pyspider框架之记录1
- 由于公司业务需求,目前做的爬虫就是爬取全国各个政府发布的各种政策,平时写的代码,没有多少想写成博客的,后续可能都会写出来,今天遇到了一个政府网站采用了ajax异步更新技术,那就做个记录吧。。
- 目标政府的url地址为http://www.hangzhou.gov.cn/col/col1255929/index.html。
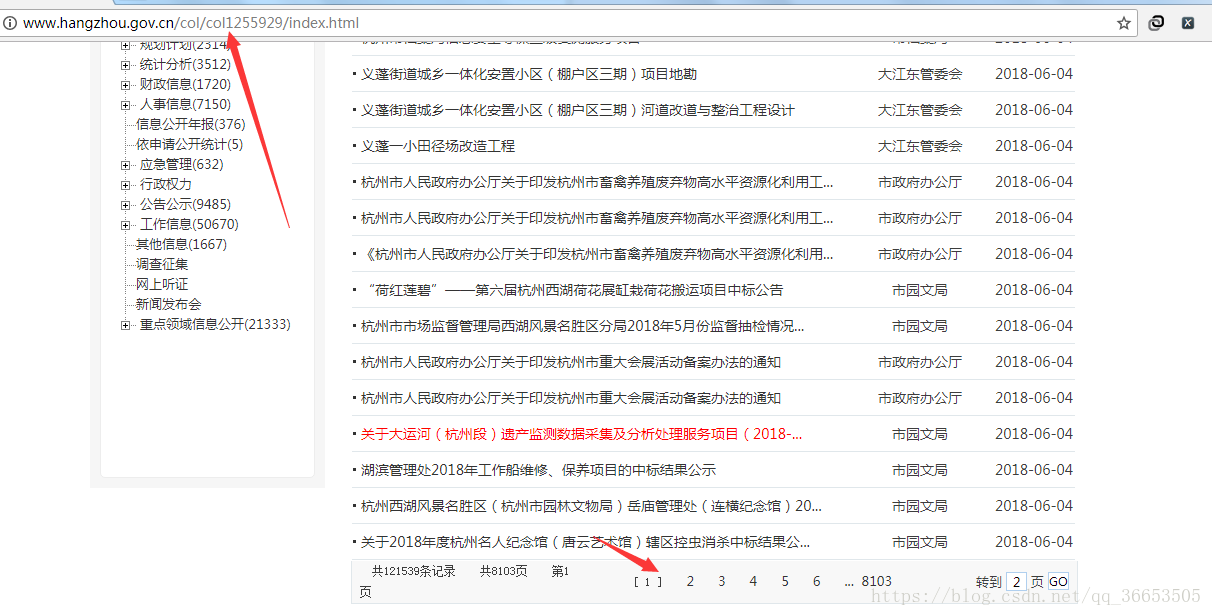
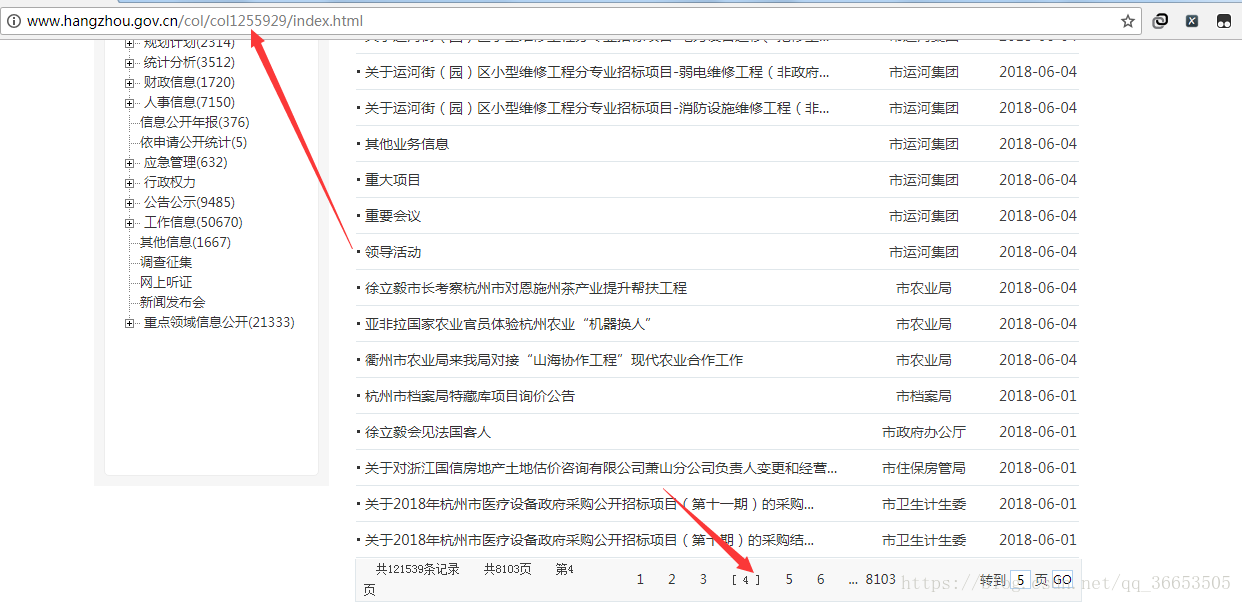
- 首先网页进行简单分析,因为目标网站存在多页的情况的,一般情况,进行翻页,上边地址栏的url地址会跟着翻页跳转发生有规律的变化,但是此网站不是这样,因为采用了ajax异步更新技术。如下图
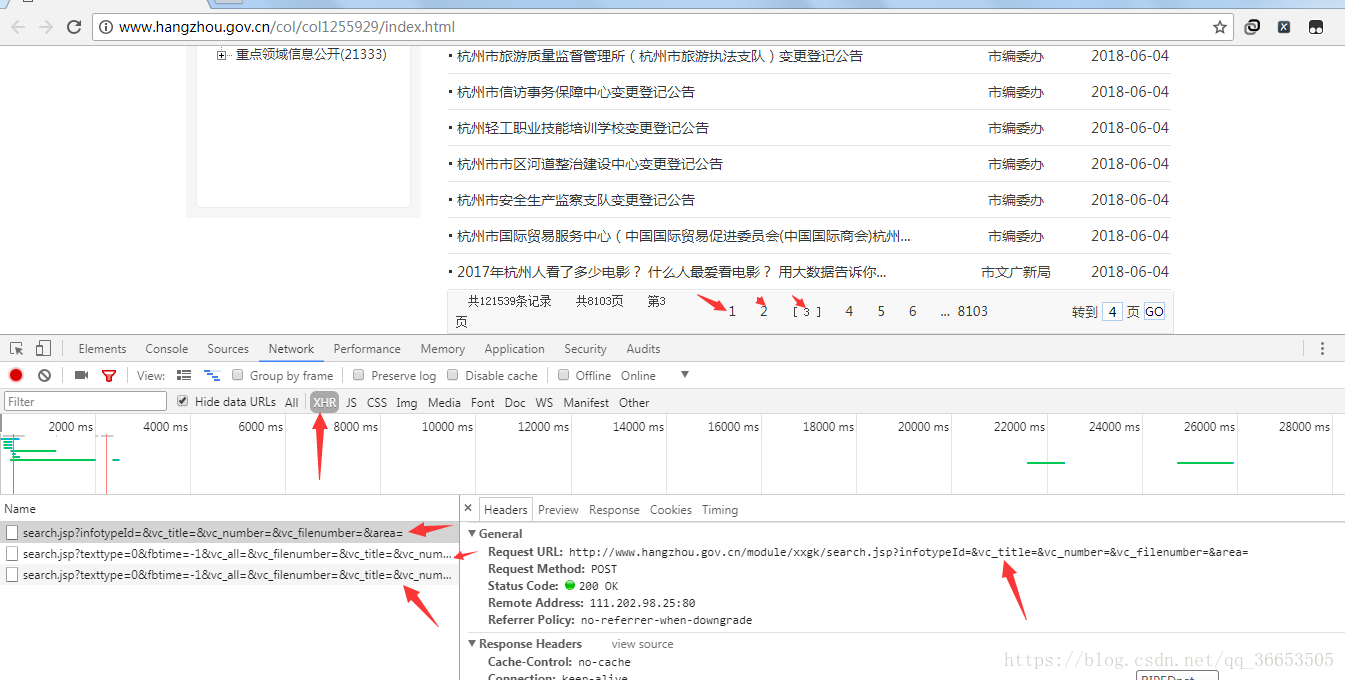
- 对于ajax异步请求的数据来说,首先考虑从右键->检查->network里抓包分析,如果不容易进行抓包分析,可以借助抓包工具fiddler等,还可以可以借助selenuim自动化网页测试等工具。本次爬虫比较简单,通过简单的抓包就可以获取到ajax异步请求的url地址。如下图
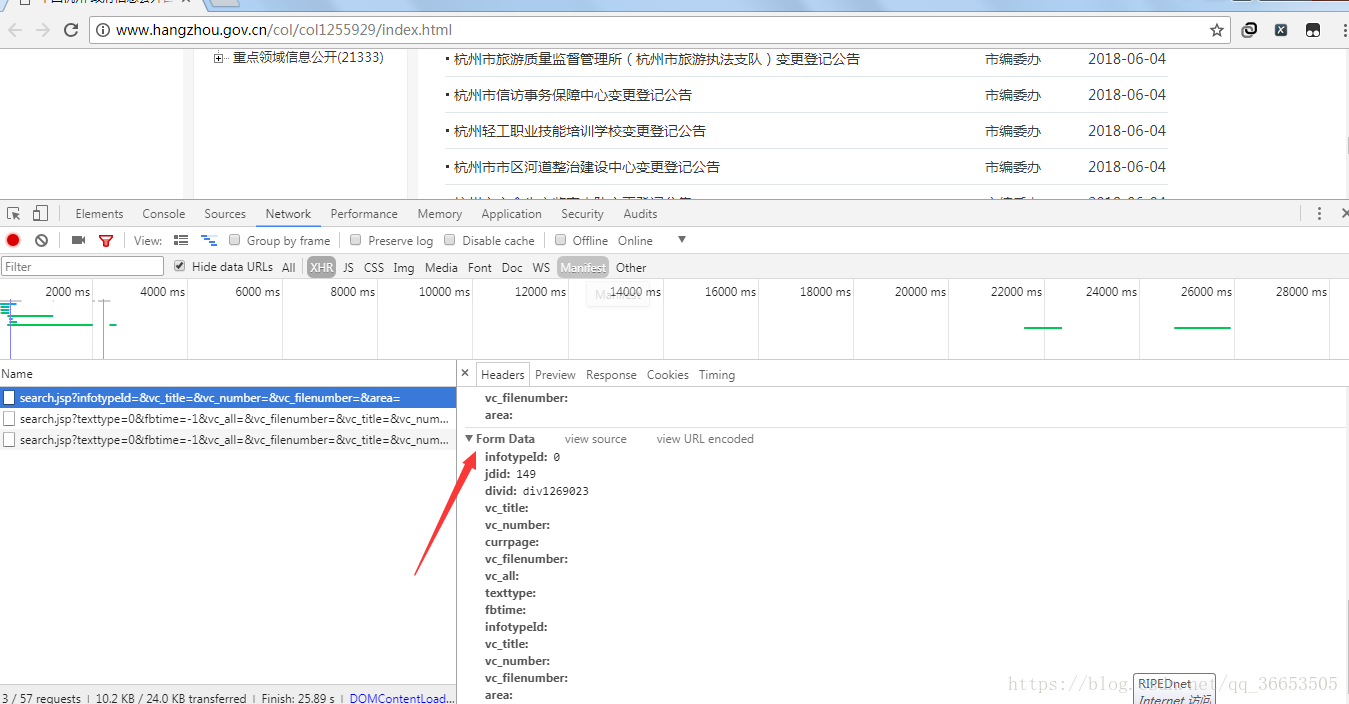
由上图可以,翻一次页,会多一个左下角的请求文件,从右下角即可看到发送请求的url地址,并且采用的是post请求方式,爬虫时需要有请求体data数据,data数据的内容如下图
- 接下来,就可以用pyspider框架进行爬取数据了,pyspider是一个相对Scrapy简单的框架,本文不对其使用进行详细描述,后续会单独写pyspider的相关教程。分析完毕,将爬取的数据保存至本地的mongodb数据库。现将完整代码附上
from pyspider.libs.base_handler import *
