由于非科班出身,所以像数据结构与算法类,通常底子比较薄,这里主要对常见的数据结构作一下学习与总结;
mysql innodb b+树;
先从二叉树研究起:
二叉树:
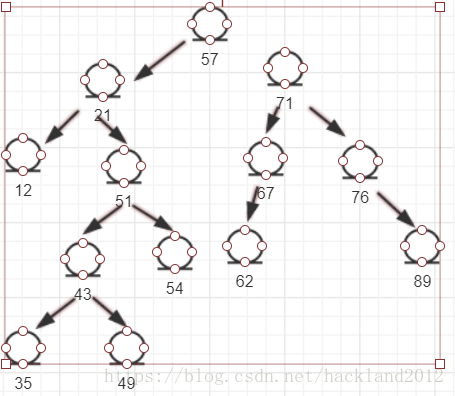
特点:就是最多只有两个孩子,而且,左儿子<父亲<右儿子;
平衡二叉树:(由于上面的二叉树有多种组合形式,可能导致查找效率低下;这个时候就需要设计出更高效的二叉树)
平衡二叉树,其左子树与右子树的深度之差小于等1;这样查找效率高;如下:(-1:为左子树与右子树深度之差)
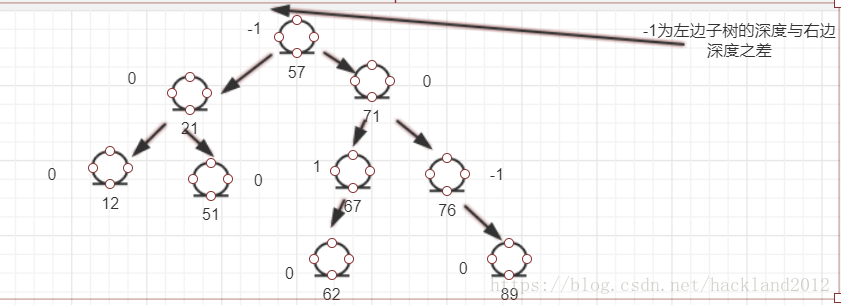
说白了,这种平衡就是容易查找到想要查找的值;
B_ 树: 如果 説 上面是二叉平衡树,那么b_又是对上面进行了优化叫多叉平衡树;也还是为了查找效率而定的;
相对严谨一点的定义法:
B 树又叫平衡多路查找树。一棵m阶的B 树 (注:切勿简单的认为一棵m阶的B树是m叉树,虽然存在四叉树,八叉树,KD树,及vp/R树/R*树/R+树/X树/M树/线段树/希尔伯特R树/优先R树等空间划分树,但与B树完全不等同)的特性如下:
-
树中每个结点最多含有m个孩子(m>=2);
-
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
-
若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
-
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);( 读者反馈@冷岳:这里有错,叶子节点只是没有孩子和指向孩子的指针,这些节点也存在,也有元素。@研究者July:其实,关键是把什么当做叶子结点,因为如红黑树中,每一个NULL指针即当做叶子结点,只是没画出来而已)。
-
每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。如下图所示:
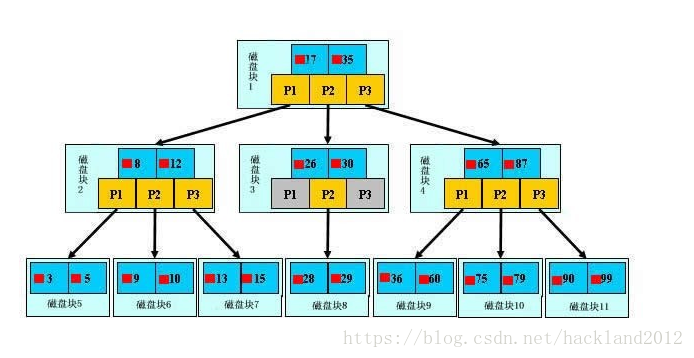
备注:拿根结点分析:17,35为关键字,用k1,k2代替;p1,p2,p3,代表指针,指向指树;
所有叶子结点在同一层次;且没有关键字的信息;
- 有n棵子树的结点中含有n-1 个关键字; (此处颇有争议,B+树到底是与B 树n棵子树有n-1个关键字 保持一致,还是不一致:B树n棵子树的结点中含有n个关键字,待后续查证。暂先提供两个参考链接:①wikipedia http://en.wikipedia.org/wiki/B%2B_tree#Overview;②http://hedengcheng.com/?p=525。而下面B+树的图尚未最终确定是否有问题,请读者注意)
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
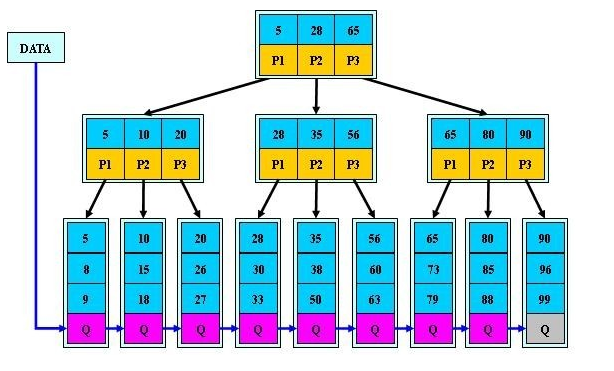
为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对于B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
读者点评
本文评论下第149楼,fanyy1991针对上文所说的两点,道:个人觉得这两个原因都不是主要原因。数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
B+-tree的应用: VSAM(虚拟存储存取法)文件(来源论文 the ubiquitous Btree 作者:D COMER - 1979 )
严谨的,请参考网址:https://blog.csdn.net/m0_37973607/article/details/79045950