好久没有更新博客了,这次主要想整理一下之前学习过的机器学习和深度学习有关的知识。我本身数学专业基础比较薄弱,另外主要做计算机视觉应用所以这个系列的文章并不会涉及很多数学理论知识,学习这些机器学习方法也主要是为了找工作而用,主要了解其中的思想和非常基础的推导过程。
一、统计学习的分类
统计学习方法是基于数据构建统计模型从而对数据进行预测与分析。主要分为四大类:监督学习、非监督学习、半监督学习和强化学习(由于这本书主要就是在介绍监督学习,所以我也主要以监督学习在计算机视觉上的应用主流算法为主)。
监督学习:任务是学习一个模型,使模型能够对任意给定输入,对其相应的输出做出一个很好的预测。(这是这本书给的定义,感觉总结出来,不就是预测吗)
二、监督学习
1、输入空间、特征空间、输出空间
这个很好理解我在这就给大家举个简单的例子:如果我们要去给一些猫狗图片进行分类{猫:0,狗:1}。输出空间就为{0,1}这两个值。假设图片大小为10x10x3,我们直接把整张图传入到模型中,那么输入空间就是300维的一个向量,向量中的每一个维度的取值为{0,1,2,...,255} 这就是输入空间。那么特征空间又是什么呢?有时候我们直接假设特征空间等于输入空间(上面那个例子就是),有时候特征空间不能假设成输入空间,还是以猫狗分类举例,我们实验过直接输入原图到模型,发现识别率很低,那么我们做了一项工作,叫做特征工程,我们从每张图片中提取了一些特征(颜色特征,纹理特征,几何特征等等)组成了一个新的n维的向量,将这个n维向量输入到模型中,发现得到的结果又提高。这个向量所在的空间就是特征空间。(大家不用纠结特征空间,不是重点)
2、不同的预测任务
这本书把预测任务分为了三类:输入变量与输出变量均为连续变量的预测问题称为回归问题(例如预测天气气温,股价);输出变量为有限个离散的预测问题称为分类问题(猫狗分类);输入输出变量均为变量序列的预测问题称为标注问题。
3、监督学习的问题化

上图介绍了一下监督学习的问题具体是个啥样的,模型分为概率模型和非概率模型。
三、统计学习三要素(重点)
方法 = 模型 + 策略 + 算法
1、模型
模型不用多说,就是条件概率分布或者决策函数(一般都是带参数的)
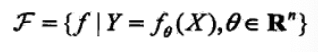
![]()
模型还有一种分类方法:生成模型和判别模型。生成模型,先学习出联合分布,再计算出条件分布。判别模型,直接学习出决策函数或者条件分布。
2、策略
有了模型的假设空间,那么我们应该按照什么样的学习准则来选择最优的模型呢?这个学习准则就是策略。这里要先引入两个新的概念,损失函数和风险函数。损失函数:度量模型一次预测的好坏;风险函数:度量平均意义下模型预测的好坏。(说白了,损失函数就是拿一次来试,风险函数就是拿很多次来试)

风险函数时损失函数的期望值(这里监督学习都有假设X,Y具有联合概率分布P(X,Y)):
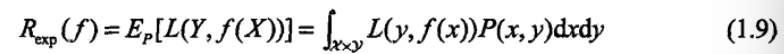
显然我们需要找能使风险函数最小的模型,但是这里又有一个病态的问题了 ,如果能计算出联合分布,那不就能求出边缘分布,那不就能计算出条件分布了吗?那就不需要计算风险函数了。但联合分布一般都是未知的,所以风险函数又求不出来,那怎么办?为了解决这个问题,科学家们提出了经验风险最小化和结构风险最小化这两种策略。经验风险最小化,计算训练集损失函数值得平均值。

但是这个策略也会存在一些问题,那就是当样本小时,不够准确,容易产生过拟合现象。结构风险最小化:
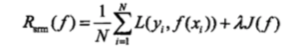
增加一个惩罚项,由一个大于0 的常数乘以模型的复杂度组成。(举个很简单的例子,一个平面有很多样本点,要对这些点分类, 你得到一些模型,一次函数,二次函数,三次函数....n次函数,你观察发现次数越多拟合越好,如果按照经验风险最小化策略,你显然会选择n次函数,但是这个模型因为样本数量不够容易过拟合,于是加入惩罚项,次数越多惩罚项越大,最终得到的模型可能就不是n次模型了)
3、算法:如何通过策略来求得模型的参数。
总结:本章有些知识我并没有细讲,有些过于简单(标注问题,回归问题定义,交叉验证),有些比较深奥但是不需要掌握(泛华能力的那些公式)。这系列的文章我会尽量一天一更,一次更新尽量做到将一章的内容讲好,谢谢大家观看。又不懂的问题可以加我微信:13027158275。也可以加入图像处理学习交流群:709538582