搭好了环境,下面就该训练模型了呀!实践才是真理的唯一标准!大多数情况下,新接触caffe的小白们第一个训练的模型一定是Mnist数据集吧。这篇文章就以mnist数据集为例介绍下如何训练模型吧!(训练模型,想想就激动~)
先来简单的介绍一下mnist数据集,mnist数据集属于分类的数据集。里面包含了从0-9十个类别。mnist数据集中共包含70000张图片,其中60000张是训练集,10000张是测试集。训练集和测试集对于熟悉深度学习的人肯定不陌生吧!这是我们模型训练的基础。70000张图片大小是28x28x1。
说完了mnist数据集,那它哪里来呢?又要怎么用呢?还有和模型训练有啥关系呢?(问题三连,但是不怕)下面让我来一一解答!
1. mnist数据集的下载
因为mnist数据集的训练属于caffe中最最基础的训练模型。caffe中自带了下载mnist数据集的文件:get_mnist.sh(该文件在caffe目录下,具体的位置可以自己去翻翻,顺便加深下对文件的了解)
进入caffe目录下,执行:
sudo sh get_mnist.sh 等待一段时间,就会发现train-images-idx3-ubyte、train-labels-idx1-ubyte、t10k-images-idx3-ubyte、t10k-labels-idx1-ubyte这四个文件出现在了我们的文件夹中。分别对应的训练集、训练集标签、测试集、测试集标签。
至此为止,mnist数据集就下载完成了!
2. mnist数据集的格式转化
在caffe中所有模型输入的图片数据不能是.jpg/.png/.bmp。而必须是lmdb格式。所以需要将刚才下好的数据集进行转化。转化的文件也有了:create_mnist.sh(同样也是自带的)
进入caffe目录,执行:
sudo sh create_mnist.sh 执行过后,需要等待一段时间。在caffe/examples/minst中会出现名为minst_test_lmdb和minst_train_lmdb两个文件夹。分别存放测试集和训练集的lmdb格式的数据。
现在,有关数据已经全部准备好了,下面该到训练模型了!
3. 训练模型
在caffe中,训练模型需要准备两个文件:一个是模型文件,简称为model.prototxt(prototxt是caffe下文本文件的后缀)。另一个是参数文件,简称为solver.prototxt。solver文件格式都差不多,但model文件大小取决于使用的模型(lenet网络中7层,但完整版的resnet却有100多层)。
对于两个文件,还是要着重介绍下(里面有的参数需要修改!)
solver文件全文如下(所有模型solver文件格式都一样,所以务必弄清每一个超参数的含义):
# net里面写模型的位置,在一个文件夹下可写相对路径
net:"examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
#测试集迭代100次:共10000/100=100,每次100个样本
test_iter: 100
# Carry out testing every 500 training iterations.
#每训练500次迭代,进行一次测试
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
#冲量,在SGD优化器中可以达到避免震荡的作用
momentum: 0.9
#权值衰弱常数,防止过拟合。在训练期间,将正则化项添加到网络的损失中以计算后向梯度。 weight_decay值确定该正则化项在梯度计算中的优势
weight_decay: 0.0005
# The learning rate policy
#学习率计算的方法,共有七种,根据base_lr和learning_rate_lr计算。inv计算公式是 base_lr * (1 + gamma * iter) ^ (- power)所以之后两个参数是gamma和power
lr_policy: "inv"
gamma: 0.0001
power: 0.75
#每100次迭代在终端中显示一次xxx
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
#snapshot用来保存模型,每经过指定次数会形成一个模型,以后再训练时可在其基础上训练
snapshot: 5000
#这是caffemodel保存的位置,记得一定要写
snapshot_prefix:"examples/mnist/lenet"
# solver mode: CPU or GPU,自己的CPU/GPU选个适合自己的
solver_mode: CPU
在mnist数据集模型训练中使用的是Lenet模型,下面简单的介绍一下lenet模型(其实我也不是特别懂~)
Lenet共七层结构(输出层不算的)
分别是:输入层→卷积层→池化层→卷积层→池化层→全连接层->全连接层->输出层。不多说,上图:
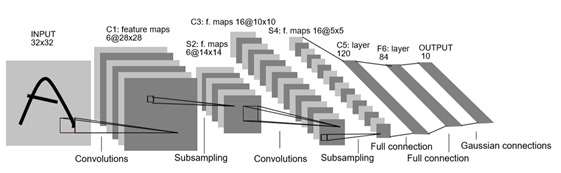
总的来说,lenet属于比较简单的深度神经网络.但因为mnist数据集比较小,所有使用Lenet已经可以达到较高精度。后面博客会介绍cifar10,那个数据集更复杂。也就会使用更复杂的模型。
模型文件叫做lenet_train_test.prototx。下面是部分内容:
layer {
name: "mnist"
type: "Data"
top:"data"
top:"label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size:64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top:"data"
top:"label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}
这是数据层(Layer),对于layer的知识属于caffe的基本知识,可以去找相关书籍了解。本文不在此赘述。这个需要改动两个地方:是两个Layer的source的文件来源,要改成之前生成的lmdb文件的位置。注意对应好测试集和训练集!
文件已经准备好了,下面要正式开始模型的训练啦。训练的脚本已经准备好了,就是train_lenet.sh(可以自己去找找位置,应该mnist文件夹下面)进入指定文件夹,终端输入:
sudo sh train_lenet.sh 就可以正式进入训练了,训练之后的数据会存在caffe/examples/minst/lenet_iter_5000.caffemodel
caffe/examples/minst/lenet_iter_10000.caffemodel。两个文件中分别是迭代5000次和10000次形成的caffe模型
如果是CPU版本,训练时间在10多分钟。GPU版本不到一分钟就搞定了(由此可见,没有GPU深度学习真的是难玩,后面更恐怖!)
4.模型测试
之前完成的只是数据集的训练,还要讲数据集进行测试,测试指令是:
./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel注意下,在caffe安装的过程中已经将caffe目录下所有文件都进行编译。形成了build文件,如果不行的话记得在caffe目录下
make cleanm
make all -j4 对测试命令进行操作前面要加上sudo,否则会出现以下错误:
F0510 07:23:36.745424 5125 db_lmdb.hpp:15] Check failed: mdb_status
== 0 (13 vs. 0) Permission denied
*** Check failure stack trace: ***
@ 0x7f4fe1ca65cd google::LogMessage::Fail()
@ 0x7f4fe1ca8433 google::LogMessage::SendToLog()
@ 0x7f4fe1ca615b google::LogMessage::Flush()
@ 0x7f4fe1ca8e1e google::LogMessageFatal::~LogMessageFatal()
@ 0x7f4fe20862f8 caffe::db::LMDB::Open()
@ 0x7f4fe20c5e2f caffe::DataLayer<>::DataLayer()
@ 0x7f4fe20c5fc2 caffe::Creator_DataLayer<>()
@ 0x7f4fe2046160 caffe::Net<>::Init()
@ 0x7f4fe20493e0 caffe::Net<>::Net()
@ 0x408ca4 test()
@ 0x406fa0 main
@ 0x7f4fe0c16830 __libc_start_main
@ 0x4077c9 _start
@ (nil) (unknown)
已放弃 (核心已转储)
-----------------------------------分割线-------------------------
测试时间较训练时间较短,只有几秒,运行一次迭代,accuracy = 0.9868,loss = 0.042179
看到精度是不是很激动!但这只是模型的建立,我们真正想要的是测试自己拿来的随便一张图片。但这个过程需要对图片进行二值化,还需要写deploy文件。后面再慢慢说吧!现在享受喜悦吧~
附加内容:
1.minst数据集各个文件功能讲解,可参考这位博主的博客:https://blog.csdn.net/bhniunan/article/details/104357291link
2.在solver文件中的超参数由自己选择的优化器决定,不同优化器需要不同的参数。另外lr_policy对于不同模型也是不同的。 lenet_solver_adam/lenet_solver_rmsprop分别代表不同的优化器。(特点是种类在solver的后面)
优化方法如图:

minst_autoencoder.prototxt中autoencoder的作用是用于降维,有点类似PCA(主成分分析)。选取重要因素,减少噪声。具体计算方法可参考博客:https://blog.csdn.net/omnispace/article/details/78364582link
mnist_autoencoder_solver_adadelta和mnist_autoencoder_solver_adagrad和mnist_autoencoder_solver_nesterov是使用三种不同优化器的mnist_autoencoder_solver区别只在于种类(type)不一样和个别lr_policy不一样。和以上两种优化器正好不一样。(猜想使用方法不同)前两种是Lenet的后三种是minst的。
由于本篇文章作者水平有限。如有错误之处,请务必再下方评论区指正,谢谢!