查看WebMagic文档:http://webmagic.io/docs/zh/posts/ch1-overview/
爬取网址需要翻墙: https://www.reddit.com/r/funny/
首先分析页面,随着我们拉下滚动条,XHR标签下面包含含有ajax的异步请求,需要靠经验来找,一般会有分页参数和关键词参数。
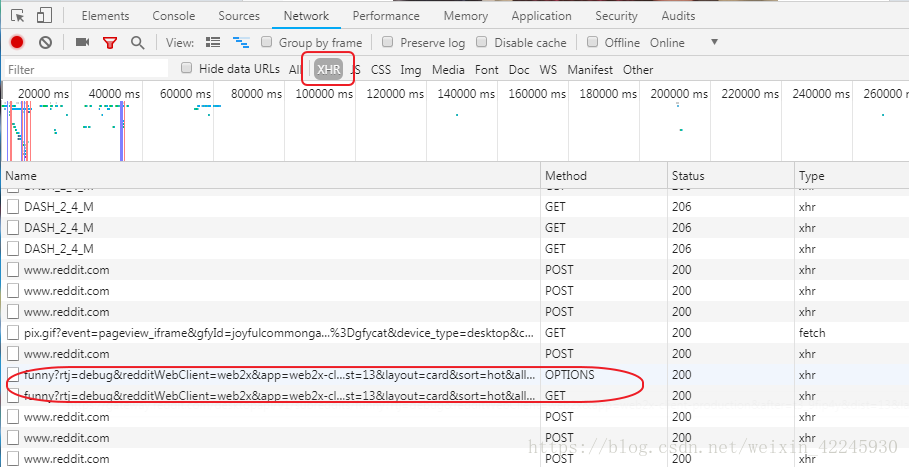
点击上面画圈的一个链接即可返回json数据。

分析下链接:
本来以为&dist=13是分页参数,其实不是,后来通过&after=t3_9fip4y 参数来获取新的数据,

获取上述json信息之后,下一步就是使用webmagic框架来爬取结果了。首先先导入jar包:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.6.1</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.6.1</version>
</dependency>
<!-- 下面两个jar是需要json解析的时候要依赖的,普通的html页面不用 -->
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
<version>0.9.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/net.minidev/json-smart -->
<dependency>
<groupId>net.minidev</groupId>
<artifactId>json-smart</artifactId>
<version>1.3.1</version>
</dependency>
先附上一张WebMagic的框架图:
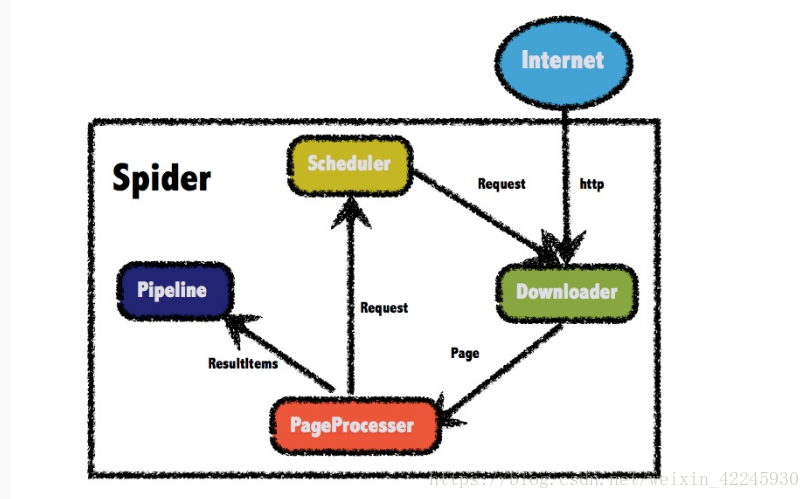
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
实现PageProcessor的代码如下:
// 页面处理器 实现PageProcessor即可
public class ProcessorMEMES implements PageProcessor {
private static int COUNT = 1;
private static Logger logger = Logger.getLogger(ProcessorMEMES.class.getName());
private Site site = Site.me().setSleepTime(6000);
//处理数据的方法
public void process(Page page) {
try {
List<String> urlList = new ArrayList<String>();
List<String> titleList = new ArrayList<String>();
List<String> bannerList = new ArrayList<String>();
// 解析页面规则
String name = SourceSite.SITE_MEMES;
page.putField("name", name);
Source source = FetchSource.getSource(name);
int fetSize = source.getFetchSize();
if (fetSize >= COUNT) {
// 由于是json格式的数据,这里采用JsonPathSelector专门处理
// 具体语法可以参照:https://blog.csdn.net/weixin_37794119/article/details/81484885
List<String> selectList = new JsonPathSelector("$.postIds").selectList(page.getRawText());
// 这里拿到相关的数据 先放到page对象里面
if (selectList!= null && selectList.size() > 0) {
for (int i = 0; i < selectList.size(); i++) {
String string = selectList.get(i);
String oneImage = new JsonPathSelector("$.posts." + string).select(page.getRawText());
JSONObject dataJson = new JSONObject(oneImage);
if (!dataJson.has("preview")) {
continue;
}
String url = new JsonPathSelector("$.posts." + string + ".preview.url").select(page.getRawText());
if (StringUtils.isNotBlank(url)) {
String title = new JsonPathSelector("$.posts." + string + ".title").select(page.getRawText());
if (!urlList.contains(url)) {
urlList.add(url);
titleList.add(title);
COUNT++;
}
}
}
//这步是页面的下一次请求,每次请求完拿到数据后下一次请求则根据这个url
page.addTargetRequest("https://gateway.reddit.com/desktopapi/v1/subreddits/funny"
+ "?rtj=debug&redditWebClient=web2x&app=web2x-client-production&t=all" + "&after="
+ selectList.get(selectList.size() - 1)
+ "&sort=top&layout=card&allow_over18=&include=");
