初学爬虫时用的就是requests库,毕竟用起来非常简单方便,而且功能很强大,使用的范围也很广,非常适合初学者学习。对于常见的许多网站,都可以很轻松地爬取,而且也便于对更深层次的学习打好基础。
准备工作
第三方库,采用pip可以很方便地安装:
pip install requests
初步使用
requests的使用比urllib要简单且简短一点,获取网页信息直接采用 get() 方法:
import requests
r = requests.get('https://www.csdn.net')
print(type(r))
print(r.status_code)
print(r.encoding)
print(type(r.text))
print(r.text)
print(r.cookies)
运行结果(省略部分信息):
<class 'requests.models.Response'>
200
UTF-8
<class 'str'>
<!DOCTYPE html>
<html>
'''
'''
<html>
<RequestsCookieJar[<Cookie dc_session_id=10_1549808098998.845834 for
.csdn.net/>, <Cookie uuid_tt_dd=10_19287189710-1549808098998-794225 for
.csdn.net/>]>
打印出了返回结果的类型,状态码,编码方式,网页源代码,Cookies等内容。
HTTP 请求
这里只介绍2种最常用的请求方法
1.GET 请求
使用 get() 方法主要用来获取网页信息,就像我们在浏览器里面输入内容然后获得信息。基本上没有什么限制,像一些需要登陆后保持Cookies的情况先不说,但是也要满足网站的要求,比如很多网站都需要加上headers信息才能访问,这样能伪装成浏览器。
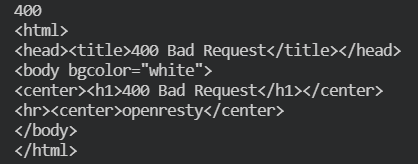
如果直接访问知乎:
import requests
r = requests.get('https://www.zhihu.com')
print(r.status_code)
print(r.text)
结果:
然后再加上headers信息:
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36'
}
r = requests.get('https://www.zhihu.com', headers=headers)
print(r.status_code)
print(r.text)
结果:

可以直接获取到主页信息,User-Agent字段信息,也就是浏览器标识信息。如果不加这个,知乎会禁止抓取。一般情况下,使用 get() 方法时只要注意好headers信息就好了,针对网站所需要的信息适当选取内容。
对于params参数,就是请求时附加的额外信息。
比如,假设要添加两个参数username为name、password为pwd,可以把链接进行更改:http://httpbin.org/get?username=name&password=pwd,与 post() 的data参数是类似的。
2.POST请求
使用 post() 方法主要是附加数据再提交,比如表单信息或JSON数据,把信息放在data参数里面。
可以请求http://httpbin.org/post来看一下情况,该网站会判断如果客户端发起的是POST请求的话,它返回相应的请求信息。
- 发送表单信息:
import requests
data = {'page': 1, 'pwd': s}
r = requests.post("http://httpbin.org/post", data=data)
返回内容:
{
"args": {},
"data": "",
"files": {},
"form": {
"page": "1",
"pwd": "s"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "......",
"url": "http://httpbin.org/post"
}
- 发送JSON数据:
import json
import requests
payload = {'page': 1, 'pwd': 's'}
r = requests.post("http://httpbin.org/post", data=json.dumps(payload))
print(r.text)
返回结果:
{
"args": {},
"data": "{\"page\": 1, \"pwd\": \"s\"}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "23",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": {
"page": 1,
"pwd": "s"
},
"origin": "......",
"url": "http://httpbin.org/post"
}
Cookies
如果某个响应包含一些 cookie,可以直接访问它们,比如:
import requests
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
r.cookies['example_cookie_name']
要想发送 cookies 到服务器,可以使用 cookies 参数:
import requests
url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
超时
可以告诉 requests 在经过以 timeout 参数设定的秒数时间之后停止等待响应。基本上所有的生产代码都应该使用这一参数。如果不使用,程序可能会永远失去响应:
requests.get('http://github.com', timeout=0.001)
会话对象
会话对象让你能够跨请求保持某些参数。它也会在同一个 Session 实例发出的所有请求之间保持 cookie,所以如果向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)
结果:
{"cookies": {"sessioncookie": "123456789"}}
会话也可用来为请求方法提供缺省数据。这是通过为会话对象的属性提供数据来实现的:
import requests
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# 'x-test'和'x-test2'一起发送
s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})