简介:Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
计算流程:
- 将流试计算分解成一系列短小的批处理作业,批处理引擎是SparkCore
- 按照输入数据的batch size(如1秒),将数据分解成一段一段转换成RDD
- Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。

架构图:
解释:
-
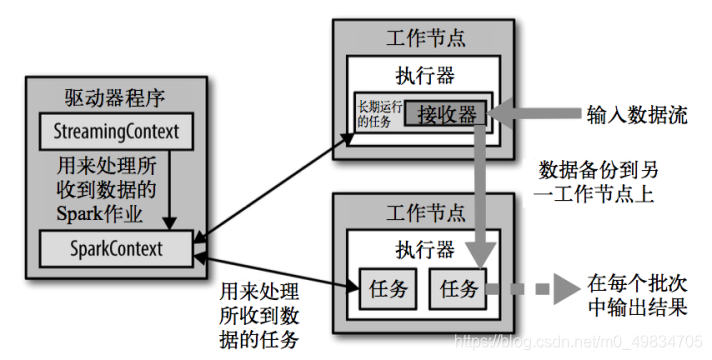
Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次
-
时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在0.5秒到几秒之间
-
每个输入批次都形成一个RDD,以 Spark 作业的方式处理并生成其他的 RDD
-
驱动器程序中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据

-
每个RDD代表数据流中一个时间片内的数据
原理详细图解:
-
按照时间间隔(BatchInterval 0.5s 到 几秒不等) 划分数据为微批次(Micro-Batch),每批次数据当做RDD,再进行处理分析

-
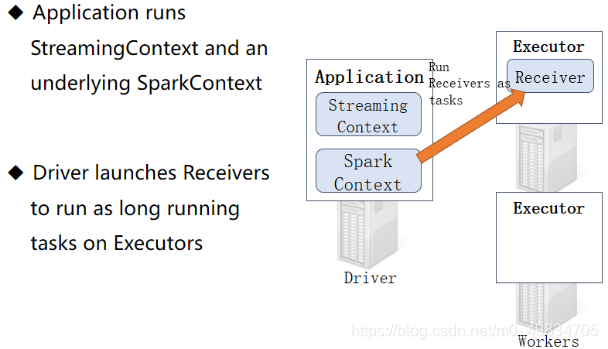
创建StreamingContext流试上下文对象,但是底层还是SparkContext

-
启动接收器Receiver,Receiver作为Task任务运行在Executor中,并且一直运行,一直接收数据
-
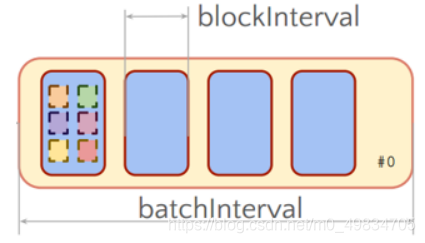
Receive按照时间间隔来接收数据,将流试数据划分为多个Block块,划分流式数据的时间间隔BlockInterval,默认值为200ms,通过属性【spark.streaming.blockInterval】设置
-
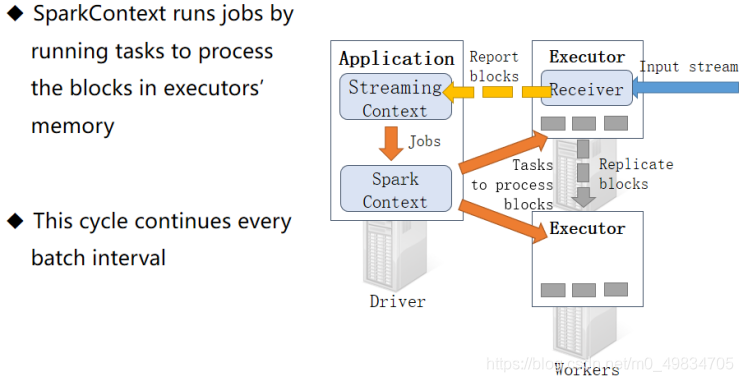
最后到达时间间隔BlockInterval,加载SparkContext处理数据
循环处理流试数据 下图:
总结:
整个Streaming运行过程中,涉及到两个时间间隔:
-
批次时间间隔:BatchInterval
每批次数据的时间间隔,每隔多久加载一个Job; -
Block时间间隔:BlockInterval
接收器划分流式数据的时间间隔,可以调整大小哦,官方建议最小值不能小于50ms;
默认值为200ms,属性:spark.streaming.blockInterval,调整设置