千辛万苦,终于在昨天把caffe编译的所有坑填完了,于是准备拿caffe自带的mnist案例来跑一下。
但要清楚,在caffe中是不带练习数据的,因此需要自己去下载。
不过在caffe根目录下的data文件夹里,作者已经为我们编写好了下载数据的脚本文件,我们只需要联网,运行这些脚本文件就行了。所以我们在命令行输入:
一、先在终端进入到caffe目录下
然后运行:
sudo sh ./data/mnist/get_mnist.sh输入命令之后,我们可以看到开始下载数据集:
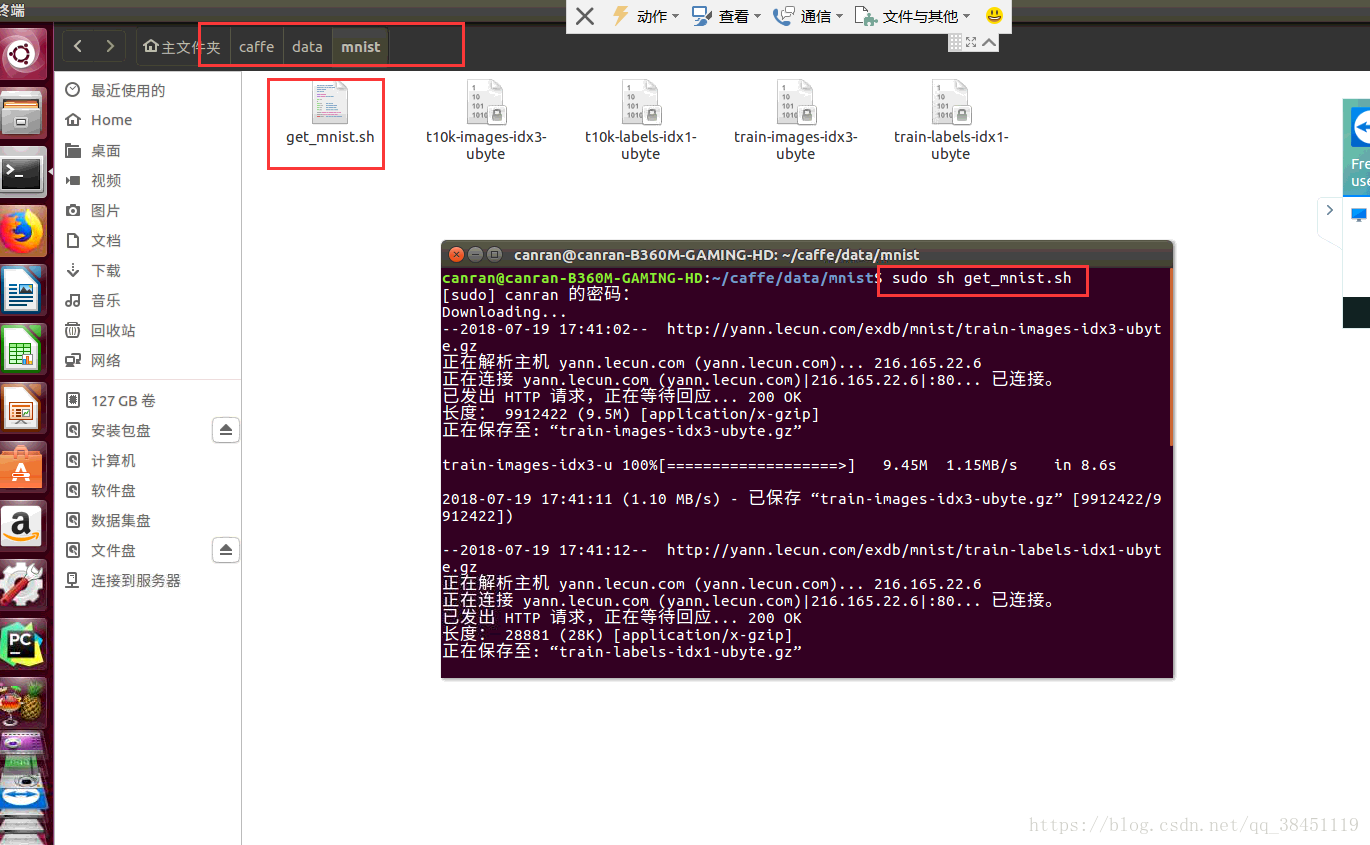
下载完成之后,如上图,wome我们可以在文件及的的 data/mnist/ 目录下可以看到MNIST的四个文件。
二、进行数据转换
