官网学习链接:https://www.crummy.com/software/BeautifulSoup/
Beautiful Soup库的安装小测
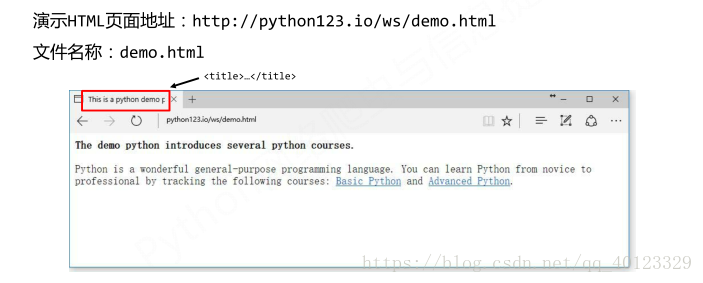
页面源代码:HTML5.0格式。获取源代码的方式:在页面右击选择源代码或用Requests库获取demo.html源代码。

from bs4 import BeautifulSoup
soup=BeautifulSoup('<p>data</p>','html.parser')
Beautiful Soup库的基本元素




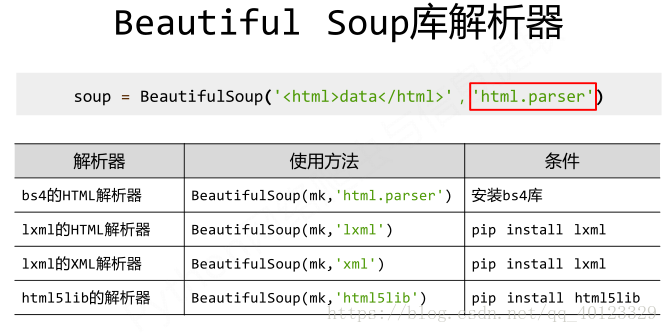
BeautifulSoup类的基本元素





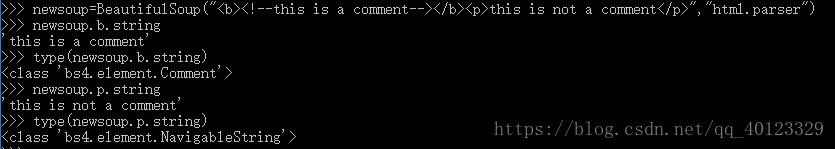

基于bs4库的HTML内容遍历方法
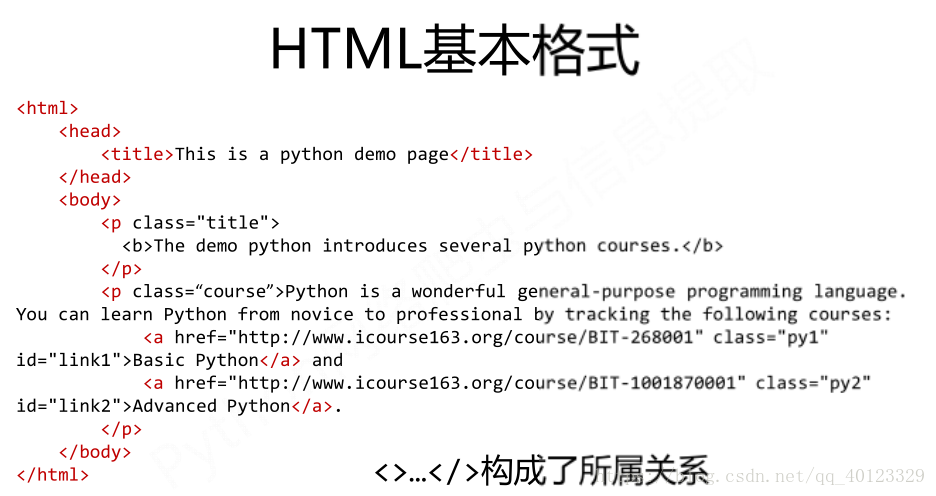

标签树的下行遍历

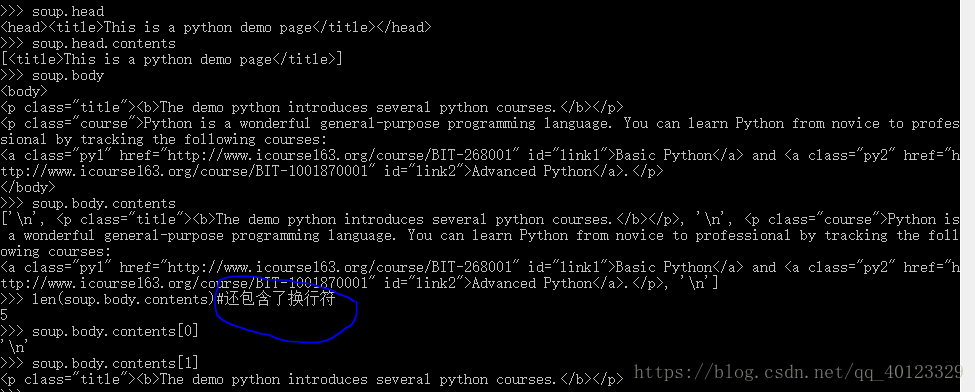

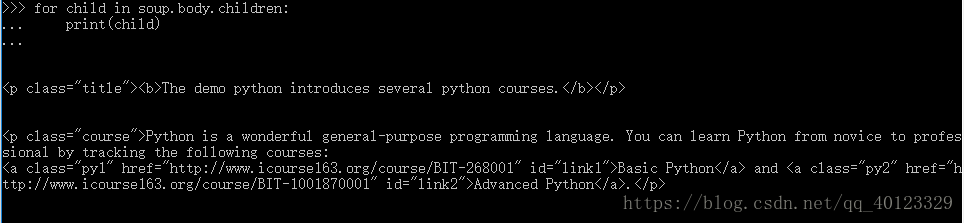

标签树的上行遍历
| 属性 | 说明 |
