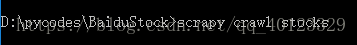一 Scrapy爬虫框架介绍
框架简介
是基于python实现爬虫的重要技术路线。scrapy不是一个函数功能库,而是一个爬虫框架。

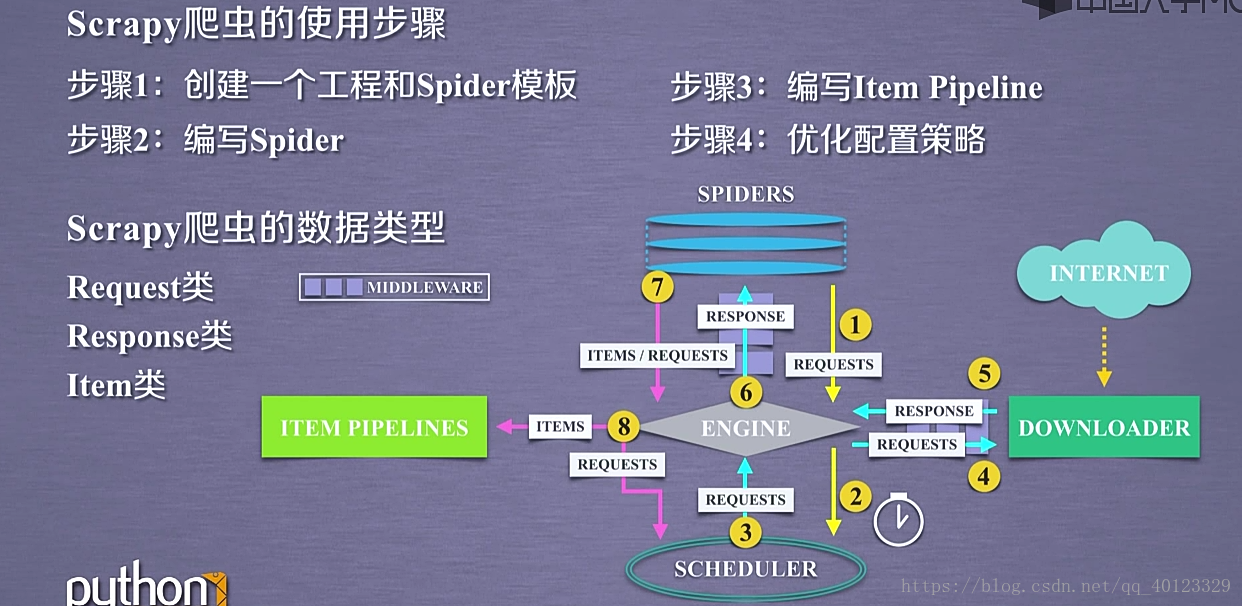
包括7个部分 :5+2结构 5个主题部分,2个中间键。
5个主模块:Spiders+ DOWNLOADER+ ENGINE+ SCHEDULER+ ITEM PIPELINES
Spider与 ENGINE ENGINE与DOWNLOADER有2个中间键模块(MIDDLEWARE)。

