最近Google开源了他们的项目:sketch rnn,使AI可以自由的作画,由此衍生的,有人用它拓展生成矢量汉字,有人用VAE+sketch rnn使小姐姐跳舞。
传送门:
https://github.com/jsn5/dancenet


下面进入正题,说一下sketch-rnn
抽象的视觉传达是人们彼此传达观点的关键部分。小孩子能够形成仅用少量笔画就能描绘物体的能力。这些简单的绘画可能不会像照片那样能表达现实,但是它们却能告诉我们一些有关人类如何表示和构建他们周围世界的图像的信息。

Vector drawings produced by sketch-rnn.
在先前的论文“A Neural Representation of Sketch Drawings”中,提出了一种生成递归神经网络,它能够生成简单物体的草图,目的是训练一个能绘画和概括抽象概念的机器,并且它的思维方式与人类类似。在手绘草图的数据集上训练模型,每个草图代表控制钢笔的运动序列:要移动到哪个方向,什么时候提笔,何时停止绘画。在这个过程中,创建了一个有许多潜在应用的模型,它不仅有望帮助艺术家创造作品,还能够帮助老师教学生绘画。
尽管目前已经在图像生成建模方面做了大量工作(目前的主要手段是利用神经网络),但是大部分工作关注的是将光栅图像表示为二维像素网格。尽管这些模型能够生成逼真的图像,但是由于二维像素网格的高维度,这就成了生成连续结构图像的主要挑战。例如,这些模型有时候能够产生拥有三只或更多只眼睛的猫的有趣图像,或者产生具有多个头的狗的图像。

在128 x 128的ImageNet数据集上训练先前的GAN模型,生成动物的例子。上面的图像是Generative Adversarial Networks, Ian Goodfellow, NIPS 2016 Tutorial的Figure 29
在这项工作中,研究了一个更低维度的基于矢量的表示,这也受益于人类绘画的灵感。模型sketch-rnn基于seq2seq自动编码框架。它包含了变分推理和将超网络(hypernetworks)用作递归神经网络单元。seq2seq自动编码框架的目标是训练一个将输入序列编码为浮点数向量的神经网络,这个向量称为latent vector,并使用解码器从latent vector重构输出序列。
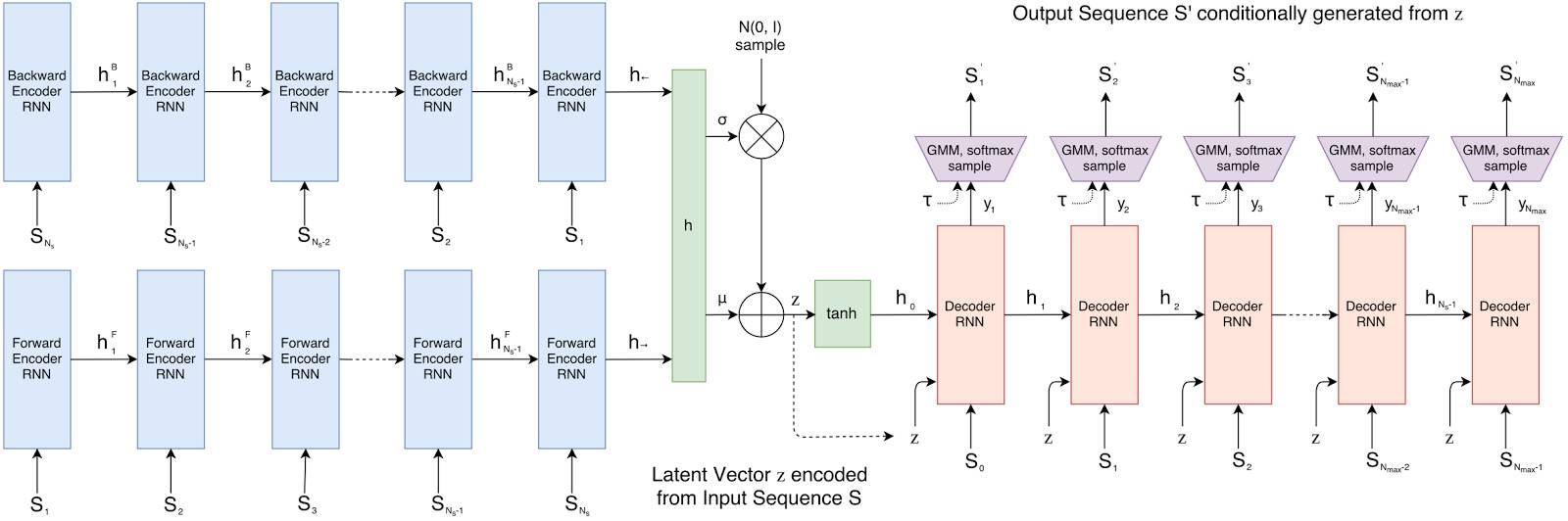
Schematic of sketch-rnn.图
模型中故意向latent vector添加了噪声。论文展示了通过将噪声引入到编码器和解码器之间的通信通道中,该模型就不再能够准确地产生输入草图,而是必须捕获草图的本质作为噪声的latent vector。解码器利用这个latent vector生产了一个用于绘制新图的动作序列。在下图中,将几个猫的草图提供给编码器,然后使用解码器重构草图。

Reconstructions from a model trained on catsketches.图
重要的是,重构的猫的草图不是输入草图的副本,而是与输入具有相似特征的猫的新草图。为了证明这个模型不是简单地复制输入序列,而是实际上学到了一些关于人们绘画猫的方式的信息,可以尝试将非标准草图提供给编码器。
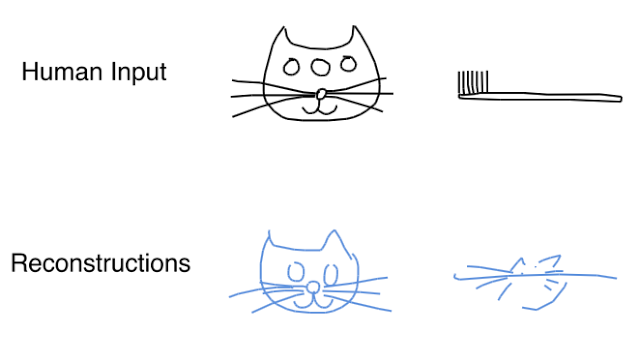
当我将一只三眼猫的草图提供给编码器时,这个模型生成了一个相似的两眼猫。为了表明模型不是简单地从从大量记忆猫草图中选择最接近的正常猫,所以试图输入一些完全不同的东西,比如牙刷草图。网络生成了一个类似猫的草图:长的胡须,这模仿了牙刷的特征和方向。这表明,该网络已经学到了将输入草图编码成一组抽象的猫概念,并嵌入到latent vector,基于此latent vector,网络还能够重构全新的草图。
不相信?我们利用模型重复了这一实验,利用一组猪草图来训练模型,最后得出了相似的结论。当提供一张具有八条腿的猪的草图时,最后模型生成了一个仅有四条腿的类似的猪。如果将一辆卡车草图喂给此模型,可能会得到一个类似卡车的猪。
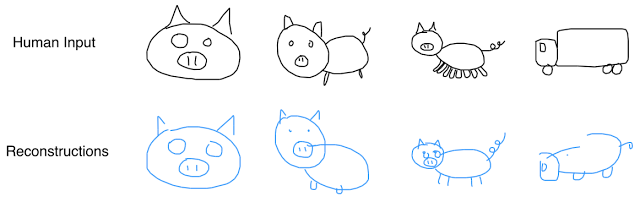
Reconstructions from a model trained on pigsketches.图
为了研究这些latent vectors是如何将概念上的动物特征进行编码,在下图中,首先获得了两个latent vectors,它们是由两个不同的猪的草图中编码而来,这种情况下,一个猪头(绿色盒子)和一只全猪(橙色盒子)。想了解模型是如何学习表示猪的,一种表示的方法就是在不同的latent vectors之间进行插值,并且利用每个被插值的latent vectors来可视化每个草图。在下图中,对猪头的草图到猪的全图演化进行了可视化,这个过程展示了模型是如何组织猪草图的概念的。可以看到,latent vector控制鼻子的大小以及鼻子相对于头部的相对位置,也控制了身体和腿部在草图中的生成。
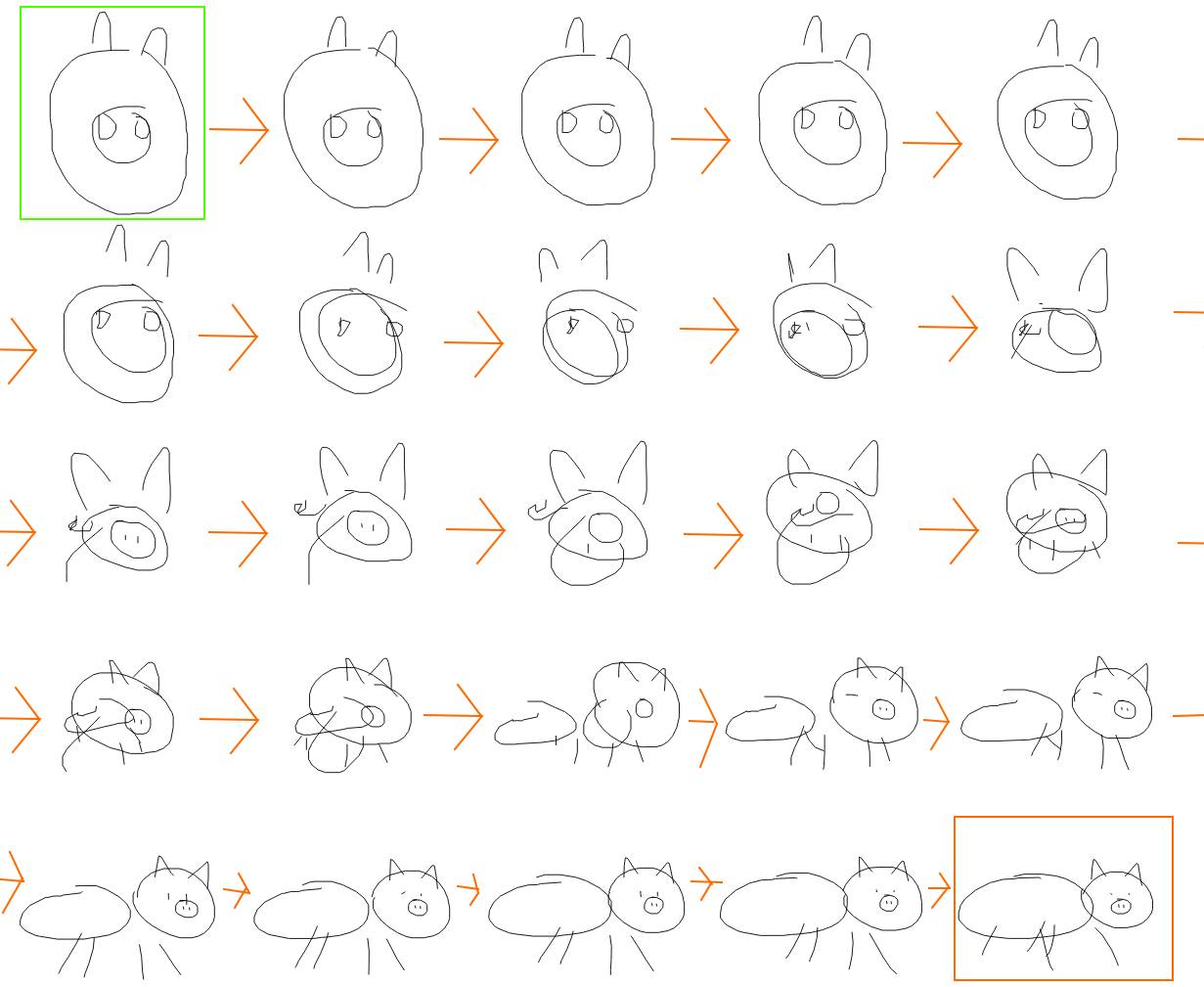
在猪素描画上训练的模型生成的隐空间插值
我们想知道如果我们的模型是否可以学习到很多动物的表示方法,如果可以的话,会是什么样的呢?在下图中,我们通过对一个猫头和一只整猪的隐向量之间进行插值,生成了一些素描。我们可以看到特征表示慢慢的从一个猫头,到带着尾巴的猫,到身体很胖的猫,然后最终变成一只整猪。就好像孩子在学习绘画一样,我们的模型学习如何通过将头,脚和尾巴添加到身体上来构造动物。我们可以看出,我们的模型也能画出猫头,与猪头完全不同。

