一、java中需要编码的场景
前面描述了常见的几种编码格式,下面将介绍java中如何处理对编码的支持,什么场合中需要编码。
1、I/O操作中存在的编码
我们知道涉及编码的地方一般都在字符到字节或者字节到字符的转换上,而需要这种转换的场景主要是I/O,这种I/O包括磁盘I/O和网络I/O,图2-1是java中处理I/O读问题的接口。
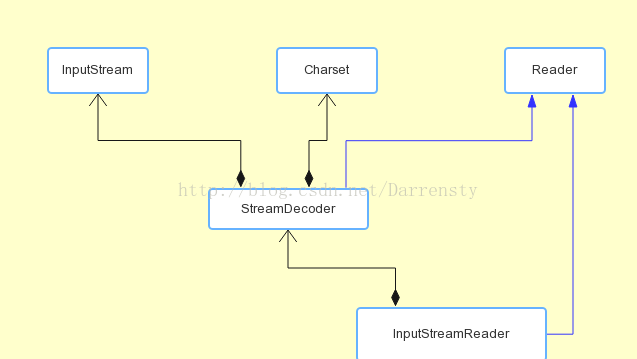
Reader类是java的I/O中读字符的父类,而InputStream类是读字节的父类,InputStreamReader类就是关联字节到字符的桥梁,它负责在I/O过程中处理读取字节到字符的转换,而具体字节到字符的解码实现它又委托StreamDecoder去做,在StreamDecoder解码过程中必须由用户指定Charset编码格式。值得注意的是,如果你没有指定Charset,将使用本地环境中的默认字符集,如在中文环境中将使用GBK编码。
写的情况也类似,字符的父类是Writer,字节的父类是OutPutStream,通过OutputStreamWriter转换字符到字节,如图。

同样StreamEncoder类负责将字符编码成字节,编码格式和默认编码规则与解码是一致的。
在我们的应用程序中涉及I/O操作时,只要注意指定统一的编解码Charset字符集,一般不会出现乱码问题。
2、内存操作中的编码
我们都知道在java开发中除了I/O涉及编码外,最常见的应该就是在内存中进行字符到字节的数据类型转换,java中用String表示字符串,所以String类就提供了转换到字节的方法,也支持将字节转换为字符串的构造函数(详细了解请看jdk的string源码)。
3、java中如何实现编解码
java中如何实现编码及解码呢?
首先根据指定的CharsetName通过Charset.forName(charsetName)找到Charset类,然后根据Charset创建CharsetEncoder对象,再调用charsetEncoder.encode对字符串进行编码,不同的编码类型都会对应到一个类中,实际的编码过程是在这些类中完成的下面举例。
如字符串“I am 君山”的char数组为49 20 61 6d 20 541b 5c71,下面把它按照不同的编码格式转换相应的字节。
3.1按照UTF-16编码
字符串“I am 可乐” 用UTF-16编码,编码结果如图2-3所示。

3.2几种编码格式的比较
对中文字符几种编码格式都能处理,GB2312与GBK编码规则类似,但是GBK范围更大,他能处理所有汉字字符,所以GB2312与GBK比较,应该选择GBK。UTF-16与UTF-8都是处理Unicode编码,它们的编码规则不太相同,相对来说UTf-16编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间的快速切换,如java的内存编码就采用UTF-16编码,但是它不适合在网络中传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,相比较而言UTF-8更适合网络传输,对ASCII字符采用单字节存储,另外单个字符损坏也不会影响后面的其他字符,在编码效率上介于GBK和UTF-16之间,所以UTF-8在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
下一篇将介绍java web中涉及的编解码
文章借鉴于 《In-depth analysis of java web insider》