课程介绍
本课程以一个小项目带你快速上手 Python 爬虫和数据分析,主要分 3 部分:
- 第 1 部分是 Python 爬虫,主要使用 Urllib 3 和 BeautifulSoup 抓取天猫商城和京东商城胸罩销售数据,并保存到 SQLite 数据库中;
- 第 2 部分是对抓取的胸罩销售数据进行数据清洗,主要是去除空数据,让数据格式更规范;
- 第 3 半部分利用 Pandas 对数据进行分析,以及使用 Matplotlib 对分析后的数据进行可视化。
通过一系列分析,可以得到中国女性胸部尺寸(胸围)的标准大小,想知道中国女性最标准的胸围是多少吗?想知道什么颜色的胸罩最畅销吗?想知道 C 罩杯以上的女性喜欢到天猫还是京东购买胸罩吗?答案尽在本课程中。
作者介绍
李宁,欧瑞科技创始人 & CEO,技术狂热分子,IT 畅销书作者,CSDN 特约讲师、CSDN 博客专家,拥有近 20 年软件开发和培训经验。主要研究领域包括 Python、深度学习、数据分析、区块链、Android、Java 等。曾出版超过 30 本 IT 图书,主要包括《Python 从菜鸟到高手》《Swift 权威指南》《Android 开发指南》等。
课程内容
第01课:分析天猫商城胸罩销售数据
本系列文章会带领大家使用多种技术实现一个非常有趣的项目,该项目是关于胸罩销售数据分析的,是网络爬虫和数据分析的综合应用项目。本项目会从天猫和京东抓取胸罩销售数据(利用 Chrome 工具跟踪 Web 数据),并将这些数据保存到 SQLite 数据库中,然后对数据进行清洗,最后通过 SQL 语句、Pandas 和 Matplotlib 对数据进行数据可视化分析。我们从分析结果中可以得出很多有的结果,例如,中国女性胸部标准尺寸是多少、胸罩上胸围的销售比例、哪个颜色的胸罩最受女性欢迎。
其实关于女性胸部的数据分析已经有很多人做了,例如,Google 曾给出一个全球女性胸部尺寸地图,如图1所示。
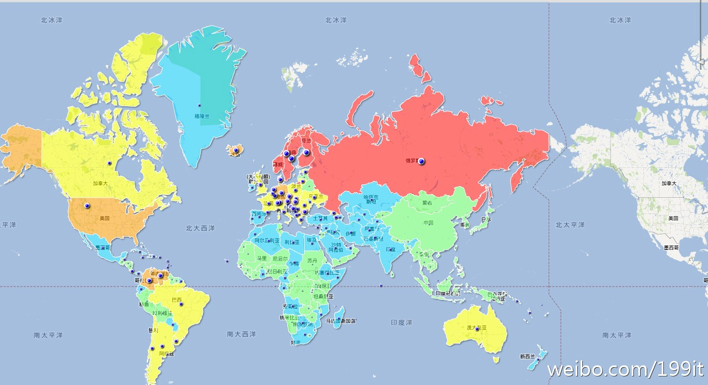
图1 Google 的全球女性胸部尺寸分布地图
地图中,红色代表大于 D 罩杯,橙色是 D,黄色 C,蓝色 B,绿色则为 A。从地图上看,中国地区主要集中在蓝色和绿色,也就是主要中国女性胸部罩杯主要以 A 和 B 为主;而全面飘红的俄罗斯女性胸部尺寸全面大于 D 罩杯,不愧是战斗的民族。