下载好的这些数据caffe并不支持,因此不能在caffe中直接使用。
我们需要提前转换成LMDB数据类型,同样先进入到caffe目录下,然后输入:
sudo sh examples/mnist/create_mnist.sh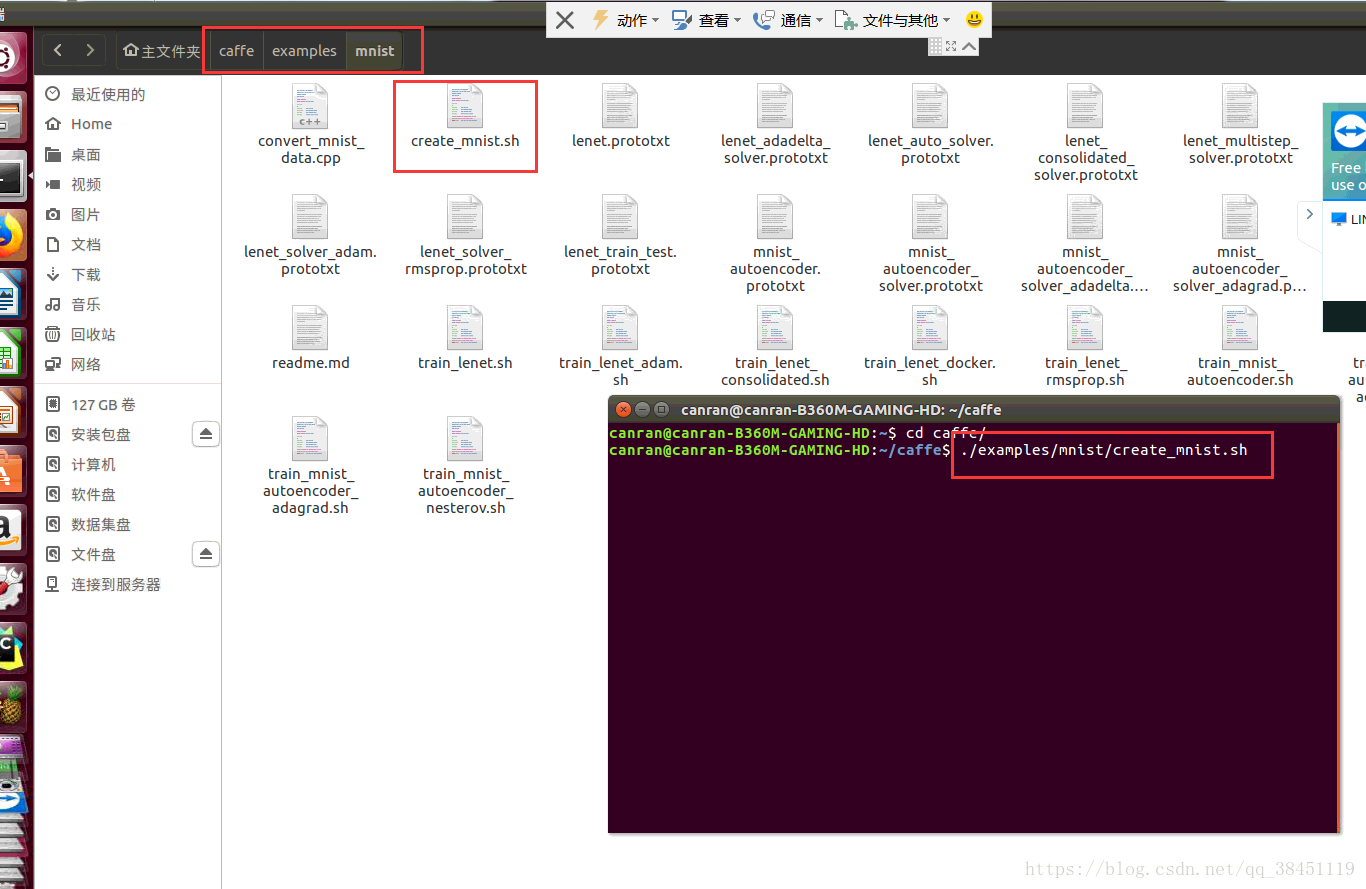
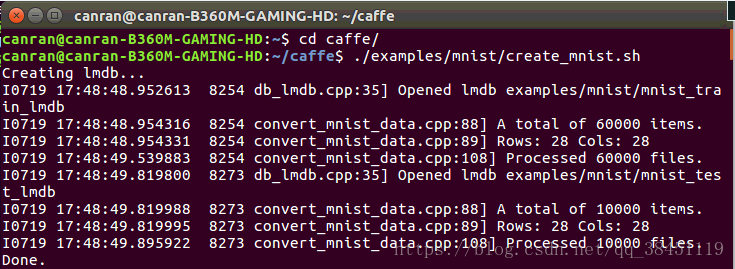
如果显示如上图,则转换完成。
三、修改配置文件
如果你有GPU且已经之前编译caffe时候已经设置了使用cudnn
这一步可以省略,如果没有,则需要修改solver配置文件。需要的配置文件有两个:
一个是lenet_solver.prototxt,另一个是train_lenet.prototxt.
