结合python爬虫之requests库(一)部分,我们继续,接下来将首先介绍requests的post方法。我们还是来访问http://httpbin.org/post
import requests
data = {"key1":"value1","key2":"value2"}
url = "http://httpbin.org/post"
re = requests.post(url,data=data)
print(re.text)
执行结果如下所示
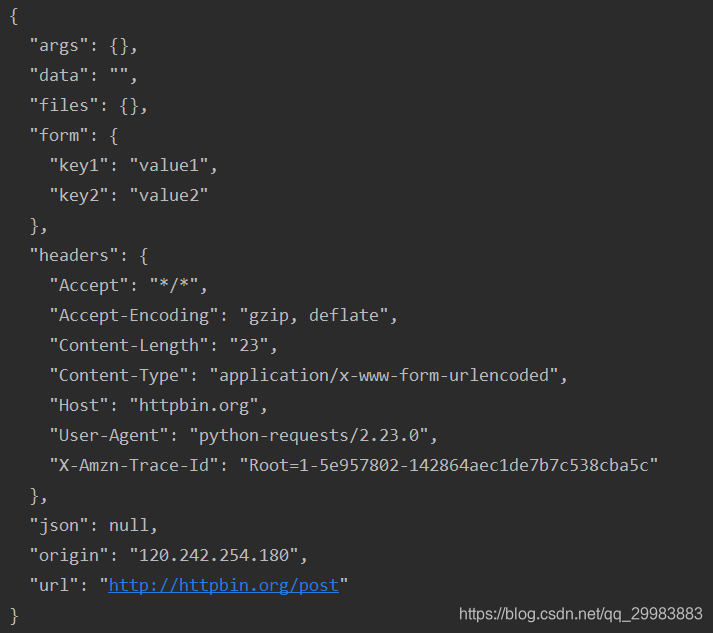
cookies
作为强大的网络爬虫库,怎么能少的了cookie呢,如果大家对cookie内容还是不怎么了解,可以看我之前博客内容。这里,我们继续爬取拉勾网的python的职位信息。
url = "https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput="
data_url ="https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
headers1 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
headers2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
"Referer":url
}
data = {
"first": "true",
"pn": "1",
"kd": "python"
}
re = requests.Session()
#获取cookies
r = re.get(url,headers = headers1)
print(r.text)
#通过上面获取的cookie继续发送消息
r = re.post(data_url,headers = headers2,data = data)
with open("index.html","w",encoding="utf-8") as f:
count = f.write(r.content.decode("utf-8"))
print(count)
打开写入的文件,查看写入的内容

代理
通过requests通过代理来实现对其他服务器的访问,代理IP从西刺免费代理IP获得
url = 'http://www.httpbin.org/ip'
print(requests.get(url).text)
proxies = {
'http': 'http://117.88.176.135:3000'
}
r = requests.get(url,proxies =proxies)
print(r.text)
执行的结果如下图所示,结果上面是本地ip地址信息,下面一个是使用代理的ip地址对服务器的访问,
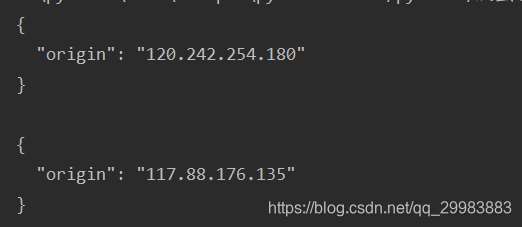
小结
到这里,requests库的主要内容就介绍完毕,在requests库中,我们需要学会使用get post session 以及代理,希望大家把上面的代码在自己理解的基础上写一遍