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
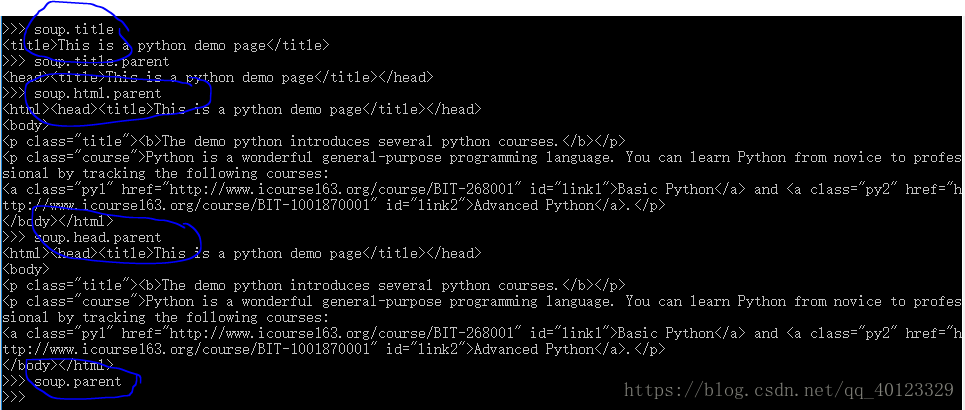

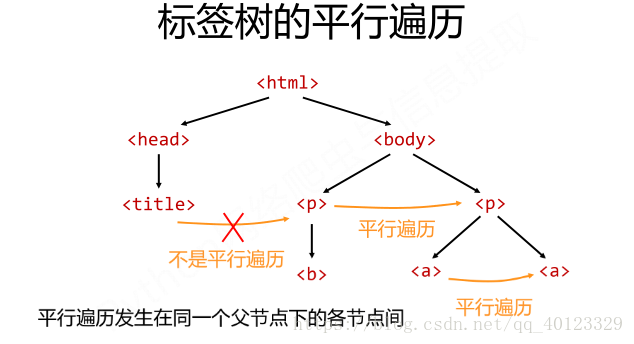
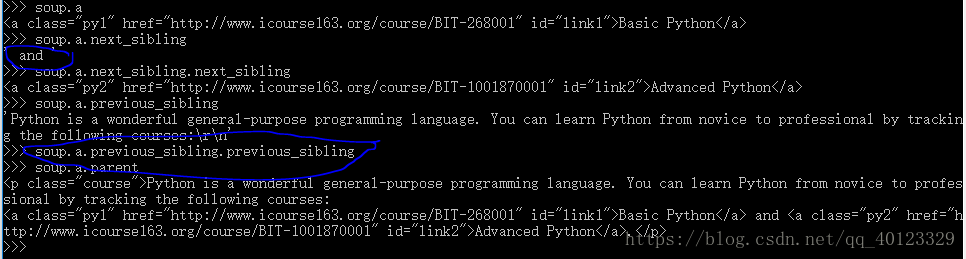
标签树的平行遍历
| 属性 | 说明 |
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
for sibling in soup.a.next_siblings:
print(sibling) #遍历后续节点
for sibling in soup.a.previous_siblings:
print(sibling) #遍历前续节点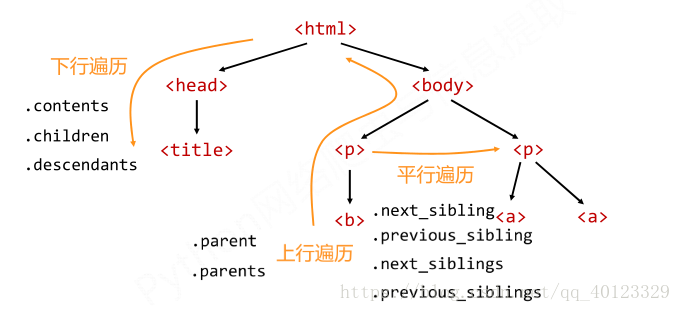
基于bs4库的HTML格式输出
bs4库的prettify()方法
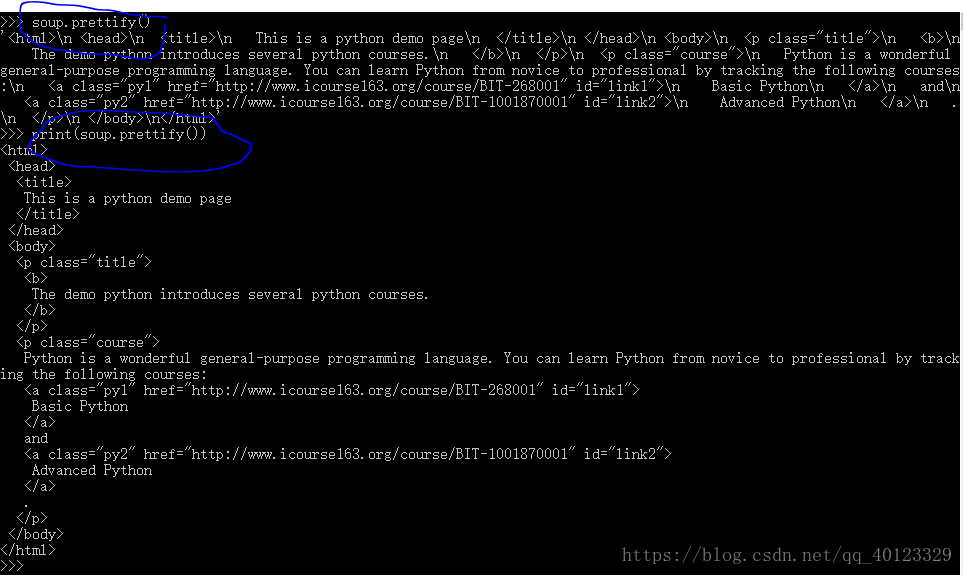
.prettify()为HTML文本<>及其内容增加‘\n’
.prettify()可以用于标签,方法为<tag>.prettify()

