以下是学习恋上数据结构与算法的记录,本篇主要内容是B树基本概念
◼B树(B-tree、B-树)
●B树是一种平衡的多路搜索树,多用于文件系统、数据库的实现(数据库所用的树一般为200-300阶B树)
● 1个节点可以存储超过2 个元素、可以拥有超过2 个子节点
●拥有二叉搜索树的一些性质:平衡,每个节点的所有子树高度一致,比较矮、高度低。
◼m阶B树的性质(m≥2)
●假设一个节点存储的元素个数为x
●根节点:1≤x≤m − 1
●非根节点:┌ m/2 ┐ − 1≤x ≤m − 1
( ┌ m/2 ┐是向上取整,即取与结果最接近的比结果大的整数)
●如果有子节点,子节点个数y =x + 1
✓根节点:2≤y ≤m
✓非根节点:┌ m/2 ┐≤y ≤m
➢比如m = 3,2≤y≤3,因此可以称为(2, 3)树、2-3树
➢比如m = 4,2≤y≤4,因此可以称为(2, 4)树、2-3-4树
➢比如m = 5,3≤y≤5,因此可以称为(3, 5)树
➢比如m = 6,3≤y≤6,因此可以称为(3, 6)树
➢比如m = 7,4≤y≤7,因此可以称为(4, 7)树
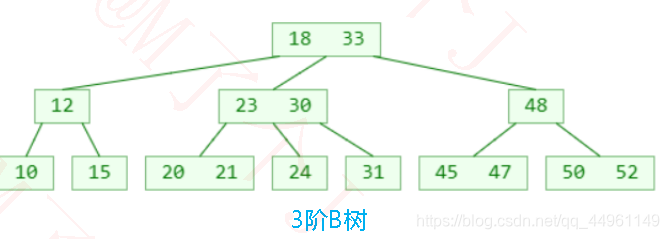
◼B树VS二叉搜索树
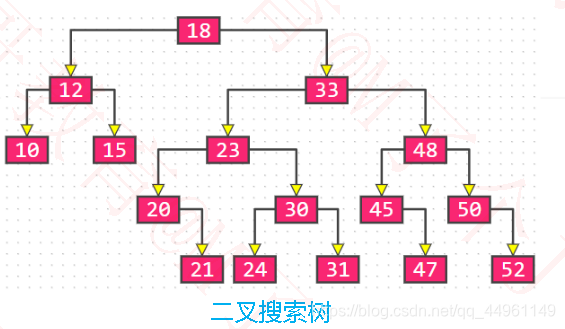 ●B树和二叉搜索树,在逻辑上是等价的
●B树和二叉搜索树,在逻辑上是等价的
➢多代节点合并,可以获得一个超级节点
➢2代合并的超级节点,最多拥有4 个子节点(至少是4阶B树)
➢3代合并的超级节点,最多拥有8 个子节点(至少是8阶B树)
➢n代合并的超级节点,最多拥有2n个子节点(至少是2n阶B树)
●m阶B树,最多需要log2m代合并
◼添加
◼新添加的元素必定是添加到叶子节点
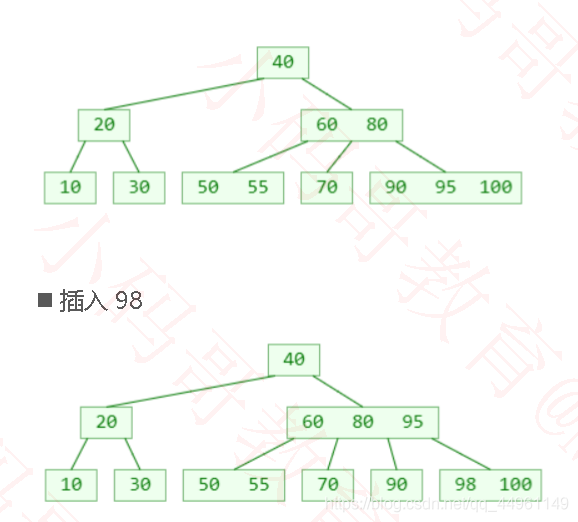 最右下角的叶子节点的元素个数将超过限制,这种现象可以称之为:上溢(overflow)
最右下角的叶子节点的元素个数将超过限制,这种现象可以称之为:上溢(overflow)
添加–上溢的解决(假设5阶)
◼上溢节点的元素个数必然等于m
◼假设上溢节点最中间元素的位置为k,将k 位置的元素向上与父节点合并
◼将[0, k-1] 和[k + 1, m -1] 位置的元素分裂成2 个子节点
✓这2 个子节点的元素个数,必然都不会低于最低限制(┌ m/2 ┐ − 1)
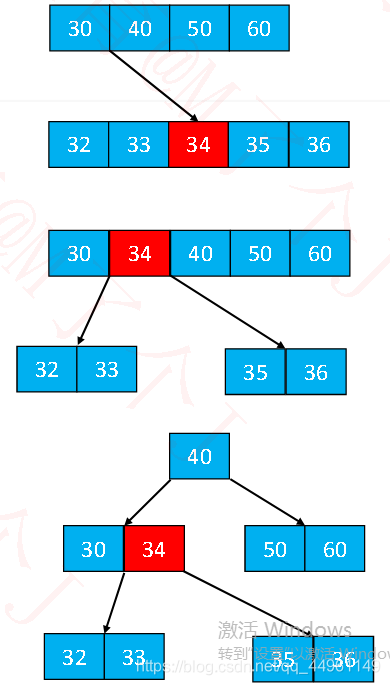
◼一次分裂完毕后,有可能导致父节点上溢,依然按照上述方法解决最极端的情况,有可能一直分裂到根节点
◼删除
◼删除–叶子节点
●假如需要删除的元素在叶子节点中,那么直接删除即可
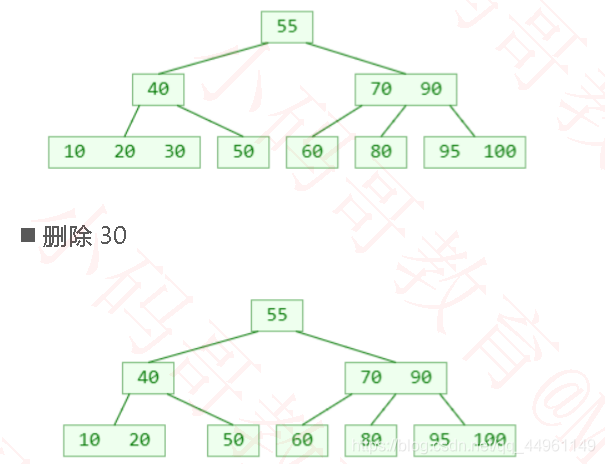 ◼删除–非叶子节点
◼删除–非叶子节点
●假如需要删除的元素在非叶子节点中
1.先找到前驱或后继元素,覆盖所需删除元素的值
2.再把前驱或后继元素删除

●非叶子节点的前驱或后继元素,必定在叶子节点中,所以这里的删除前驱或后继元素,就是最开始提到的情况:删除的元素在叶子节点中
◼真正的删除元素都是发生在叶子节点中
但叶子节点被删掉一个元素后,元素个数可能会低于最低限制(≥┌ m/2 ┐ − 1),这种现象称为:下溢(underflow)
删除–下溢的解决
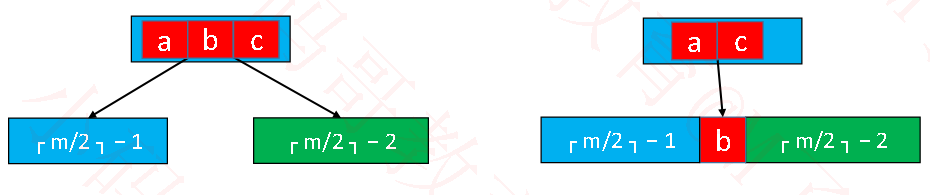
●下溢节点的元素数量必然等于┌ m/2 ┐ − 2