from pymongo import MongoClient
import datetime
import re
DB_IP = '127.0.0.1'
DB_PORT = 27017
DB_NAME = 'research'
DB_COL = 'hangzhou'
client = MongoClient(host=DB_IP, port=DB_PORT)
db = client[DB_NAME]
col = db[DB_COL]
class Handler(BaseHandler):
url = 'http://www.hangzhou.gov.cn/col/col1255929/index.html'
crawl_config = {
"headers": {
"User-Agent": "Mozilla/5.0 (X11;Linux x86_64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/66.0.3359.181 Safari/537.36"
}
}
def format_date(self, date):
return datetime.datetime.strptime(date, '%Y-%m-%d')
@every(minutes=24 * 60)
def on_start(self):
self.crawl(self.url, fetch_type='js', callback=self.index_page)
@config(age=60)
def index_page(self, response):
page = response.etree
total_page_str = page.xpath("//table[@class='tb_title']/tbody/tr/td/text()")[0].encode('utf-8')
print
total_page_str
total_page = int(re.findall('共(\d+)页', total_page_str)[0])
print
total_page
base_url = 'http://www.hangzhou.gov.cn/module/xxgk/search.jsp?'
data = {"infotypeId": "",
"jdid": 149,
"area": "",
"divid": "div1269023",
"vc_title": "",
"vc_number": "",
"vc_filenumber": "",
"vc_all": "",
"texttype": 0,
"fbtime": -1,
"texttype": 0,
"fbtime": -1,
"vc_all": "",
"vc_filenumber": "",
"vc_title": "",
"vc_number": "",
"sortfield": ""
}
for page_num in range(1, total_page + 1):
page_url = base_url + 'currpage={}&'.format(page_num)
print
page_url
self.crawl(page_url, callback=self.parse_page, method='POST', data=data)
def parse_page(self, response):
page = response.etree
categories = ["中国杭州"]
content_list = page.xpath("//div")[2].xpath(".//tr")
for each in content_list:
content_title = each.xpath("./td/a/@title")[0].encode('utf-8')
content_url = each.xpath("./td/a/@href")[0]
content_date = each.xpath("./td[3]/text()")[0]
save = {"title": content_title,
"url": content_url,
"date": content_date,
"categories": categories
}
self.crawl(content_url, callback=self.parse_body, save=save)
def parse_body(self, response):
page = response.etree
body_list = page.xpath("//td[@class='bt_content']//text()")
body = ''
for each in body_list:
body += each.strip().encode('utf-8')
result = {"title": response.save["title"],
"categories": response.save["categories"],
"date": self.format_date(response.save["date"]),
"url": response.save["url"],
"body": body,
"update_time": datetime.datetime.now(),
"source": "杭州市人民政府"
}
yield result
def on_result(self, result):
if result is None:
return
update_key = {
'date': result['date'],
'title': result['title']
}
col.update(update_key, {'$set': result}, upsert=True)