scrapy框架包含3条主要的数据流路线。
1 SPIDERS-------ENGINE------------SCHEDULER
SPIDERS通过MIDDLEWARE向ENGINE提出REQUESTS请求 (URL)再转发给SCHEDULER
2 SCHEDULER---------ENGINE-------DOWNLOADER------------ENGINE-------------SPIDERS
最终Spiders接受到 RESPONSE对象(响应)
3 SPIDERS--------ENGINE-------ITEM PIPELINES+SCHEDULER
SPIDER处理从Downloder获得的响应,处理后产生2个数据类型 一个是爬取项SCRAPYITEMS/items 另外一个是新的爬取请求(网页中存在新的我们也需要爬取信息的链接)。发送给ENGINE模块。ENGINE将ITEMS发送给ITEM PIPELINES,将REQUESTS发送给SCHEDULER进行调度。
因此框架的入口是SPiders 出口是ITEM PIPELINES 剩下的3个模块是已有的功能模块,用户不需要编写。需要编写(配置)的是2个入口模块。(这两个模块已有相关模板代码,需要根据需要进行修改)
SPIDERS用于向整个框架提供URL链接,同时解析从网络上获取的页面的内容。
ITEM PIPELINES负责对提取的信息进行后处理。
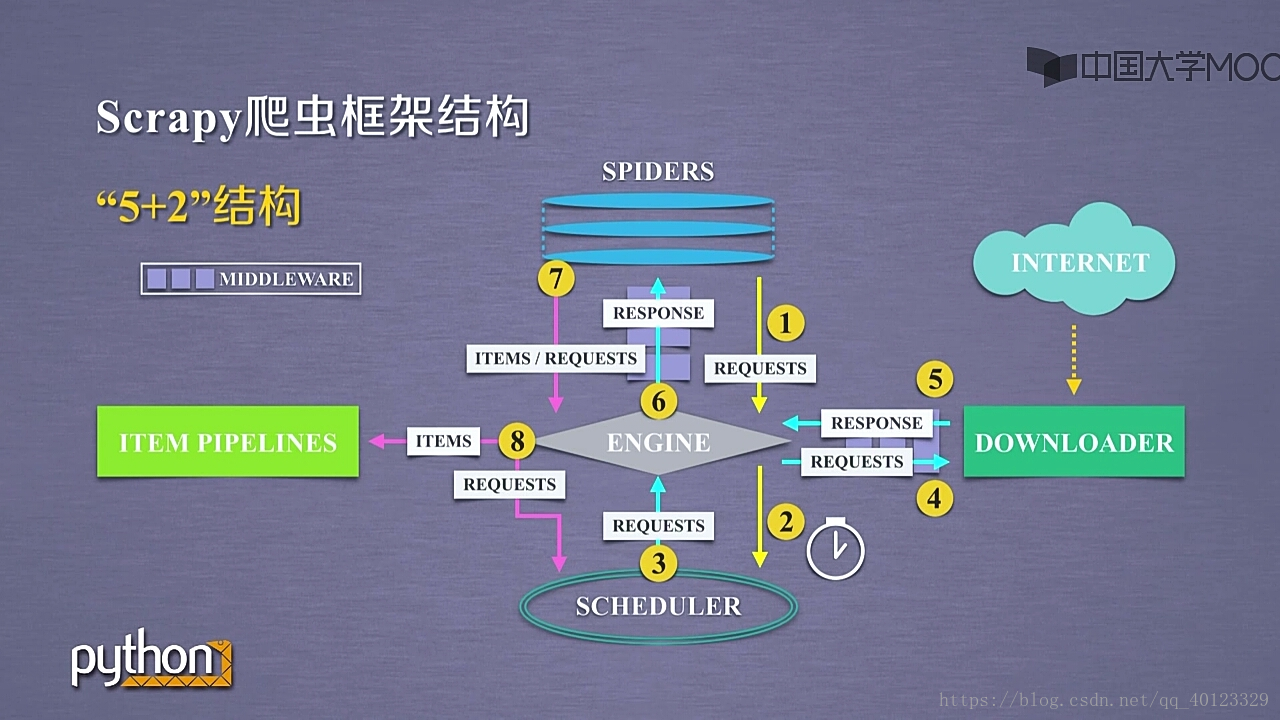
Engine模块:控制模块之间的数据流。根据条件触发事件。不需要用户修改。
Downloder: 根据请求下载网页。不需要用户修改。
Scheduler模块:对所有爬取请求进行调度管理。不需要用户修改。

Spider模块:
解析Downloder返回的响应(Response),产生爬取项(scraped item),产生额外的爬取请求(Request)
Item Pipelines :
以流水线方式处理Spider产生的爬取项。
由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型。
可能的操作包括:清理,检验,和查重爬取项中的HTML数据,将数据存储到数据库。
Scrapy爬虫常用命令
scrapy是为持续运行设计的专业爬虫框架。scrapy命令行格式为:>scrapy<command>[options][args]
在终端输入 scrapy -h可以看到常用命令
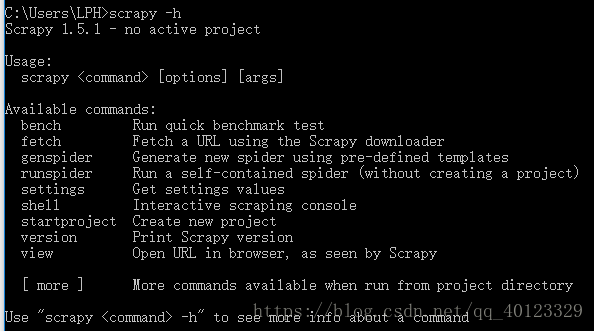

一个工程相当于一个大的Scrapy框架,一个Scrapy框架可以有多个爬虫,每一个爬虫相当于框架中的一个Spider。
最常用的scrapy命令为1 2 4

二:Scrapy爬虫的步骤实例
步骤一:建立Scrapy爬虫工程
演示HTML的地址是:http://python123.io/ws/demo.html
选取一个目录建立工程:scrapy startproject python123demo

