利用语言模型帮助场景文本识别,提出了一种基于双向特征表示的双向完形填空网络语言模型(BCN),重点解决低质量图像的文本识别问题。
CVPR2021
论文地址:https://arxiv.org/abs/2103.06495
代码地址:https://github.com/FangShancheng/ABINet
1. 总述
语言知识对场景文本识别有很大的帮助。然而,如何在端到端的深度神经网络中有效地建模语言规则存在着挑战。
本文作者认为语言模型的有限能力来自:
- 1)隐式语言建模;
- 2)单向特征表示;
- 3)有噪声输入的语言模型。
相应地,本文提出了一种自主、双向、迭代的场景文本识别网络。
- 首先,在视觉模型和语言模型之间阻断梯度流,以实现语言的显式建模。
- 其次,提出了一种基于双向特征表示的双向完形填空网络(BCN)语言模型。
- 最后,提出了一种语言模型迭代修正的执行方式,有效地缓解了噪声输入的影响。
2. 网络结构
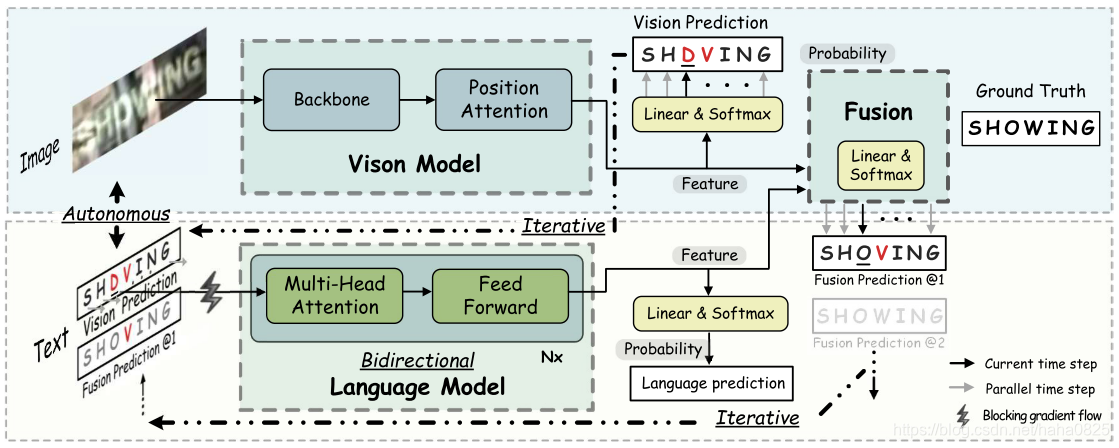
网络主要分为3部分:视觉模型,语言模型和融合部分。
- 首先输入图像到视觉模型,提取图像特征以及输出预测结果;
- 将视觉模型的预测结果送入语言模型来提取语言特征并预测结果;
- 将视觉模型的视觉特征和语言模型的语言特征进行融合来得到融合的预测结果;
- 融合的预测结果再送入语言模型,迭代地进行细化,以得到最终的预测结果。
2.1 视觉模型
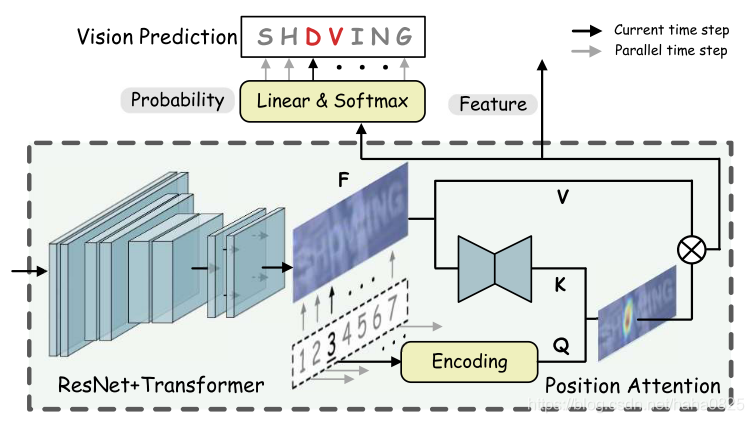
视觉模型由主干网和位置注意力模块组成。采用ResNet和Transformer units作为特征提取网络和序列建模网络。