再看一下图2所示的淘宝胸罩(按罩杯和上胸围统计)销售比例柱状图。
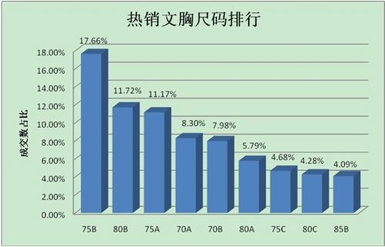
图2 淘宝胸罩销售比例柱状图(按罩杯和上胸围统计)
根据淘宝数据平台提供的数据显示,在中国,B 罩杯的胸罩销售量最多。在2012年6月14日至7月13日期间,购买最多的胸罩尺寸为 B 罩杯,前9位中,B 罩杯占比达41.45%,说明中国平均胸部大小都在 B 罩杯。其中,又以 75 B 的销量最好,85 B 则在 B 罩杯中相对落后,仅4.09%,C 罩杯则只有8.96%。
其实无论 Google 还是淘宝,给出的数据尽管可能在具体的比例上有差异,但总体的趋势是一样的,也就是说,中国女性胸部尺寸以 B 罩杯为主。销售最好的是 75 B(中国女性的标准胸围),其次是 80 B,85 B 的销售比较不好,因为这个身材对于女性来说,确实有点魁梧了。
前面给出的这些数据都是别人统计的,现在就让我们自己来验证一下,这些数据到底准不准。在本系列文章中,我们选择了天猫和京东两家大电商,多个胸罩品牌,20000条销售记录,利用了数据库和 Pandas 进行统计分析,看看能不能得出与 Google 和淘宝类似的结论。
说干就干,首先需要从马云同学的天猫商城取点数据,取数据的第一步即使要分析一下 Web 页面中数据是如何来的。也就是说数据,数据是通过何种方式发送到客户端浏览器的。通常来讲,服务端的数据会用同步和异步的方式发送。但同步的方式目前大的网站基本上不用了,主要都是异步的方式。也就是说,静态页面先装载完,然后通过 AJAX 技术从服务端获取 JSON 格式的数据(一般都是 JSON 格式的),再利用 JavaScript 将数据显示中相应的 Web 组件上,基本都是思路,区别就是具体如何实现了。天猫和京东的数据基本上没采用什么有意义的反爬技术,所以抓取数据相对比较容易。
进到天猫商城(要求使用 Chrome 浏览器,有很方便的调试工具),搜索出“胸罩”商品,然后进入某个胸罩商品页面。浏览商品页面,在页面的右键菜单中点击“检查”菜单项,打开调试窗口,切换到“Network”选项卡,这个选项卡可以实时显示出当前页面向服务端发送的所有请求,以及这些请求的请求头、响应头、响应内容以及其他与调试有关的信息。对于调试和跟踪 Web 应用相当方便。
打开“Network”选项卡后,进到商品评论处,切换到下一页,会看到“Network”选项卡下方出现很多 URL,这就是切换评论页时向服务端新发出的请求。我们要找的东西就在这些 URL 中。至于如何找到具体的 URL,那就要依靠经验了。可以一个一个点击寻找(在右侧的“Preview”选项卡中显示 URL 的响应内容),也可以根据 URL 名判断,一般程序员不会起无意义的名字,这样很不好维护。根据经验,会找到至少一个名为list_detail_rate.htm的 URL,从表面上看,这是一个静态的页面,其实这个 URL 后面跟着一大堆参数,不可能是静态的,从调试窗后上方的文本框搜索list_detail,也会定位到这个 URL,如图3所示。
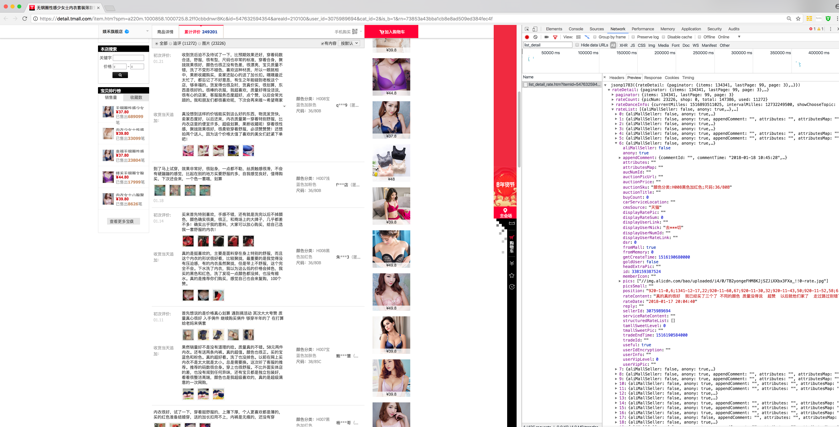
图3 获取销售数据的 URL
从该 URL 的响应内容可以明显看到,这是类似于 JSON 格式的数据,而且可以看到评论数据,因此可以断定,这就是我们要找的东西。
可以直接单击这里,在浏览器地址栏中查看。
查看后,会得到如图4所示的 JSON 格式的页面。
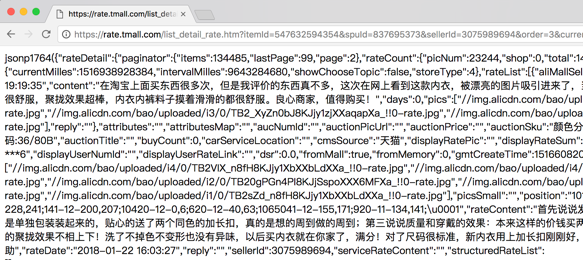
图4 JSON 格式销售数据
其实这个 URL 是查看某个商品某一页的评论(销售)数据的,如果要查询所有也的评论数据,就需要动态改变 URL 的参数。下面看一下“Headers”选项卡下面的“Query String Parameters”部分,如图5所示,会清楚地了解该 URL 的具体参数值。
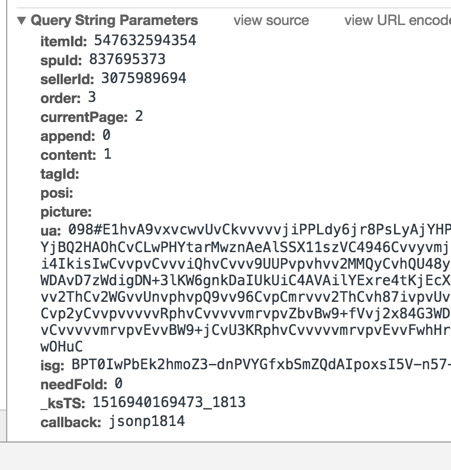
图5 HTTP GET 请求参数
在这些参数中有一部分对我们有用,例如,itemId 表示商品 ID,currentPage 表示当前获取的评论页数,在通过爬虫获取这些评论数据时,需要不断改变这些参数值以获取不同的评论数据。
尽管根据评论数计算(每页20条评论),某些商品的评论页数可能多达数百页,甚至上千页。不过实际上,这个 URL 最多可以返回99页评论数据,也就是最新的近2000条评论数据。我们可以看到“Preview”选项卡中显示的 JSON 数据中有一个 paginator 项,该项目有一个 lastPage 属性,该属性值是99,如图6所示,这个属性值就是最多返回的评论页数。