首先进入到caffe目录下,在命令行下输入下面的指令打开net_solver_prototxt并进行修改:
sudo gedit examples/mnist/lenet_solver.prototxt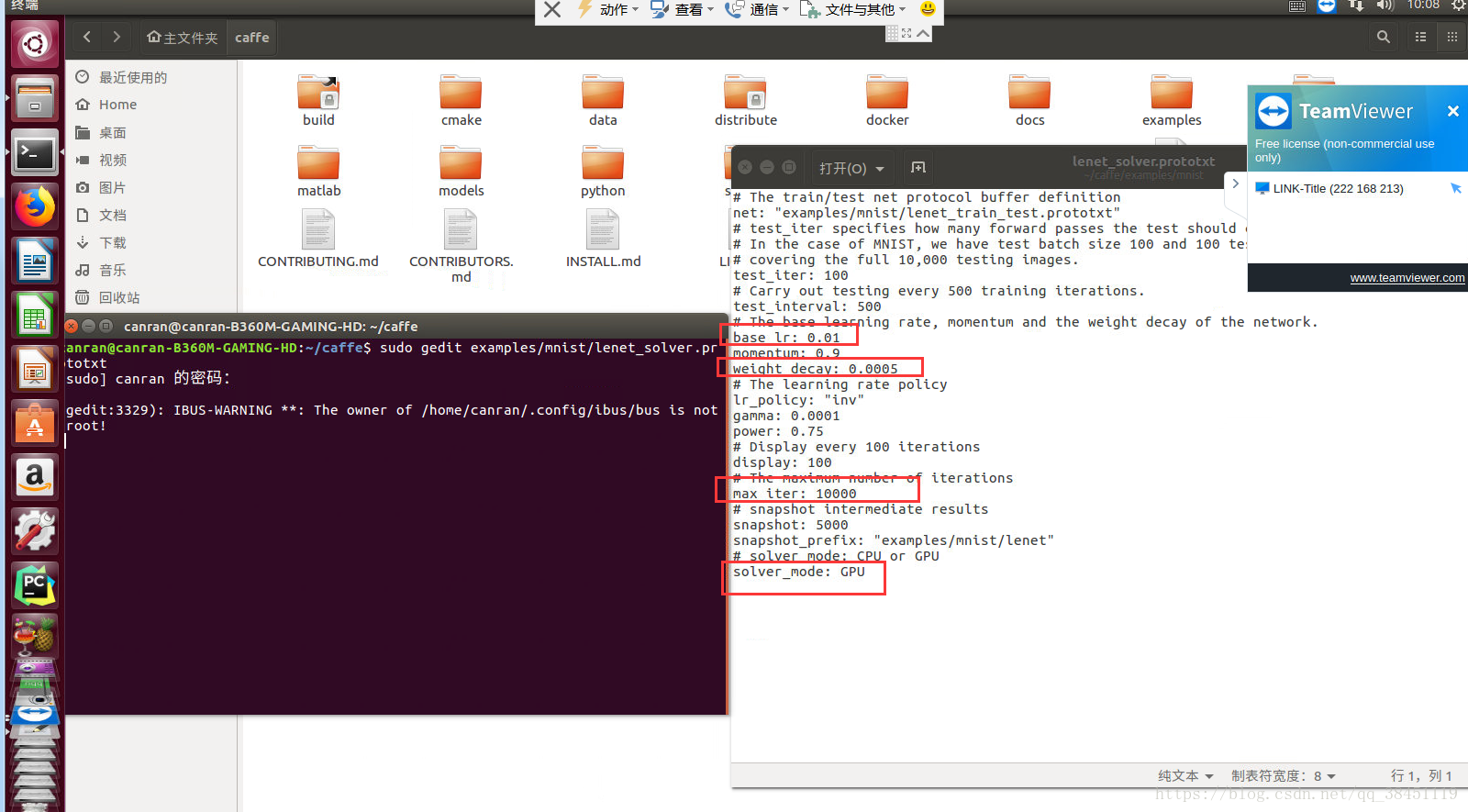
主要是改我框起来的这几项:
学习率
权重衰减
最大迭代次数
使用GPU还是CPU
四、训练
终于可以开始我们最激动的训练时刻了,使用LeNet网络。
同样,先进入到caffe目录下,在命令行输入:
sudo time sh examples/mnist/train_lenet.sh期间如果出现类似我这样的问题:
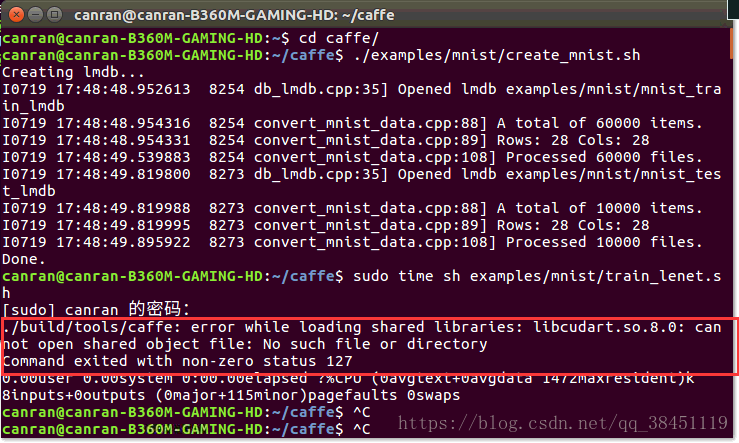
请参考我的另一篇博文:
error while loading shared libraries: libcudart.so.8.0: cannot open shared object file: can not open
解决该问题后,应该就可以跑通了。
如下图:
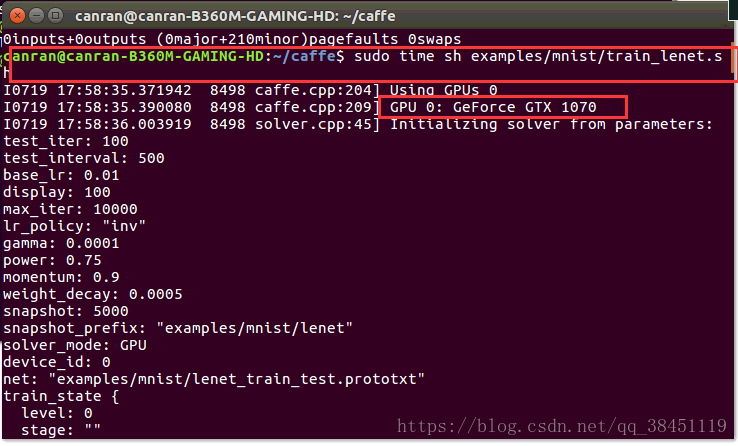
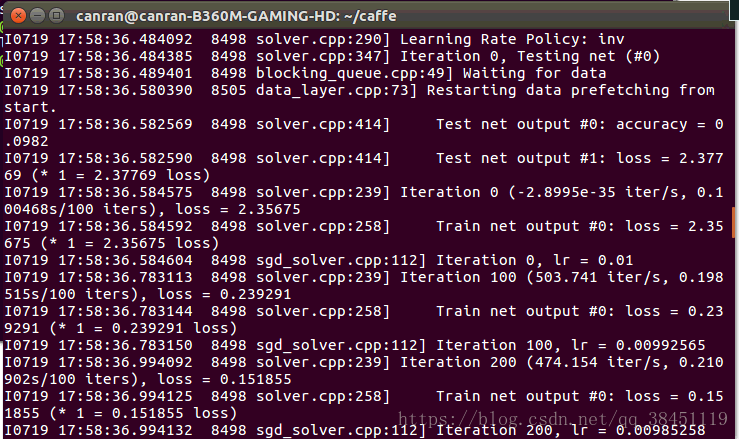
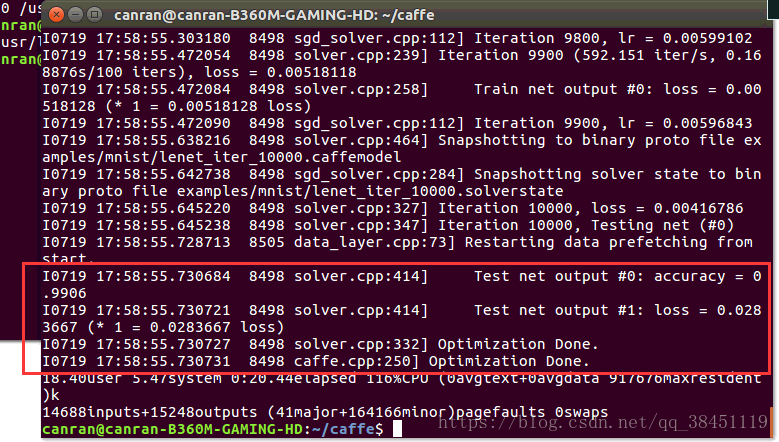
训练完成啦!!!
