支持向量机(Support Vector Machine, SVM)
1、算法的基本思想
在机器学习算法中,分类问题最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类的样本分开,但是这样的超平面很多,如何选择“合适的”超平面是我们应当需要考虑的。

如上图的二维空间中划出的三条超平面(
),显然将
作为分类的超平面最为合适,其具有较强的鲁棒性和泛化能力。可是这样划分的理论依据又是什么呢?
2、支持向量机的理论依据
在样本空间中,我们可以以如下的线性方程来描述一个超平面
:
其中 为超平面的法向量(即与超平面垂直的向量),其决定了超平面的方向, 为位移量,决定了超平面与原点之间的距离,样本空间中任意一点 到超平面 的距离为:
设:
则有
如果我们要求再高一点,假设决策面正好处于间隔区域的中轴线上(如图中所示黑色实线),并且相应的支持向量对应的样本点到决策面的距离为 ,那么公式 就可以进一步写成:
将 式中左右两边同时除以 ,并令 , ,则可得:
其实, 与 为同一直线(或超平面),则式 又可写成
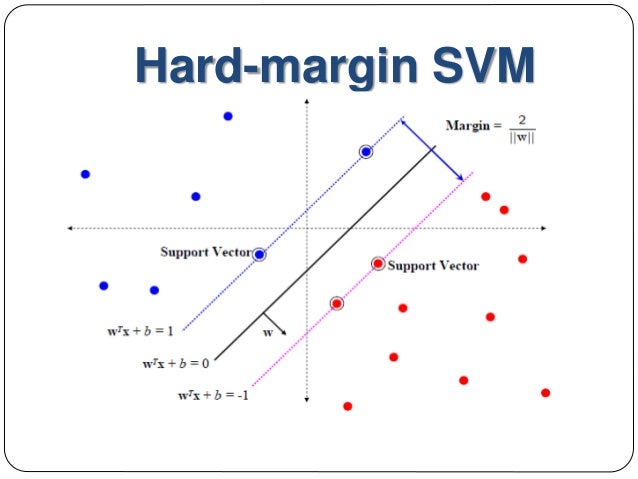
如图
所示,离超平面最近的点称为“支持向量”,两个异类支持向量到超平面的距离之和为:
其中 和 为支持向量,他们满足 和
故:
我们知道当 取得最大值时,超平面恰好属于两类样本点的正中间,此时能较好的划分两类样本,因此问题转化为求参数 和 在何时的取值使得 的值最大
显然当 在约束条件 的约束条件下取最大值的时候 可取最大值,问题也可转化为求
这就是支持向量的基本型。
如何解决这一问题,过程涉及高等数学中的拉格朗日乘子法来解决,在此不予详细说明,感兴趣的读者可自行查阅书籍。
3、在Python中使用SVM进行分类

from sklearn import svm
X = [[2, 0], [1, 1], [2,3]]
y = [-1, -1, +1]
clf = svm.SVC(kernel = 'linear')
clf.fit(X, y)
print clf
# get support vectors
print clf.support_vectors_
# get indices of support vectors
print clf.support_
# get number of support vectors for each class
print clf.n_support_
a = clf.predict([[3,3]])
print(a)