机器学习的数据:文件csv
数据集的结构:
kaggle 大数据竞赛平台、真实数据、数据量巨大
uci 专业数据集,覆盖了生活的方方面面
scikit-learn 数据量较小,方便学习。
结构: 特征值+目标值。
房子面积、位置、楼层、朝向为特征值
| 房子面积 | 房子位置 | 房子楼层 | 房子朝向 | 目标值 | ||
| 样本1 | 数据1 | 80 | 9 | 3 | 0 | 80 |
| 样本2 | 数据2 | 100 | 9 | 5 | 1 | 120 |
| 样本3 | 数据3 | 80 | 10 | 3 | 0 | 100 |
有些数据集可以没有目标值
特征工程:对数据集中特征的处理,将文本中的特征转化为数字
使用工具sklearn(不仅限于这个)
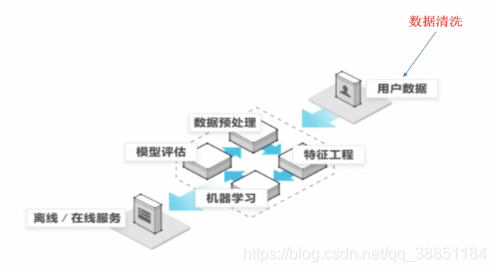
下图是机器学习的整个流程。
安装sklearn(需要numpy,pandas等库)
在Python3的虚拟环境中,mkvirtualenv -p /.../ ml3
ubuntu的虚拟环境中运行:pip install Scikit-learn
检查是否可以使用:import sklearn
tf: term frequency 词频率 出现的次数
idf inverse document frequency 逆文档频率 log(总文档数量、本次出现文档的数量)
tf*idf 称为 重要性
可以将词语按照重要性进行从大到小排序,这样可以得出一篇文章中关键词汇从而进行分类处理。
from sklearn.preprocessing import MinMaxScaler
def mm():
'''归一化处理'''
mm = MinMaxScaler()
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
if __name__ == "__main__":
mm()当异常值比较多的时候,直接使用归一化会影响最大最小值,从而影响最后结果的准确性。由于标准化是大批数据进行,所以一般在归一化前进行标准化。
如何处理缺失值?
1、删除 如果缺失值比较多,删除的话会大大减少数据量(一般不用)
2、填补 平均数、中位数进行填补