用pip命令安装,结果出现


安装:
接着安装scrapy:pip install scrapy
成功后,重新创建工程。



settings.py用于优化爬虫功能。
spiders/存储python123demo中建立的爬虫。当前文件相当于一个空文件。

步骤二:在工程中产生一个Scrapy爬虫
执行一条命令即可,要求给出爬虫的名称以及所要爬取的网站。用genspider命令即可。

即生成一个名为demo的爬虫

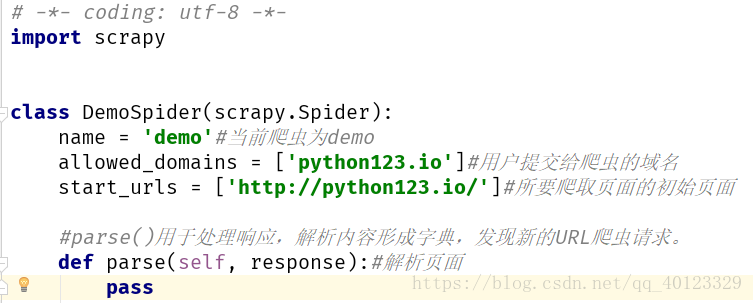
步骤三:配置产生的spider爬虫(修改demo.py)
修改具体链接
start_urls = ['http://python123.io/ws/demo.html']#所要爬取页面的初始页面最终代码为
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'#当前爬虫为demo
#allowed_domains = ['python123.io']#用户提交给爬虫的域名
start_urls = ['http://python123.io/ws/demo.html']#所要爬取页面的初始页面
#parse()用于处理响应,解析内容形成字典,发现新的URL爬虫请求。
def parse(self, response):#解析页面
#response 存储请求网页返回的内容。我们要把爬取的结果存储到HTML文件中
#定义HTML文件名字fname,从响应的url中提取名字作为本地名字
fname=response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s. '%name)
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'#当前爬虫为demo
#allowed_domains = ['python123.io']#用户提交给爬虫的域名
def start_requests(self):
urls=['http://python123.io/ws/demo.html']#所要爬取页面的初始页面
#适宜于爬取成千上万个网页。
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
#parse()用于处理响应,解析内容形成字典,发现新的URL爬虫请求。
def parse(self, response):#解析页面
#response 存储请求网页返回的内容。我们要把爬取的结果存储到HTML文件中
#定义HTML文件名字fname,从响应的url中提取名字作为本地名字
fname=response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s. '%name)步骤四:运行爬虫,获取网页

捕获的页面存储在demo.html文件中

三 yield关键字
生成器被唤醒后,函数的值和上一次的被冻结时的值相同。

生成器的使用一般与循环搭配在一起。
生成器写法: 普通写法:

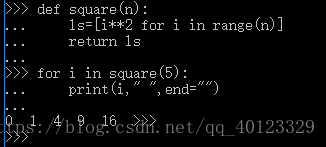
生成器更节省存储空间,相应更迅速,使用灵活。
想象以下,上述数字不是5,而是1000000000000000000......那么普通写法就要占用很大空间,但是用生成器就只占用一个元素的空间。
四 Scrapy爬虫的基本使用






上述都是Spider里的方法
CSS Selector

五 股票数据Scrapy爬虫实例介绍


1 编写爬虫程序 编写Spider 处理链接爬取和网页解析。
2 编写pipelines处理解析后的股票数据,并输入到文件。
步骤 :
1 建立工程和Spider模板

2 编写(配置)Spider

pycharm中安装scrapy时也出现错误,解决方案与上述步骤相同。在Scripts下安装Twisted,然后再安装scrapy。
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
#从东方财富网获得股票列表
start_urls = ['http://quote.eastmoney.com/stocklist.html']
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock=re.findall(r'[s][hz]\d{6}',href)[0]
url='https://gupiao.baidu.com/stock/'+stock+'.html'
yield scrapy.Request(url,callback=self.parse_stock)
except:
continue
def parse_stock(self,response):
infoDict={}
stockInfo=response.css('.stock-bets')
name=stockInfo.css('.bets-name').extract()[0]
keyList=stockInfo.css('dt').extract()
valueList=stockInfo.css('dd').extract()
for i in range(len(keyList)):
#[1:-5]#注意观察响应网页的股票信息
key=re.findall(r'>.*</d>',keyList[i])[0][1:-5]
try:
val=re.findall(r'\d+\.?.*</dd>',valueList[i])[0][1:-5]
except:
val='--'
infoDict[key]=val
infoDict.update(
{'股票名称':re.findall('\s.*\(',name)[0].split()[0]+\
re.findall('\>.*\<',name)[0][1:-1]}
)
yield infoDict
3 编写ITEM Pipelines

# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class BaidustockPipeline(object):
def process_item(self, item, spider):
return item
class BaidustockInfoPipeline(object):
def open_spider(self,spider):
self.f=open('BaiduStockInfo.txt','w')
def close_spider(self,spider):
self.f.close()
def process_item(self,item,spider):
#对每个item项进行处时对应的方法
try:
line=str(dict(item))+'\n'
self.f.write(line)
except:
pass
return item
执行爬虫: