理论部分
LeNet论文:Gradient-Based Learning Applied to Document Recognition
LeNet论文解读文章
LeNet网络解读视频
实践部分
利用caffe框架来实现LeNet
caffe安装教程
caffe教学视频
在实践开始之前,确保以源码方式编译并安装caffe,建议教学视频看到第19课时,以熟悉caffe的基本概念和操作。
caffe官方有lenet的教程,它用mnist数据库来训练网络,其在caffe/examples目录下的01-learning-lenet.ipynb
它需要用jupyter notebook打开
安装:sudo pip install jupyter notebook
然后在caffe/examples的目录下打开终端,执行jupyter notebook
如果打开jupyter时报错,需要更改系统的language support为英文
打开01-learning-lenet.ipynb 可以在此界面上直接运行代码,也可以自己编写.py文件运行。
可以在此界面上直接运行代码,也可以自己编写.py文件运行。
结合此教程,稍微改了下代码,写了注释,写成python脚本,分享出来,希望能够有所帮助。
代码讲解:(个人整理,非官方)[代码下载]
#!/usr/bin/env python
#coding: utf-8
导入模块:
import os
import sys
import caffe
from pylab import * ###pylab 是用来绘制二维,三维数据的工具模块###
from caffe import layers as L,params as P ###layers里面包含了Caffe所有内置的层(比如卷积,ReLU等) ;params则包含了各种枚举值###
一些初始化工作:
caffe_root = '/home/tools/caffe' ###指定caffe的根目录###
sys.path.insert(0,caffe_root + 'python') ###添加搜索路径###
os.chdir(caffe_root) ###指定当前工作目录为caffe根目录###
!data/mnist/get_mnist.sh ###运行脚本,下载解压mnist数据集###
!examples/mnist/create_mnist.sh ###运行脚本,利用mnist数据集生成lmdb格式的数据###
os.chdir('examples') ###指定当前工作目录为caffe/examples,因为.prototxt文件保存在该目录下###
定义LeNet网络(重点):
def lenet(lmdb,batch_size): ###入口为lmdb文件和batch_size###
n = caffe.NetSpec() ###定义Caffe的一个Net,NetSpec是包含Tops(可以直接赋值作为属性)的集合###
###输入层:从数据源文件读取data和label###
n.data,n.label = L.Data(batch_size = batch_size ###批大小###
,backend=P.Data.LMDB ###选择LMDB数据库格式###
,source=lmdb ###源文件###
,transform_param=dict(scale=1./255) ###像素归一化的scale###
,ntop=2 ###输出的blobs个数,一个是data,一个是label###
)
###①卷积层###
n.conv1 = L.Convolution(n.data
,kernel_size=5 ###卷积核大小###
,stride=1 ###步长默认是1,不写也可以###
,num_output=20 ###卷积层输出通道数###
,weight_filler=dict(type='xavier') ###xavier是一种很有效的神经网络初始化方法###
###xavier的思想:每一层输出的方差应该尽量相等###
)
###②池化层###
n.pool1 = L.Pooling(n.conv1, kernel_size=2, stride=2, pool=P.Pooling.MAX)###用maxpooling代替论文中的subsampling
###③卷积层###
n.conv2 = L.Convolution(n.pool1, kernel_size=5, stride=1, num_output=50, weight_filler=dict(type='xavier'))
###④池化层###
n.pool2 = L.Pooling(n.conv2, kernel_size=2, stride=2, pool=P.Pooling.MAX)
###⑤全连接层###
n.fc1 = L.InnerProduct(n.pool2, num_output=500, weight_filler=dict(type='xavier'))
###激活函数###
n.relu1 = L.ReLU(n.fc1,in_place=True) ###in_place=True:不创建新的对象,直接对原始对象进行修改
###in_place=False:对数据进行修改,创建并返回新的对象承载其修改结果
###⑥全连接层(输出层)###
n.score = L.InnerProduct(n.relu1, num_output=10, weight_filler=dict(type='xavier'))
###计算loss###
n.loss = L.SoftmaxWithLoss(n.score,n.label)
return n.to_proto() ###调用 NetSpec().to_proto 创建包含所有层(layers)的网络参数###
这里的LeNet结构跟论文中的不是完全一样的。比如用MaxPooling代替论文中复杂的Subsampling,舍去了Guassian connection,使用了ReLU,网络的尺寸也有所改变。这些变动可以看做LeNet的优化。
将生成的网络写入.prototxt文件:
with open('mnist/lenet_auto_train.prototxt','w') as f: ###打开文件###
f.write(str(lenet('mnist/mnist_train_lmdb',64))) ###设置训练网络批大小为64###
with open('mnist/lenet_auto_test.prototxt', 'w') as f:
f.write(str(lenet('mnist/mnist_test_lmdb', 100))) ###设置测试网络批大小为100###
可以打开caffe/examples/mnist/目录下的lenet_auto_train.prototxt和lenet_auto_test.prototxt来查看写入的内容:
这里利用了python接口caffe.NetSpec()来生成prototxt文件,而不需要我们自己去编写prototxt文件

训练初始化:
caffe.set_device(0) ###选择哪一块显卡,单显卡只能为0###
caffe.set_mode_gpu() ###使用caffe的GPU模式###
solver = None ###先把Solver清空###
solver = caffe.SGDSolver('mnist/lenet_auto_solver.prototxt') ###选择随机梯度下降方法(SGD),并读取配置文件###
###这里的prototxt文件是需要提前准备好的,里面写有学习率,动量,衰减速率等参数###
###训练相关参数###
niter = 200 ###训练迭代次数###
test_interval = 25 ###多少次训练测试一次###
###初始化数组###
train_loss = zeros(niter) ###记录loss,画曲线图时用到###
test_acc = zeros(int(np.ceil(niter / test_interval ))) ###记录accuracy,画曲线图时用到###
###numpy.ceil():向上取整###
output = zeros((niter,8,10)) ###输出层的结果,8代表取8个结果(100批大小有100个结果),10是输出层层单元个数###
开始训练:
for it in range(niter):
solver.step(1) ###迭代一次###
train_loss[it] = solver.net.blobs['loss'].data
solver.test_nets[0].forward(start='conv1') ###test net前向传播时从conv1开始,这样的话,data层这不用传用新的数据了###
#?# 我的理解是测试网络与训练网络共享输入数据层,但它们批大小是不同的,怎么共享数据层?#?#
#?# 如果你知道答案的话,欢迎评论区回答 #?#
output[it] = solver.test_nets[0].blobs['score'].data[:8] ###记录输出层的前8个结果###
###测试准确率###
if it % test_interval == 0:
print 'Iteration', it, 'testing...'
correct = 0
for test_it in range(100): ###测试100次###
solver.test_nets[0].forward() ###测试网络前向传播,这里是100个样本(前面设置的测试网络批大小)###
correct += sum(solver.test_nets[0].blobs['score'].data.argmax(1) == solver.test_nets[0].blobs['label'].data) ###记录测试正确的次数###
test_acc[it // test_interval] = correct / 1e4 ###计算准确率###
### // 表示整除###
###1e4=10000=batch_size * test次数###
画出train loss 和 test accuracy的曲线图:
_, ax1 = subplots()
ax2 = ax1.twinx() ###ax2与ax1共用一个x轴###
ax1.plot(arange(niter), train_loss) ###绘制train_loss曲线###
###numpy.arange() 产生等差数列,用作横坐标###
ax2.plot(test_interval * arange(len(test_acc)),test_acc, 'r')###绘制test_acc曲线###
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
ax2.set_ylabel('test accuracy')
ax2.set_title('Test Accuracy: {:.2f}'.format(test_acc[-1])) ###{:.2f}类似C语言中的%.2f,format()里面是要显示的数据###
###test_acc[-1]表示数组中下标最大的一个###
plt.show()

如果只是训练和测试网络,程序到此为止。
—————————————————————————————————————————————————————
caffe的LeNet教程中还有些其他东西
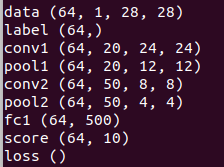
查看每一层的blobs尺寸:
for k,v in solver.net.blobs.items(): ###这里其实是遍历字典的操作,k(key),v(value)###
print k,v.data.shape ###打印字典中的值和对应data.shape###
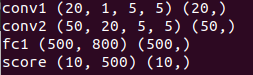
查看每一层的params尺寸:
for k, v in solver.net.params.items():
print k,v[0].data.shape,v[1].data.shape ###v[0]是权重,v[1]是偏置###
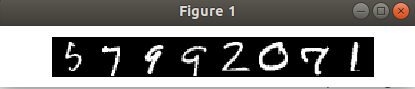
查看8个输入数据和对应标签:
imshow(solver.net.blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray')
axis('off')
plt.show()
print 'train labels:', solver.net.blobs['label'].data[:8]

画出迭代一次后第一层卷积层权重参数的梯度:
solver.step(1)
imshow(solver.net.params['conv1'][0].diff[:, 0].reshape(4, 5, 5, 5).transpose(0, 2, 1, 3).reshape(4*5, 5*5), cmap='gray')
axis('off')
plt.show()

显示一个的测试样本图片和其分类效果:
figure(figsize=(2, 2)) ###figsize:指定figure的宽和高,单位为英寸###
imshow(solver.test_nets[0].blobs['data'].data[0,0], cmap='gray')
figure(figsize=(20,2))
imshow(exp(output[:niter,0].T) / exp(output[:niter,0].T).sum(0), interpolation='nearest', cmap='gray') ###用输出层的softmax作分类结果###
#imshow(output[:niter,0].T, interpolation='nearest', cmap='gray') ###直接将输出层的值作为分类结果###
xlabel('iteration')
ylabel('label')
plt.show()
 右边的图显示的是迭代过程中这张图片的分类效果,显示颜色越白表示分类成该label值的概率越大。
右边的图显示的是迭代过程中这张图片的分类效果,显示颜色越白表示分类成该label值的概率越大。