位置注意力模块基于查询范式,将视觉特征并行转录为字符概率。
2.2 语言模型(BCN)

BCN是L层transformer decoder的一个变体。BCN的每一层是一系列的多头注意力和前馈网络,接着是residual connection 和 layer normalization,如图所示。不同于普通的Transformer,字符向量被输入到多头注意力模块而不是网络的第一层。此外,多头注意力模块中的注意力mask被设计成屏蔽该位置。通过以完形填空的方式指定注意力mask,可以使BCN能够优雅地学习到比单向表征更强大的双向表征。
噪声输入问题:如示例中,P(“O”)的期望条件是“SH-WING”。然而,由于环境的模糊性和封闭性,视觉模块得到的实际情况是“SH-VING”,其中“V”变成了噪声,影响了预测的可信度。随着视觉模块中错误预测的增加,它对语言模型的正确预测造成了更大的困难。
为了解决噪声输入的问题,作者提出了迭代LM(语言模型)。LM重复执行M次,y的赋值不同。对于第一次迭代,yi=1是VM(视觉模型)的概率预测。对于随后的迭代,yi≥2是上一次迭代中来自融合模块的概率预测。通过这种方法,LM能够迭代地校正视觉预测。
2.3 融合模块
图像训练的视觉模型和文本训练的语言模型来自不同的模式。为了使视觉特征和语言特征保持一致,需要使用门控机制进行最终决策:
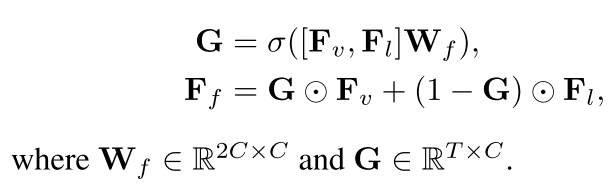
得到权重G来分配视觉特征和语言特征的权重。
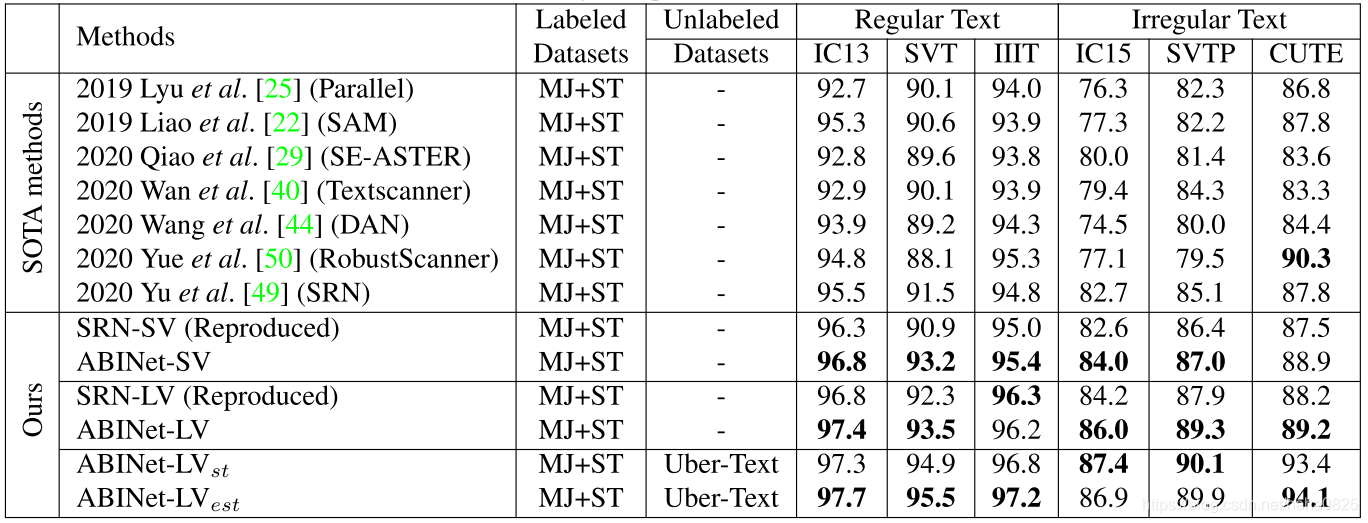
3. 实验
SOTA对比: