很多网页的源代码和其实际的展示效果不一样,是因为有两段请求,除了我们向服务器发送的请求,还有该页面发送的ajax请求,是它把简单的原网页渲染成展示出来的效果。我们的目的就是实例化这个请求。
ajax请求的类型为xhr。
referer:ajax 请求的发送者
X-Request-With:XMLHttpRequest 这个属性标记该请求为ajax请求。
import requests
from urllib.parse import urlencode
from pymongo import MongoClient
#这里的target_url就是ajax请求的目标url,实际上是一个接口。
target_url='https://m.weibo.cn/api/container/getIndex?'
headers={
'Host':'m.weibo.cn',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
'Referer':'https://m.weibo.cn/u/123456789',
'X-Requested-With':'XMLHttpRequest'
}
client = MongoClient()
db = client['weibo']
collection = db['zdz']
def get_content(page):
params = {
'type':'uid',
'value':'123456789',
'containerid':'XXXXXXXXXXXXXX',
'page':page
}
url = target_url+urlencode(params)
return requests.get(url,headers=headers).json()
def page(content):
content = content.get('data').get('cards')
for item in content:
item=item.get('mblog')
result={}
result['id']=item.get('id')
result['attitude']=item.get('attitude_count')
result['comment']=item.get('comment_count')
result['text']=item.get('text')
yield result
def save_to_mongo(result):
collection.insert(result)
if __name__=='__main__':
for i in range(1,11):
content = get_content(i)
results=page(content)
for result in results:
print(result)
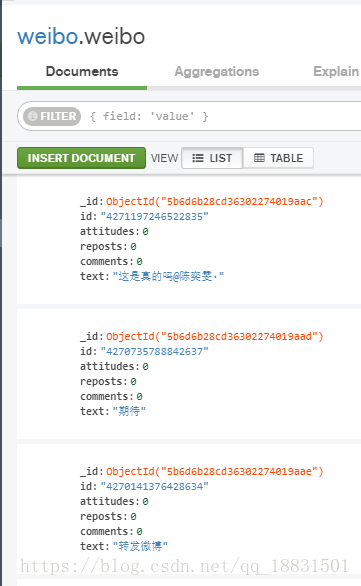
save_to_mongo(result)顺便把爬取的结果存在mongodb里,首先声明一个mongo的连接对象,然后指定存储的db和collection。