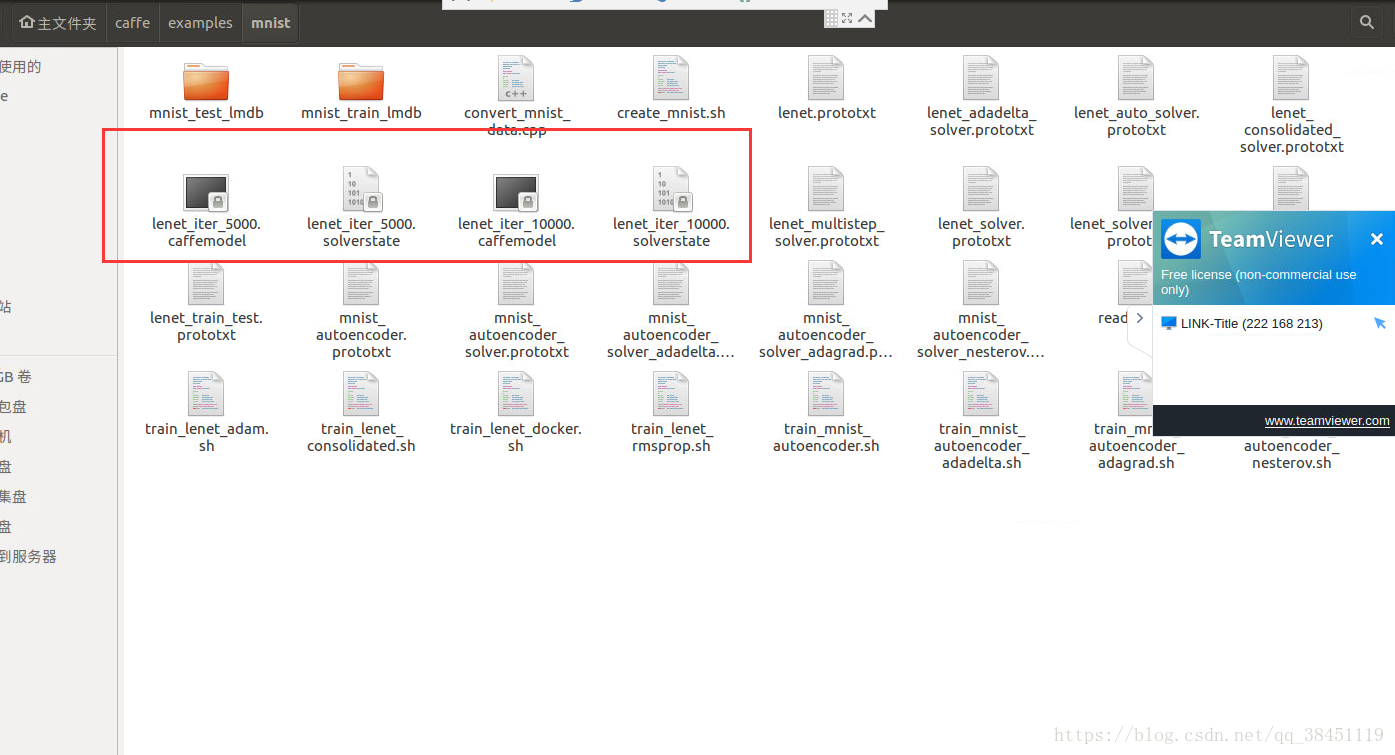
最后发现在目录:caffe/examples/mnist 下面会出现:.caffemodel的文件,这个就是我们训练出来的对应迭代次数5000、10000的训练数据!