官方文档:点击这里
一:Requests库
Requests库小试
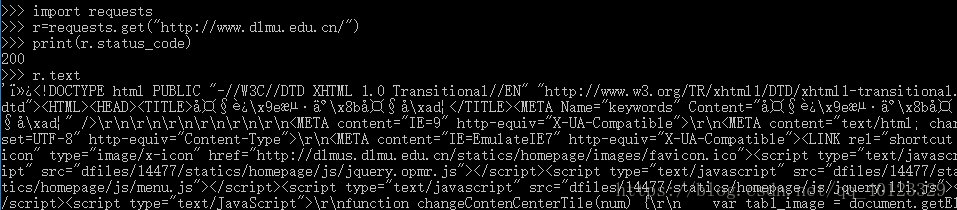
Requests库的7个主要方法
| 方法 | 说明 |
| requests.request() | 构造一个请求,支持以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTML的GET |
| requests.head() | 获取HTML网页头信息的方法。对应HTML的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTML的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTML的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTML的PATCH |
| requests.delete() | 向HTML网页提交删除请求,对应于DELETE |
Requests库的get()方法
r=requests.get(url) 等号右侧构造一个向服务请求资源的Request对象。
整体返回一个包含服务器资源的Response对象
Requests库的两个重要对象Response(包含爬虫返回的内容)和Request
requests.get(url, params=None, **kwargs)
| 参数 | 说明 |
| url | 拟获取页面的url链接 |
| params | url中的额外参数,字典或字节流格式。可选 |
| **kwargs | 12个控制访问的参数 |
Response对象
Response对象也有request

Response对象的属性
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表示连接成功,404或其他表示失败 |
| r.text | HTTP相应内容的字符串形式,即Url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
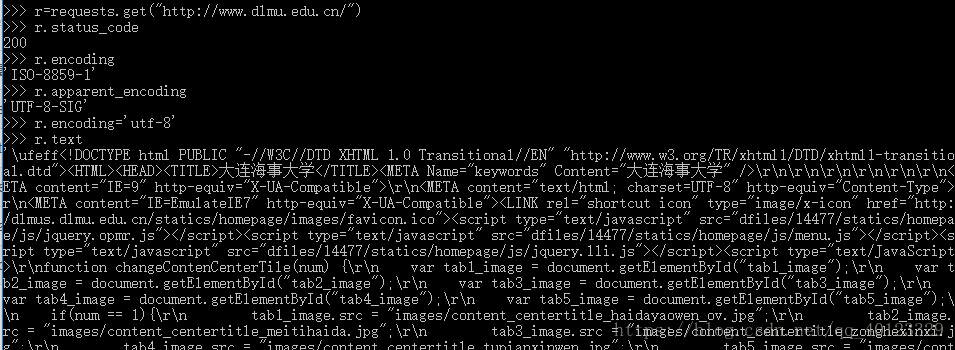
Response的编码
r.encoding:如果header中不存在charset,则认为编码为ISO-8859-1
r.text根据r.encoding显示网页内容
r.apparent_encoding:根据网页内容分析出来的编码方式
可以看做是r.encoding的备选
爬取网页的通用代码框架
r=requests.get() 网络连接有风险,要进行异常处理。
Requests库的异常
| 异常 | 说明 |
| requests.ConnectionError | 网络连接错误异常,比如DNS查询失败,拒绝连接 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,超时异常 |
r.raise_for_status() 如果不是200,产生异常requests.HTTPError
r.raise_for_status() 在方法内部判断r.status_code是否等于200,不需要增加额外的if语句,便于进行try-except异常处理
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态码不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))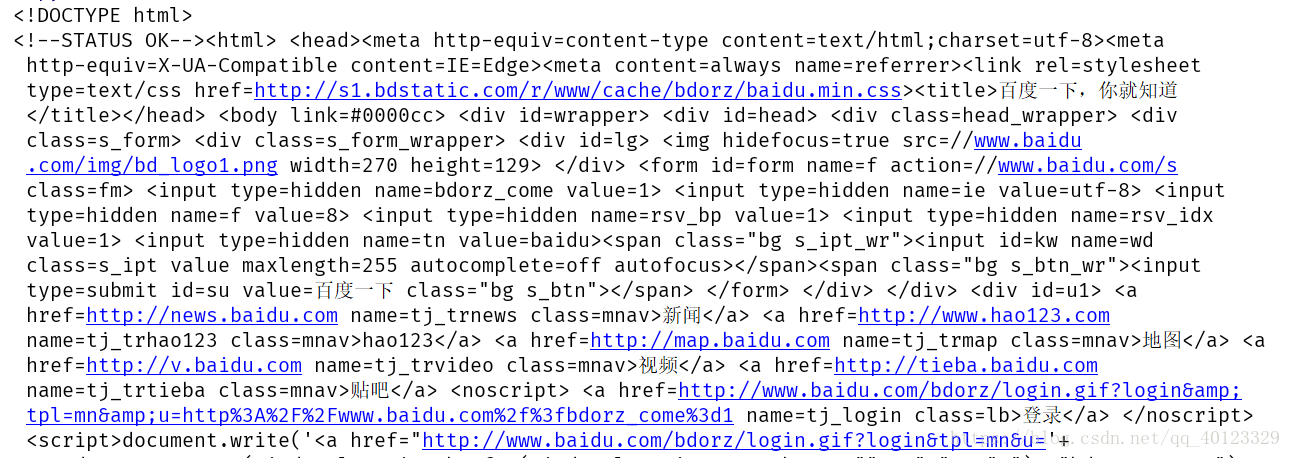
HTTP协议及Requests库的方法
HTTP是一个基于“”请求与相应“”模式的,无状态(上一次响应与这一次没有关系)的应用层协议。采用URL作为网络资源的标识,格式如下:
http://host[:port][path]
host:合法的internet主机域名或ip地址
port:端口号,缺省为88
path:请求资源的路径
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应于一个数据资源。
HTTP协议对资源的操作
| 方法 | 说明 |
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应信息报告,即获取该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原链接位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容。 |
| DELETE | 请求删除URL位置存储的资源 |
HTTP协议通过URL对资源进行定位,通过6个函数对资源进行管理

理解PATCH与PUT区别

Requests库的head()方法

Requests库的post()方法
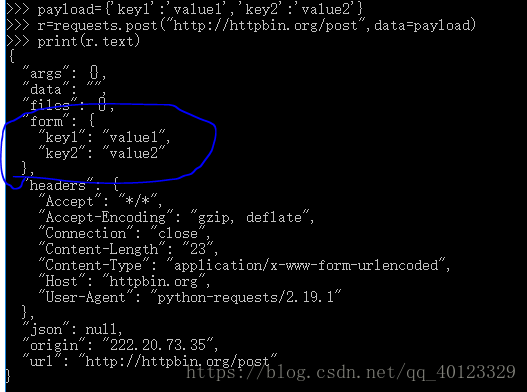
向URL POST一个字典,自动编码为form(表单)。

POST一个字符串,自动编码为data.
Requests库的put()方法
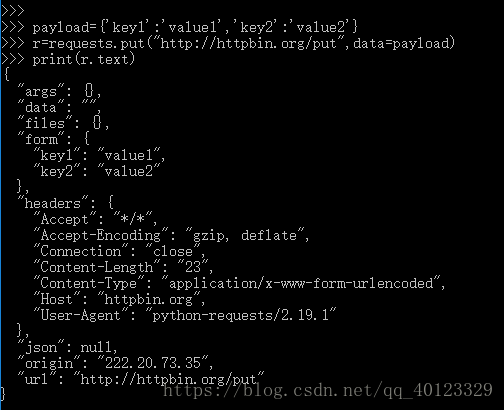
Requests库主要方法解析
requests.request(method,url,**kwargs)
method对应7种请求方式。url拟获取页面链接。**kwargs13个访问控制参数。



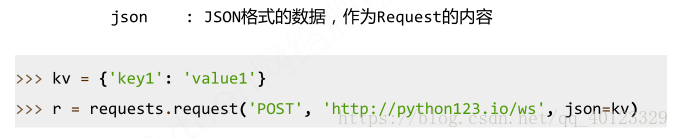




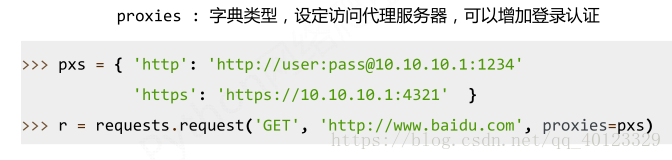


Requests.get(url,params=None,**kwargs)

Requests.head(url,**kwargs)

Requests.post(url,data=None,json=None,**kwargs)

Requests.put(url,data=None,**kwargs)

Requests.patch(url,data=None,**kwargs)

Requests.delete(url,**kwargs)

二:爬虫引发的问题
网络爬虫的尺寸

网络爬虫引发的问题:性能骚扰,法律风险,隐私泄露
网络爬虫的限制

Robots协议
作用:网站告知网络爬虫哪些页面可以爬取,哪些不行。
形式:在网站根目录下robots.txt文件。

百度的爬虫限制:https://www.baidu.com/robots.txt
新浪新闻的爬虫限制:https://news.sina.com.cn/robots.txt
淘宝网的爬虫限制:https://www.taobao.com/robots.txt
Robots协议的遵守方式


三 Requests库网络爬虫实战
1 京东商品页面的爬取
链接:https://item.jd.com/8457421.html
代码框架为:
import requests
url="https://item.jd.com/8457421.html"
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
2亚马逊商品页面爬取
商品链接为:商品链接
很遗憾,我没有遇到教程里的错误,但是还是把解决方案copy一下。