●如果下溢节点临近的兄弟节点,有至少┌ m/2 ┐ 个元素,可以向其借一个元素,将父节点的元素b 插入到下溢节点的0位置(最小位置),用兄弟节点的元素a(最大的元素)替代父节点的元素b,这种操作其实就是:旋转

●如果下溢节点临近的兄弟节点,只有┌ m/2 ┐− 1个元素,将父节点的元素b 挪下来跟左右子节点进行合并,合并后的节点元素个数等于┌ m/2 ┐ + ┌ m/2 ┐ − 2,不超过m − 1,这个操作可能会导致父节点下溢,依然按照上述方法解决,下溢现象可能会一直往上传播
 例如:
例如: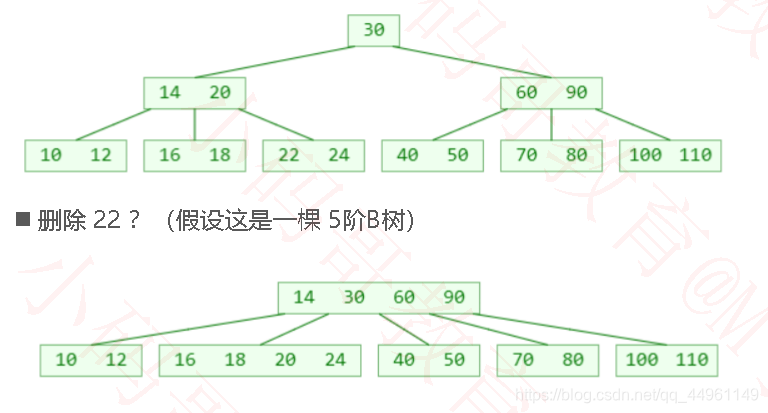
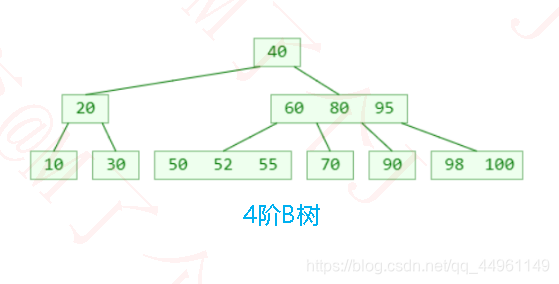
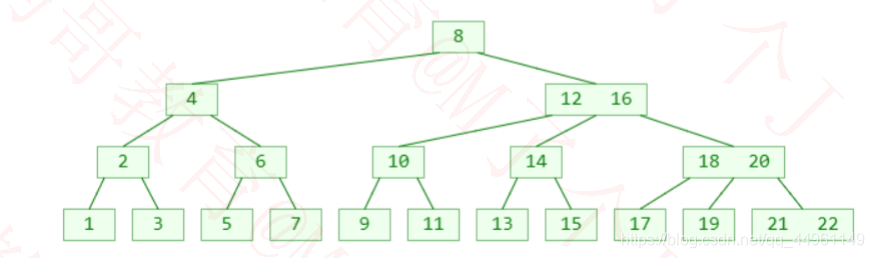
◼4阶B树
●如果先学习4阶B树(2-3-4树),将能更好地学习理解红黑树
●4阶B树的性质:
➢所有节点能存储的元素个数x :1≤x≤3
➢所有非叶子节点的子节点个数y :2≤y ≤4
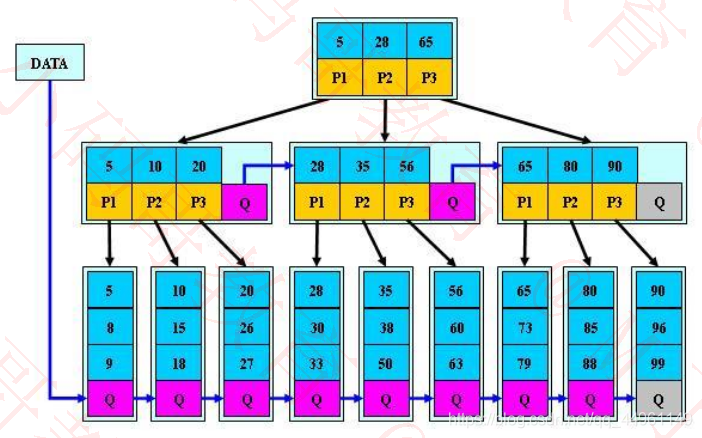
B+树
B+树是B树的变体,常用于数据库和操作系统的文件系统中,MySQL数据库的索引就是基于B+树实现的
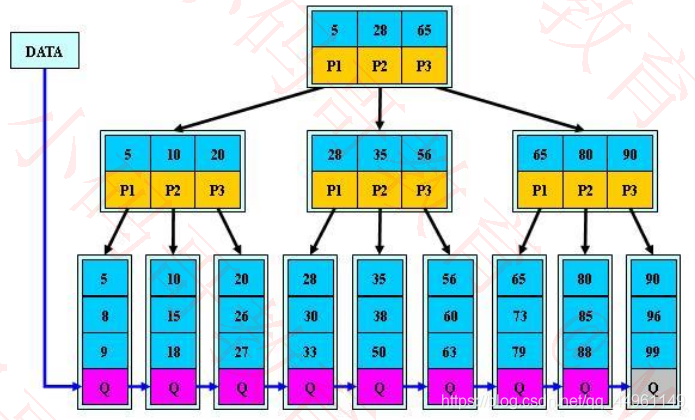
B+树的特点:分为内部节点(非叶子)、叶子节点2种节点
✓内部节点只存储key,不存储具体数据
✓叶子节点存储key和具体数据
所有的叶子节点形成一条有序链表
m阶B+树非根节点的元素数量x
✓┌ m/2 ┐≤x ≤m
操作系统读取硬盘数据的过程
①操作系统将LBA传送给磁盘驱动器并启动读取命令
✓LBA(Logical Block Address,逻辑块地址)