图6 最大评论页数
现在分析数据的第一步已经搞定了,我们已经知道天猫商城的评论数据是如何从服务的获取的,那么下一步就是抓取这些数据,并保存到本地的 SQLite 数据库中。
京东商城的胸罩销售数据的分析方法与京东商城类似。首先进到京东商城(要求使用 Chrome 浏览器,有很方便的调试工具),搜索出“胸罩”商品,然后进入某个胸罩商品页面。浏览商品页面,在页面的右键菜单中点击“检查”菜单项,打开调试窗口,切换到“Network”选项卡,如图7所示,这个选项卡可以实时显示出当前页面向服务端发送的所有请求,以及这些请求的请求头、响应头、响应内容以及其他与调试有关的信息,对于调试和跟踪 Web 应用相当方便。
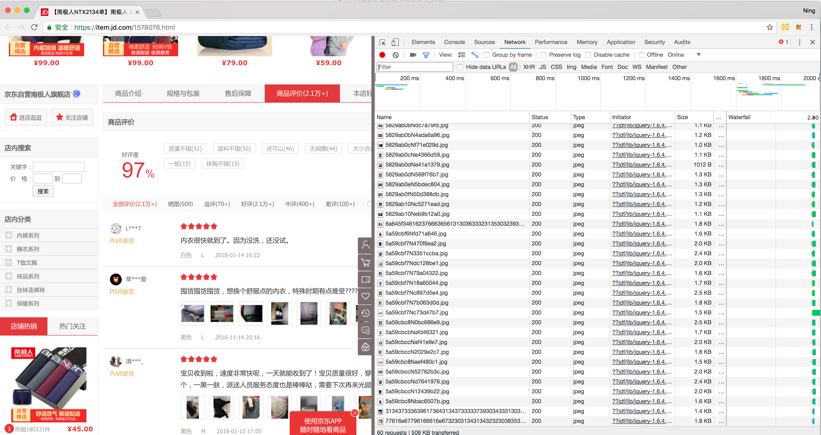
图7 切换到“Network”选项卡
打开“Network”选项卡后,进到商品评论处,切换到下一页,会看到“Network”选项卡下方出现很多URL,这就是切换评论页时向服务端新发出的请求,我们要找的东西就在这些 URL 中,至于如何找到具体的 URL,那就要依靠经验了,可以一个一个单击寻找(在右侧的“Preview”选项卡中显示 URL 的响应内容),也可以根据 URL 名判断,一般程序员不会起无意义的名字,这样很不好维护。根据经验,会找到至少一个名为 productPageComments.action 的 URL,单击这个 URL,会在右侧的“Preview”页面显示返回的数据,数据结构与天猫商城返回的商品评论数据类似,如图8所示。
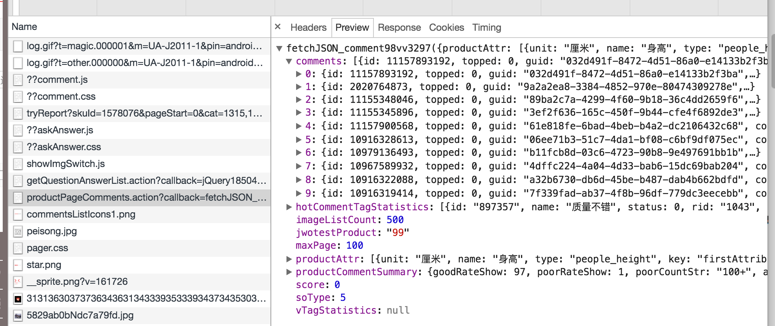
图8 数据结构与天猫商城返回的商品评论数据类似
从该 URL 的响应内容可以明显看到,这是类似于 JSON 格式的数据,而且可以看到评论数据,因此可以断定,这就是我们要找的东西。
可以将这个 URL 复制下来,详见这里,在浏览器地址栏中查看。
查看后,会得到如图9所示的 JSON 格式的页面。
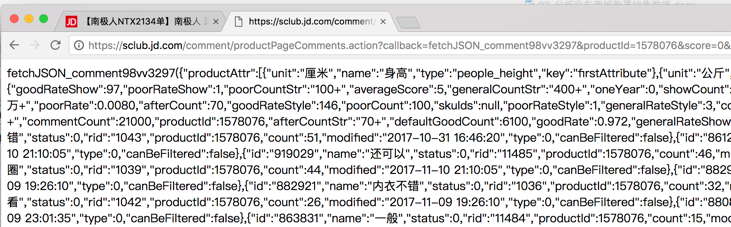