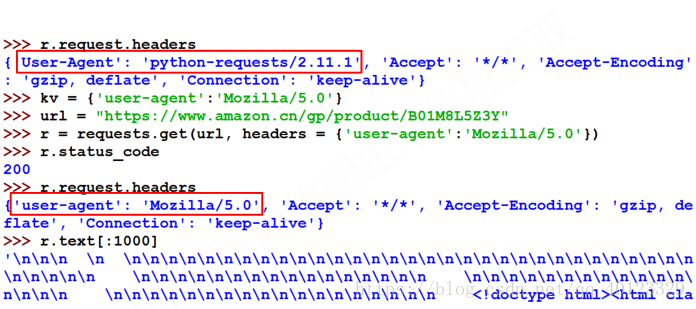
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Chrome/10.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[:5000])
print(r.request.headers)
except:
print("爬取失败")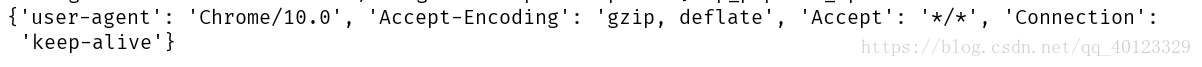
3百度/360搜索关键字提交
百度的关键词接口:
http://www.baidu.com/s?wd=keyword
360的关键词接口:
http://www.so.com/s?q=keyword
百度搜索全代码
import requests
url="http://www.baidu.com/s"
try:
kv={'wd':'python'}
r=requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
#print(r.text)
except:
print("爬取失败")
360搜索代码
import requests
url="http://www.so.com/s"
try:
kv={'q':'python'}
r=requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(len(r.text))
#print(r.text)
except:
print("爬取失败")
4网络图片的爬取和存储
网络图片的链接格式:http://www.example.com/picture.jpg
图片地址:
import requests
import os
url="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1533896076105&di=a47c8f20542f299c5e20cca04f4f3143&imgtype=0&src=http%3A%2F%2Fi1.hdslb.com%2Fbfs%2Farchive%2F0ad2733a3fc734d598320de2c931033e77132802.jpg"
root=r"D:\pics"
path=r"D:\pics\1.jpg"
kw={'user-agent':'Chrome/10.0'}
try:
if not os.path.exists(root):#判断该目录是否存在,若不存在,就创建该路径。
os.mkdir(root)
if not os.path.exists(path):#判断该文件是否存在
r=requests.get(url,headers=kw)
print(r.status_code)
r.raise_for_status()
with open(path,'wb') as f:
f.write(r.content)#r.content返回内容的二进制形式。
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")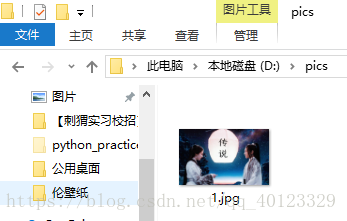
5 IP地址归属地的自动查询(手机地址所在地的自动查询)
手机地址所在地的自动查询网站为:http://www.ip138.com/sj/
可以发现输入电话号码之后网站网址信息变为http://www.ip138.com:8080/search.asp?action=mobile&mobile=18340819482
因此可以模拟第二个网站链接:对查到的信息进行爬取。
import requests
url="http://www.ip138.com:8080/search.asp?action=mobile&mobile="
try:
r=requests.get(url+'18340819482')
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[-2000:-1000])
except:
print("爬取失败")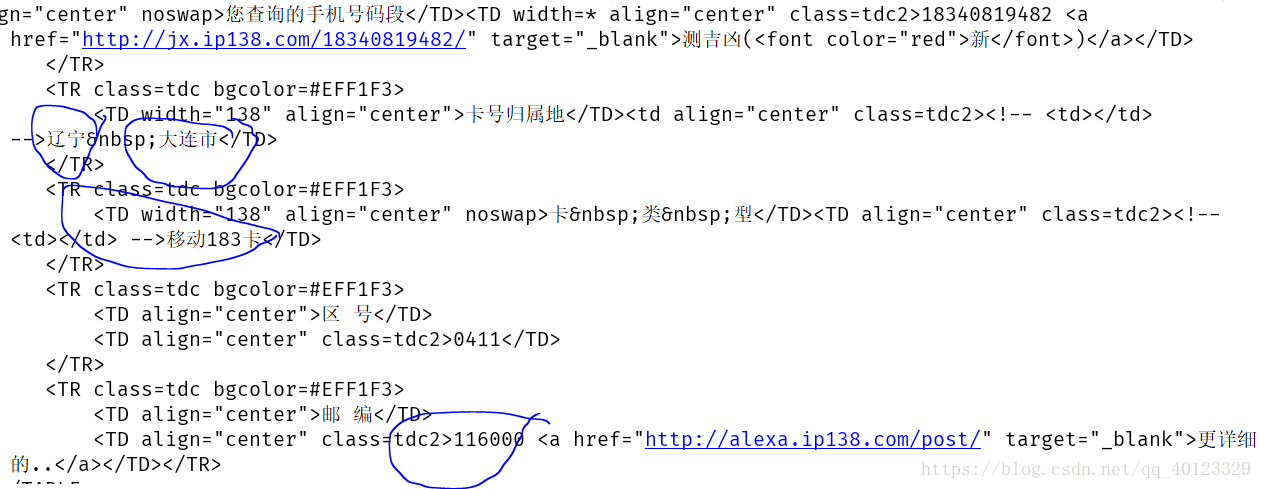
{kind=link}