支持向量机SVM在复杂的非线性方程方面,比逻辑回归和神经网络表现的更为清晰、强大。
1. 通过逻辑回归了解SVM大致形式
设z = thetaT * x
假设函数:h(x) = 1 / (1 + e^(-z))
分类为1 if h > 0.5 即 z >0
分类为0 if h < 0.5 即 z <0
代价函数:

两图分别为y=1和y=0时的曲线,粉色手绘图为曲线的近似折线表示。为别取名cost1(z)和cost0(z)。

该图中,最上面是逻辑回归的正则化代价函数,也就是优化目标函数。
m为常数,消掉m后对求解没有影响。lamda正则化参数为常数。逻辑回归中函数形式为A+lamda*B,在SVM中表示为C*A+B。C可理解为1/lamda。
于是得到最下面的SVM代价函数,也就是SVM的优化目标函数。
与逻辑回归最大的区别是:
cost1与cost0为原h(x)的近似取现,但并不相同。这个新曲线的性质将决定SVM于逻辑回归的差别。
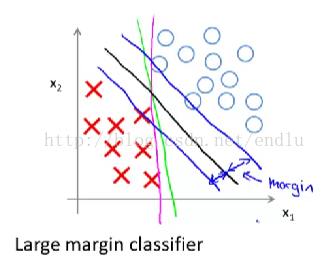
2. 大间距分类器
SVM也被叫做大间距分类器。

想最小化上面的代价函数,当y=1时,我们希望z>=1, y=0时希望z<=-1。逻辑回归中这个边界值为0,现在变为1 与 -1. 这是SVM的一个有趣的性质。也因此成为大间距分类器。
这里先假设C是个非常大的数,cost1和cost0就会取值0保证最小化。优化问题就变为了:

这时,SVM会保证最大间距的进行分类,即图中的黑色边界。
3. 数学原理
(1) 向量内积 = 向量1在向量二上的投影长度p * 向量二的范数(长度)。
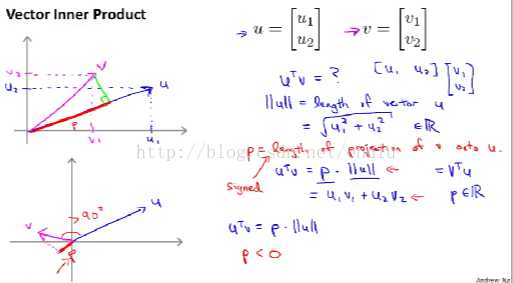
(2) 考虑上面简化的优化目标函数1/2 * (theta1^2 + theta2^2 + ... + thetan^2), 括号内开放再平方,即得到1/2 * (||theta||)^2。 ||theta||表示theta的范数。


比较上图中两种边界(绿色线),理解下SVM会选择哪个。
第一幅图中,x1 x2两个样本点在theta上的投影的长度p很小,为了保证p*||theta|| >1 或 <-1, 则||theta||响应会比较大。但是这由于我们的目标最小化1/2 * (||theta||)^2 相违背。
第二幅图中,则相反。p比较大,theta则可以较小,与目标一致。
所以SVM会选择图二中的边界。直观看来,就是会选择距离样本间距较大的边界。
(3) 上面讨论的都是在C很大时的情形。实际中如果C很大,SVM容易受异常值的影响得出并不合理的边界。
后面会讨论对于复杂情况、非线性可分等情形下,SVM的具体应用。
4.核函数

上图中假设我们有三个核,利用高斯核函数计算出样本与每个核之间的相似度。当样本与一个核很接近时,相似度结果会接近于1;很远时则接近于0.
利用核函数的方法是:m个样本作为m个核,每个点与每个核的m个相似度作为特征,构建预测函数h(x)。

优化目标变为:

5. 应用
应用SVM时,首先面临两个选择:
(1) 参数C的选择:影响偏差、方差。
(2) 核函数的选择:
- 不使用核函数,将得到线性边界。适用:训练样本m很小,特征数n比较多,此时更适合线性分类,因为如果尝试在高位空间内进行复杂的非线性分类,但又没有足够的样本,非常容易过度拟合。
- 高斯核函数。此时需要选择参数sigma。适用:特征数n比较小,但是样本数m比较大。

使用高斯核函数,需要我们做:
- 提供核函数实现
- 归一化特征,如果特征值大小相差很大。因为核函数计算中,分子部分等于两向量各特征差的平方和。这将导致整个结果几乎只受值较大的特征影响。
除了这种选择,还有其他的核函数,但必须满足莫塞尔定理,确保各种软件包能用数值优化技巧来快速的计算出结果theta。
6. 多分类
在SVM解决多分类问题时,如果软件包支持多分类,那么可以直接使用。否则可以使用之前提到的one-vs-all方法。训练k个函数,每个边界将一种分类与其他类别区分开。使用时,选择值最大的那个函数的分类结果。
7.SVM与逻辑回归的选择
如果n相对于m大很多,那么通常使用逻辑回归或者不使用核函数的SVM。
如果n很小,m大小适中,使用核函数的SVM会是更好的选择。
如果n很小,m非常大,这时添加、创造更多的特征,然后使用逻辑回归或者无核SVM。核函数SVM此时将会非常慢。
对于所有的这些情况,一个设计的好的神经网络都可以工作的不错。但是有时不使用神经网络的原因是它训练起来很慢,尤其对于第二种情况。相比之下,一个SVM比较好的软件包,可以很高效的完成训练。SVM也不需要担心局部最优解问题。