在猫和猪的素描画上训练的模型的隐空间插值
这些插值样例表明,隐向量实际上对素描的概念特征进行了编码。但是我们能使用这些特征来增强其它没有这类特征的素描吗?例如,将一个身体加在猫头上?
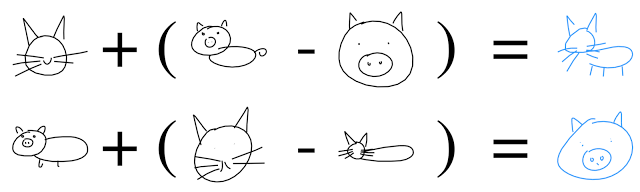
学习到的抽象概念之间的关系,使用隐向量计算进行探索
实际上,我们发现对于在猫和猪素描上训练的模型可以进行素描画之间的类推。例如,我们可以从一个整猪的隐向量中减去一个编码的猪头的隐向量,来得到只表示身体的隐向量。将这个差值和一个表示猫头的隐向量相加,可以得到一只整猫。(猫头+身体=整猫)。这些绘画类推可以让我们发现模型是如何组织隐空间来对多种生成素描的不同概念进行表示的。
创意应用
这个工作除了科研部分,我们对于sketch-rnn的潜在创意应用也同样感到激动。例如,甚至是在最简单的应用中,纸样设计师可以应用sketch-cnn来生成大量类似但都各不相同的服装或墙纸设计。

相似,但是独一无二的猫,由单一的输入画像(绿色和黄色框)生成
正如我们之前所看到的,对于被训练去画猪的模型,如果输入一张卡车的素描,可以变成去画像猪的卡车的模型。我们可以将这一结果延伸至实际应用,或许可以帮助设计者想到能够和目标观众产生更多共鸣的抽象设计。
例如下图,我们将四个不同的椅子素描输入我们的画猫模型,来产生四个像椅子的猫。我们可以更进一步,整合之前描述的插值方法来探索像椅子的猫的隐空间,然后产生一个大的可供选择的生成设计栅格。

探索生成的椅子-猫的隐空间
探索不同物体之间的隐空间可以让有创造力的设计者来寻找不同画作间的有意思的交集和联系

探索日常物体的生成素描的隐空间
隐空间插值从左到右,然后从上到下
我们可以将sktech-cnn的解码模型作为一个独立的模型,并且训练它来预测未完成素描的不同的可能结果。该技术可以应用于帮助画家的创作过程,例如模型可以向画家建议完成一个不完整的素描的各种替代方法。在下图中,我们绘制了不同的不完整的素描(红色),然后让模型提出不同的方法来完成绘画。

该模型从不完整的素描开始(垂直线左边的红色部分素描)然后自动生成不同的完整结果
我们可以更深一步理解这个概念,然后用不同模型来完成同一个不完整的素描。下图中,我们可以看到如何把同一个圆圈和方块变成不同的蚂蚁、火烈鸟、直升机、老鹰、沙发,甚至画刷的一部分。通过使用一个训练来画多种物体的模型集,设计者可以探索创新的方法来和他们的观众交流有意义的视觉消息。
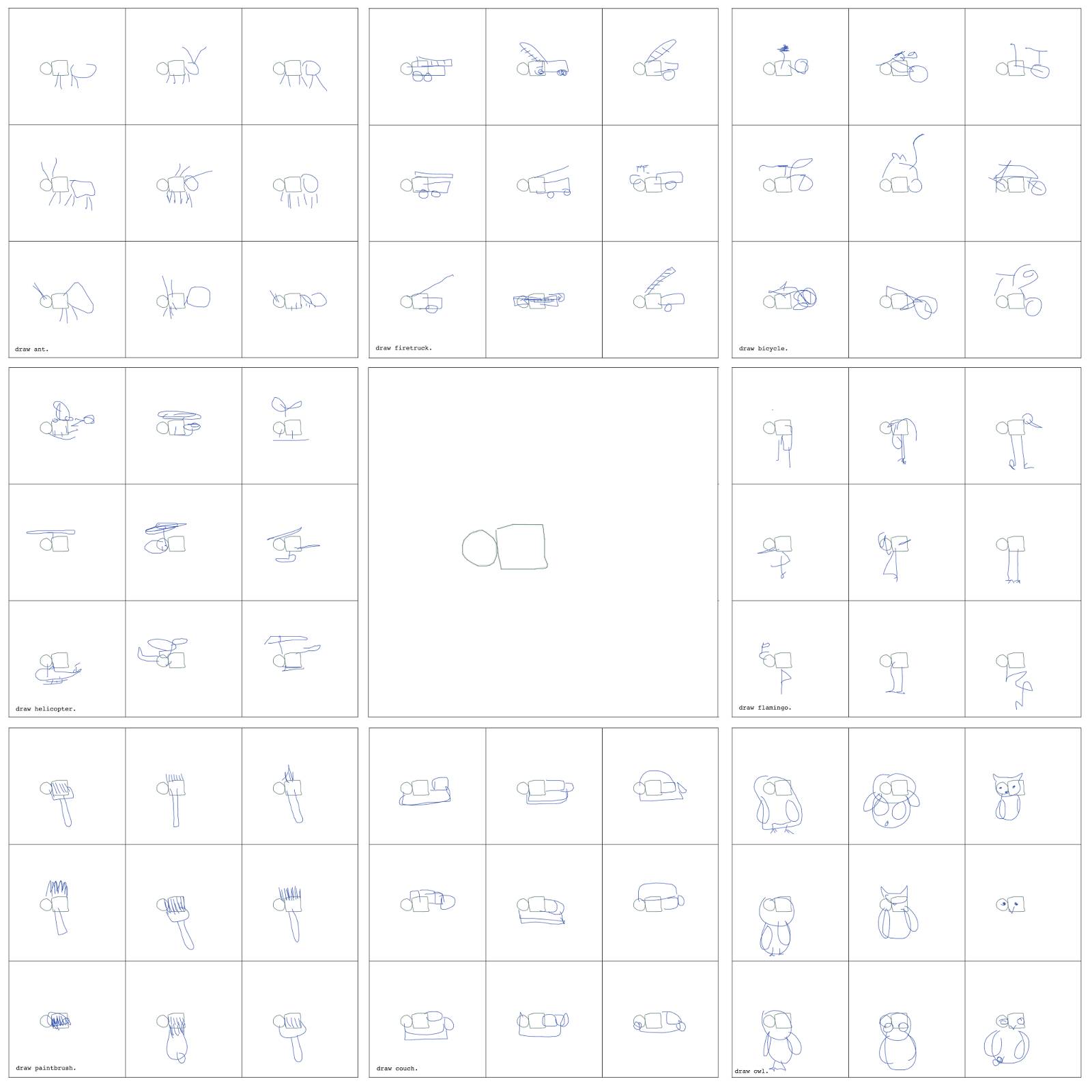
用于绘画不同物体的sketch-cnn模型来预测同样的圆形和方块(中间)的结尾
我们对于生成矢量图模型的未来的各种可能性感到很兴奋。这些模型会让各种方向上的有趣的新创意应用成为可能。他们也可以作为工具来帮助我们提高对于自己的创造力思维过程的理解。如果想了解sketch-cnn的更多细节,请阅读我们的论文《素描绘画的神经网络表示》(A Neural Representation of Sketch Drawings)。
论文解读

