个的异国 Unicode 字符。 Unicode 代码点写成 4- , 5- ,或者 6 位的十六进制编码,同时有一个 U 的前缀。每一个字符都有一个用 ASCII 字符规定的名称。
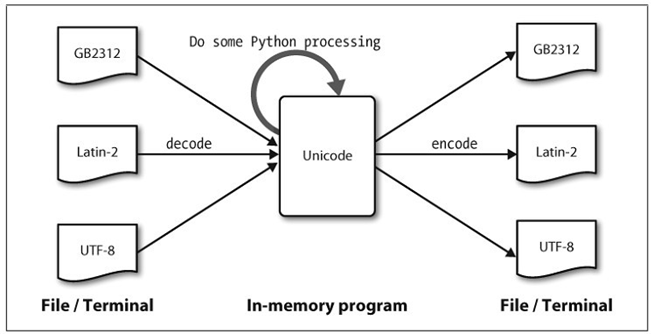
所以说 Unicode 提供了所有我们需要的字符的空间。但是我们仍然需要处理事实一中所碰到的问题:计算机只能看懂 bytes 。我们需要一种用 bytes 来表示 Unicode 的方法这样才可以存储和传播他们。
Unicode 标准定义了多种方法来用 bytes 来表示成代码点,被成为 encoding 。
UTF-8 是最流行的一种对 Unicode 进行传播和存储的编码方式。它用不同的 bytes 来表示每一个代码点。ASCII 字符每个只需要用一个 byte ,与 ASCII 的编码是一样的。所以说 ASCII 是 UTF-8 的一个子集。
这里我们展现了几个怪异字符的 UTF8 的表示方法。 ASCII 字符 H 和 I 只用一个 byte 就可以表示。其他的根据代码点的不同使用了两个或者三个 bytes 。尽管有些并不常用,但是一些代码点使用到四个 bytes。
至此,我们大致明白了unicode和编码方式的关系,即每个字符都会有一个unicode码,但是为了节省计算机储存空间,当大多数的字符不被用到时,便使用各种编码方式减少字符在计算机中储存的长度来增加效率。
python2中的编码解码规则
Python 2.7中,字符串分为str和unicode两种
Python 2.7中,str表示8位文本(8-bit string)和二进制数据;unicode表示Unicode文本
所以在python2中,对一个string通过decode方法可以将其转化为unicode对象,而一个unicode对象可以通过encode来编码成一个string(二进制数据或者八位文本)当然要表明解码编码的方式(如utf-8或ascii)两者关系如图

当然,在python2中是可以对string使用encode的,也可以对unicode使用decode,但很不建议这么做
不要对str对象使用encode(),不要对unicode对象使用decode()
str.decode()和unicode.encode()是正规的用法
再给张图加深理解
python3
python3中不再有unicode类型
str类型支持Unicode,或者说Python3.5中的str类型就相当于Python 2.7中的unicode类型
Python 3.5中的str类型相当于Python 2.7中的unicode类型,表示Unicode string,自然没有decode()方法
Python 2.7 包括两种数据类型:str 和 unicode
Python 3.5 相对应的数据类型:bytes 和 str
在Python 3.5中, “bytes” 类型存储的是 byte 串。可以通过一个字母 b 前缀来声明 bytes
可以简单理解为:
在 Python 2.7 中的 str 在 Python 3.5 中叫做 bytes
在 Python 2.7 中的 unicode 在 Python 3.5 中叫做 str
事实上还是记住前面那个图,,,,,
之后给出几点建议
我们有五个不可忽视的事实:
- 程序中所有的输入和输出均为 byte
- 世界上的文本需要比 256 更多的符号来表现
- 你的程序必须处理 byte 和 unicode
- byte 流中不会包含编码信息
- 指明的编码有可能是错误的
这是你在编程中保持 Unicode 清洁的三个建议:
- Unicode 三明治:尽可能的让你程序处理的文本都为 Unicode 。
- 了解你的字符串。你应该知道你的程序中,哪些是 unicode, 哪些是 byte, 对于这些 byte 串,你应该知道,他们的编码是什么。
- 测试 Unicode 支持。使用一些奇怪的符号来测试你是否已经做到了以上几点。
python中一些字符串的处理
几个格式化输出:
1、按照默认顺序,不指定位置 print("{} {}".format("hello","world") ) hello world 2、设置指定位置,可以多次使用 print("{0} {1} {0}".format("hello","or")) hello or hello 3、使用列表格式化 person = {"name":"opcai","age":20} print("My name is {name} . I am {age} years old .".format(**person)) My name is opcai . I am 20 years old . 4、通过列表格式化 stu = ["opcai","linux","MySQL","Python"] print("My name is {0[0]} , I love {0[1]} !".format(stu)) My name is opcai , I love linux !
一些常用函数
find( )、rfind()、index()、rindex()、count()
find()和rfind方法分别用来查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次和最后一次出现的位置,如果不存在则返回-1;
index()和rindex()方法用来返回一个字符串在另一个字符串指定范围中首次和最后一次出现的位置,如果不存在则抛出异常;
count()方法用来返回一个字符串在另一个字符串中出现的次数。
split()、rsplit()、partition()、rpartition()
split()和rsplit()方法分别用来以指定字符为分隔符,将字符串左端和右端开始将其分割成多个字符串,并返回包含分割结果的列表;
partition()和rpartition()用来以指定字符串为分隔符将原字符串分割为3部分,即分隔符前的字符串、分隔符字符串、分隔符后的字符串,如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串。
join()
>>> li=["apple", "peach", "banana", "pear"] >>> sep="," >>> s=sep.join(li) >>> s "apple,peach,banana,pear"
推荐使用join而不是使用+
lower()、upper()、capitalize()、title()、swapcase() 分别用来将字符串转换为小写、大写字符串、将字符串首字母变为大写、将每个单词的首字母变为大写以及大小写互换
例:
>>> s="What is Your Name?" >>> s2=s.lower() >>> s2 "what is your name?" >>> s.upper() "WHAT IS YOUR NAME?" >>> s2.capitalize() "What is your, name?" >>> s.title() 'What Is Your Name?' >>> s.swapcase() 'wHAT IS yOUR nAME?'
生成映射表函数maketrans()和按映射表关系转换字符串函数translate()
例:
>>> import string >>> table=string.maketrans("abcdef123","uvwxyz@#$") >>> s="Python is a greate programming language. I like it!" >>> s.translate(table) "Python is u gryuty progrumming lunguugy. I liky it!" >>> s.translate(table,"gtm") # 第二个参数表示要删除的字符 "Pyhon is u ryuy proruin lunuuy. I liky i!"
center()、ljust()、rjust()
返回指定宽度的新字符串,原字符串居中、左对齐或右对齐出现在新字符串中,如果指定宽度大于字符串长度,则使用指定的字符(默认为空格)进行填充
例:
>>> 'Hello world!'.center(20) ' Hello world! ' >>> 'Hello world!'.center(20,'=') '====Hello world!====' >>> 'Hello world!'.ljust(20,'=') 'Hello world!========' >>> 'Hello world!'.rjust(20,'=') '========Hello world!'
之后关于正则表达式内容过多这里就不列出了,有兴趣可以看看re模块的资料