✓比如类似设备号4、磁头号4、磁道号8、扇区号16、扇区计数8这样的信息
②磁盘驱动器根据LBA将磁头移动到正确的磁道,盘片开始旋转,将目标扇区旋转到磁头下
③磁盘控制器将扇区数据等信息传送到一个处于磁盘界面的缓冲区
④磁盘驱动器向操作系统发出“数据就绪”信号
⑤操作系统从磁盘界面的缓冲区读取数据✓既可以按照一个字节一个字节的方式读取
✓也可以启动DMA(Direct Memory Access,直接内存访问)命令读取
磁盘完成IO操作的时间
主要由寻道时间、旋转延迟时间、数据传输时间3部分构成
寻道时间(seek)
✓将读写磁头移动至正确的磁道上所需要的时间,这部分时间代价最高
旋转延迟时间(rotation)
✓盘片旋转将目标扇区移动到读写磁头下方所需要的时间,取决于磁盘转速
数据传输时间(transfer)
✓完成传输数据所需要的时间,取决于接口的数据传输率,通常远小于前两部分消耗时间
决定时间长短的大部分因素是和硬件相关的,但所需移动的磁道数是可以通过操作系统来进行控制的
减少所需移动的磁道数是减少整个硬盘读写时间的有效办法
合理安排磁头的移动以减少寻道时间就是磁盘调度算法的目的所在
MySQL的索引底层为何使用B+树?
为了减小IO操作数量,一般把一个节点的大小设计成最小读写单位的大小
MySQL的存储引擎InnoDB的最小读写单位是16K
对比B树,B+树的优势是
每个节点存储的key数量更多,树的高度更低
所有的具体数据都存在叶子节点上,所以每次查询都要查到叶子节点,查询速度比较稳定
所有的叶子节点构成了一个有序链表,做区间查询时更方便
B*树
B树是B+树的变体:给内部节点增加了指向兄弟节点的指针
m阶B树非根节点的元素数量x
✓┌ 2m/3 ┐≤x ≤m