bs4库的编码

信息标记的三种方式


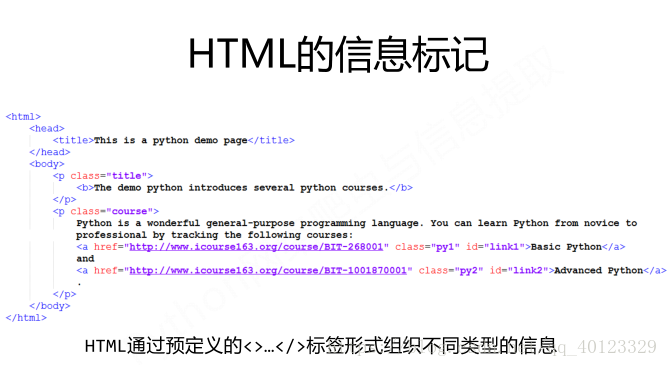
信息标记的三种形式:XML JSON YAML
- XML:与HTML很想,也可以说是HTML的一种特殊形式。



- JSON
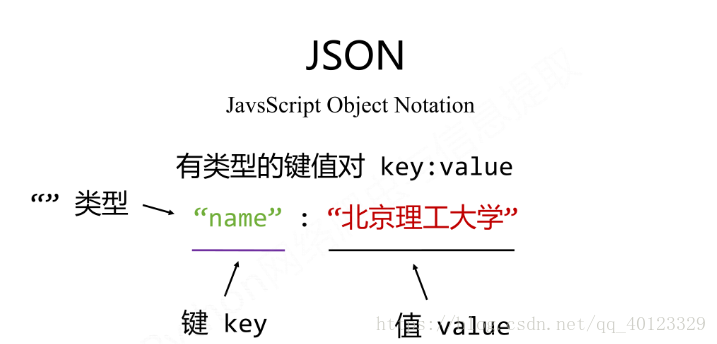


- YAML




三种信息标记形式的比较





信息提取的一般方法





基于bs4库的HTML内容查找方法
方法<>.find_all(name,attrs,recursive,string,**kwargs) 返回一个列表类型,存储查找的结果。
- name:对标签名称的检索字符串。

检索所有的标签名,传入参数True 检索以‘b’开头的所有信息,导入re模块,用正则表达式。


- attrs:对标签属性值的检索字符串,可标注属性检索。


- recursive:是否对子孙全部检索,默认为True

- string:<>...</>中字符串区域的检索字符串



按照检索区域和返回个数的不同,又可以由另外几种方法
