数学解释
在用普通最小二乘法来求解线性回归的时候, 如果A不满秩, 则二乘法存在多个解.
这个时候就需要通过添加一个正则项来使得解唯一.
岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于OLS。
本质是在自变量信息矩阵的主对角线元素上人为地加入一个非负因子。即:
Ridge岭回归通过对回归系数增加惩罚项来解决普通最小二乘法的一些问题.岭回归系数通过最小化带惩罚项的残差平方和
求解过程
用上式对
求导, 并令导数=0
最小二乘法中 , 而岭回归则是 , 其中, 是控制模型复杂度的因子(可看作收缩率的大小), 越大,收缩率越大, 那么系数对于共线性的鲁棒性更强
sklearn中的岭回归
Ridge类实现基本的岭回归
sklearn.linear_model中的Ridge类实现了岭回归。
如果X是一个 size 为(n,p) 的矩阵,设n≥p,则该方法的复杂度为 (该方法和普通最小二乘法的复杂度是相同的)
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None)
model.fit ([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
print(model.coef_)
print(model.intercept_)运行结果:
[0.27142857 0.27142857]
0.18571428571428572根据上面的代码可以看出,Ridge类有多个参数:
| 参数 | 解释 | 默认值 | 说明 |
|---|---|---|---|
| alpha | 岭回归的超参数,用来控制模型的复杂度 | 1.0 | |
| fit_intercept | 是否计算截距项 | False | |
| normalize | 是否先给X做归一化处理 | False | |
| copy_X | 是否制作原始数据X的副本 | False | 若为True,会覆盖原始数据 |
| max_iter | 求解模型的迭代过程的最大迭代次数 | 1000 | 到达迭代次数则停止迭代 |
| tol | 模型结果的精度 | 0.001 | 当前后两次结果的误差在tol以内则停止迭代 |
| solver | 求解模型的方法 | auto | {‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’} |
| random_state | 随机种子 | None | 用来shuffle数据 |
这里简要介绍一下Ridge中的各个solver
auto根据数据类型自动选择求解器。
查看sklearn的auto相关源代码:
has_sw = sample_weight is not None
if solver == 'auto':
# cholesky if it's a dense array and cg in any other case
if not sparse.issparse(X) or has_sw:
solver = 'cholesky'
else:
solver = 'sparse_cg' 可以看出,当矩阵X时稀疏或者样本权重不为空时,solver为cholesky, 否则为sparse_cg
svd使用X的奇异值分解来计算岭回归系数。奇异矩阵的稳定性比cholesky好。cholesky使用标准的scipy.linalg.solve函数获得封闭形式的解决方案。sparse_cg使用scipy.sparse.linalg.cg中的共轭梯度求解器作为迭代算法,这个求解器
比cholesky更适合大规模数据lsqr使用正则化最小二乘scipy.sparse.linalg.lsqr。它是最快的,但在旧的scipy版本可能无法使用sag使用随机平均梯度下降saga是改进了的sag,saga是无偏的。当n_samples和n_features都很大时这两种方法通常比其他解算器更快。注意’sag’和’saga’快速收敛只能保证features大致相同的比例- 所有最后五个求解器都支持密集和稀疏数据。然而,只有
sag和saga在fit_intercept=True时支持稀疏输入。
RidgeCV类实现 岭回归+交叉检验
sklearn.linear_model里的RidgeCV类实现带交叉检验的岭回归,这个方法和手动调用sklearn里的GridSearchCV一样,唯一的区别在于它默认为 Generalized Cross-Validation(广义交叉验证 GCV),这是一种有效的留一验证方法(LOO-CV)
from sklearn.linear_model import RidgeCV
model = RidgeCV(alphas=(0.1, 1.0, 10.0),
fit_intercept=True,
scoring=None,
cv=None, gcv_mode=None,
store_cv_values=False)
model.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
print(model.alpha_) # 最佳alpha运行结果:
0.1下面详细介绍一下RidgeCV类的各个参数:
| 参数 | 解释 | 默认值 | 说明 |
|---|---|---|---|
| alphas | 正则项参数组成的numpy数组 | 0.1, 1.0, 10.0 | |
| fit_intercept | 是否计算截距项 | True | |
| scoring | 模型指标 | None | string, callable或None,详细信息参考模型选择 |
| cv | 交叉验证分离数据策略 | None | |
| gcv_mode | 交叉验证时的计算策略 | None | {None, ‘auto’, ‘svd’, eigen’} |
| store_cv_values | 是否存储 | False |
举个栗子——绘制岭迹图
绘制岭迹图(横轴为 , 纵轴为各个系数coef的值)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
# X 是一个10x10的矩阵
X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
# 计算参数路径(岭迹)
n_alphas = 200
alphas = np.logspace(-10, -2, n_alphas)
coefs = []
for a in alphas:
ridge = Ridge(alpha=a, fit_intercept=False)
ridge.fit(X, y)
coefs.append(ridge.coef_)
# 绘制岭迹图
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
ax.set_xlim(ax.get_xlim()[::-1]) # 反转x轴
plt.xlabel('alpha')
plt.ylabel('weights')
plt.title('岭迹图')
plt.axis('tight')
plt.show()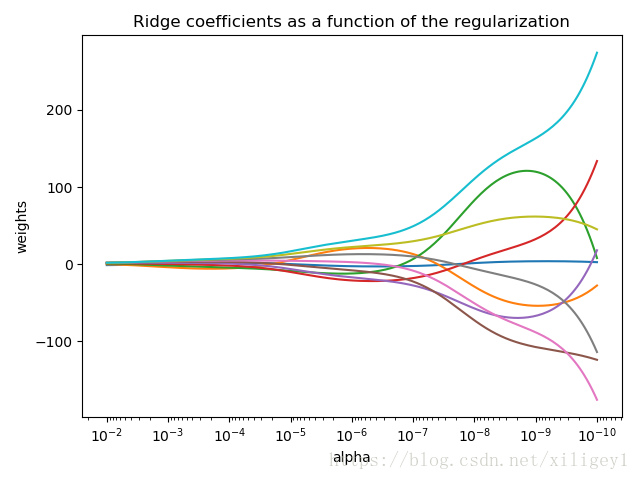
根据岭迹图选取 、筛选特征

岭迹图选取合适的
:
随着
的增大, 岭迹趋于平稳的时候,
取这个点比较合适
根据上图, 可以看出当k(
)达到0.2的时候, 岭迹基本稳定了, 所以选0.2较合理
岭迹图选取合适的变量:
1. 随着
的增加而迅速逼近于0的去掉
2. 基本稳定且值接近于0的去掉
3. 去掉变量后再做岭回归再筛选
根据上图
12, 13迅速趋于0, 去掉
4, 7, 10, 11, 15基本稳定且接近于0, 去掉