图9 JSON 格式的页面
其实这个 URL 是查看某个商品某一页的评论(销售)数据的,如果要查询所有也的评论数据,就需要动态改变 URL 的参数。下面看一下“Headers”选项卡下面的“Query String Parameters”部分,如图10所示,会清楚地了解该 URL 的具体参数值。
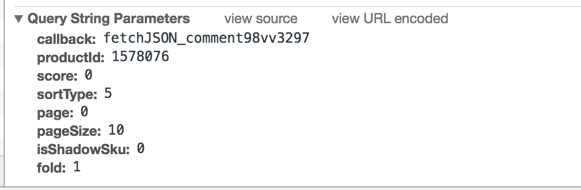
图10 URL 具体参数值
很明显,京东商城返回商品评论数据的 URL 的参数的个数要比天猫商城的少。在这些参数中有一部分对我们有用,例如,productId 表示商品 ID,page 表示当前获取的评论页数,在通过爬虫获取这些评论数据时,需要不断改变这些参数值以获取不同的评论数据。
尽管根据评论数计算(每页10条评论),某些商品的评论页数可能多达数百页,甚至上千页。不过实际上,这个 URL 最多可以返回100页评论数据,也就是最新的1000条评论数据。我们可以看到“Preview”页面中显示的 JSON 数据中有一个 maxPage 属性,该属性值是100,如图11所示,这个属性值就是最多返回的评论页数。
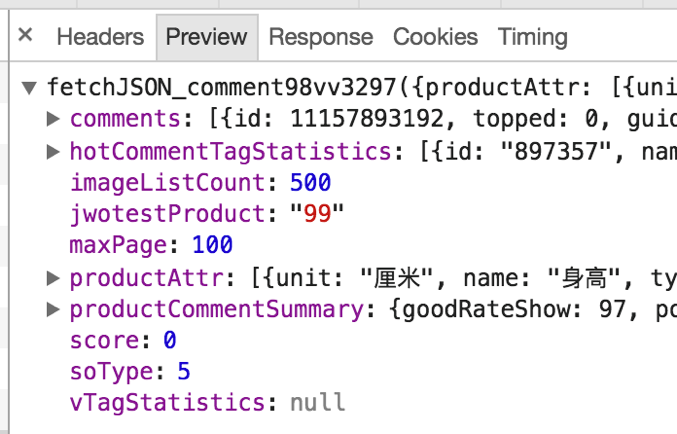
图11 maxPage 属性值
与天猫商城一样,也需要抓取京东多个商品的评论数据(为了抓取一定数量的评论),所以同样也需要获取搜索页面中商品的 ID。商品搜索页面的数据是直接通 HTML 代码一同发送到客户端的,所以可以直接定位到某个商品出,通过 BeautifulSoup 获取特定的 HTML 代码。在京东商城中可以通过每个商品的 a 标签的 href 属性值提取商品 ID,因为每个商品页面都是用商品 ID 命名的。图12 显示了某个商品的 ID 和搜索页面的关系。
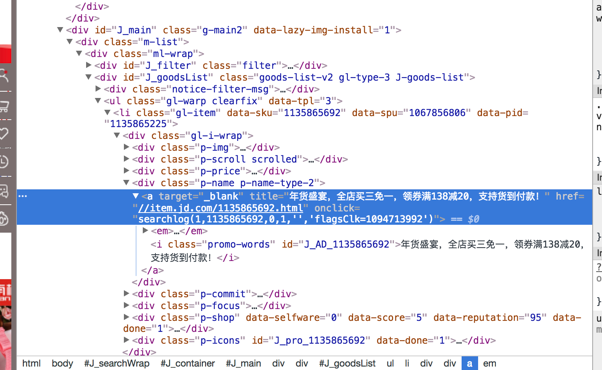
图12 某个商品 ID 和搜索页面的关系
很明显,a 标签的 href 属性值指定的 URL 的页面文件名就是商品 ID,只需要提取这个页面文件名即可。
现在分析数据的第一步已经搞定了,我们已经知道天猫商城的评论数据是如何从服务的获取的,那么下一步就是抓取这些数据,并保存到本地的 SQLite 数据库中。
(python学习交流群 q:467604262)