摘要:我们提出了sketch-rnn,一个能够构建出日常物体的线条画的循环神经网络(RNN)。该模型在几千张原始的手绘图像上进行训练,表现了几百类物体。这篇文章中,我们概括了条件和非条件的素描生成算法框架,并且描述了一个以向量形式产生连贯素描画的新的鲁棒训练方法。
论文的贡献如下:
概括出了用线条序列组成的向量图像的有条件和无条件生成算法框架。
基于循环神经网络的生成模型可以产生日常物体的向量形式的素描。
提出了一个针对矢量图的训练方法,可以使训练更鲁棒。
探索了条件生成模型中如何用模型的隐空间来表示矢量图。
演示了对隐空间设置前提可以帮助模型生成更清楚的图像。
讨论了该方法的潜在创意应用。
我们也在努力制作一个更大的简单手绘图像数据库,以激励将来对生成模型的研究,并且我们之后会发布我们模型的实现以及开源项目sketch-rnn。
局限性:
1 对于大多数单类别的数据集,sketch-cnn可以对素描画建模,得到最多300个数据点。但是一旦超过这个长度,模型很快就会变得很难训练。
2 对于更复杂类别的图片,例如美人鱼或龙虾,重建误差指标不够好,尤其是与简单类别,例如蚂蚁,人脸相比。
3 sketch-cnn不能对数据库中的全部75类物体素描都进行有效的建模。
结论:
这个工作中,我们开发了一种用RNN对素描画进行建模的方法。Sketch-rnn可以产生完成一幅不完整的素描画的所有可能方法。我们的模型可以将当前的素描画编码到一个隐空间,并且可以在隐空间内有条件的生成类似的素描。我们演示了通过对两个不同素描画的隐空间之间的插值来得到素描画本身之间的插值的意义。在对某一特定类图像进行训练后,我们的模型能够改正输入图像中不正确的特征,并且输出一个具有改正过的性质的相似的图像。我们也演示了我们可以通过增加隐空间来控制素描画的分布,并且演示了在隐向量上增加先验分布对于产生清楚的矢量图的重要性。
论文:https://arxiv.org/abs/1704.03477