}
page.putField("urls", urlList);
page.putField("titles", titleList);
}
} catch (Exception e) {
logger.info("download picture error ===> " + e);
}
}
public Site getSite() {
return site;
}
接下来就是处理结果集
// 处理最后的持久化操作,或者业务操作 实现Pipeline即可
public class PipelineDao implements Pipeline {
private static Logger logger = Logger.getLogger(PipelineDao.class.getName());
@Override
public void process(ResultItems resultItems, Task task) {
String name = "";
String url = "";
String title = "";
try {
File file = new File("E:\\1-100");
FileUtils.forceMkdir(file);
file = new File("E:\\101-200");
FileUtils.forceMkdir(file);
file = new File("E:\\201-300");
FileUtils.forceMkdir(file);
file = new File("E:\\301-400");
FileUtils.forceMkdir(file);
file = new File("E:\\401-500");
FileUtils.forceMkdir(file);
file = new File("E:\\501-600");
FileUtils.forceMkdir(file);
file = new File("E:\\601-700");
FileUtils.forceMkdir(file);
file = new File("E:\\701-800");
FileUtils.forceMkdir(file);
file = new File("E:\\801-900");
FileUtils.forceMkdir(file);
file = new File("E:\\901-1000");
FileUtils.forceMkdir(file);
// 获取抓取的资讯信息 resultItems.get() 可以获取之前保存在page上的值
List<String> urlList = resultItems.get("urls");
List<String> titleList = resultItems.get("titles");
// name = resultItems.get("name");
int numbers = urlList.size();
if (CollectionUtils.isNotEmpty(urlList)) {
for (int i = 0; i < numbers; i++) {
url = urlList.get(i);
title = titleList.get(i);
String savaPath = "";
if ( new File("E:\\1-100").listFiles().length < 100) {
savaPath = "E:\\1-100";
} else if (new File("E:\\101-200").listFiles().length < 100) {
savaPath = "E:\\101-200";
} else if (new File("E:\\201-300").listFiles().length < 100) {
savaPath = "E:\\201-300";
} else if (new File("E:\\301-400").listFiles().length < 100) {
savaPath = "E:\\301-400";
} else if (new File("E:\\401-500").listFiles().length < 100) {
savaPath = "E:\\401-500";
} else if (new File("E:\\501-600").listFiles().length < 100) {
savaPath = "E:\\501-600";
} else if (new File("E:\\601-700").listFiles().length < 100) {
savaPath = "E:\\601-700";
} else if (new File("E:\\701-800").listFiles().length < 100) {
savaPath = "E:\\701-800";
} else if (new File("E:\\801-900").listFiles().length < 100) {
savaPath = "E:\\801-900";
} else if (new File("E:\\901-1000").listFiles().length < 100) {
savaPath = "E:\\901-1000";
}
ImageHttpsDownloader.fetchContent(url, savaPath + "\\" + title + "_imageflag.jpg");
}
}
} catch (Exception e) {
logger.info("抓取失败,url: ====> " + url + " title: ======>" + title);
}
}
}
最后只要在main方法里运行一下
Spider.create(new ProcessorMEMES()).addUrl("初始访问URL").addPipeline(daoPipeline).run(); // daoPipeline是PipelineDao的实例;