2深度卷积网络——实例探究
学习目标:通过本课程的学习之后,可以阅读计算机视觉方面的论文,学习别人以取得的比较好的CNN架构。
2.1为什么要进行实例探究
1.学习一门技术最好的办法是学习别人如何应用。
经典的网络:
- LeNet-5
- AlexNet
- VGG
新型网络:
- ResNet : 152层
- Inception
2.2经典网络
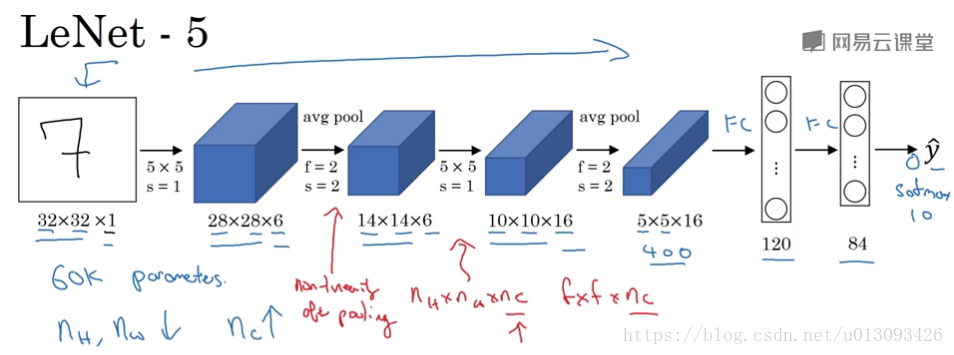
1.LeNet-5,6万个参数
2.AlexNet,6千万个参数
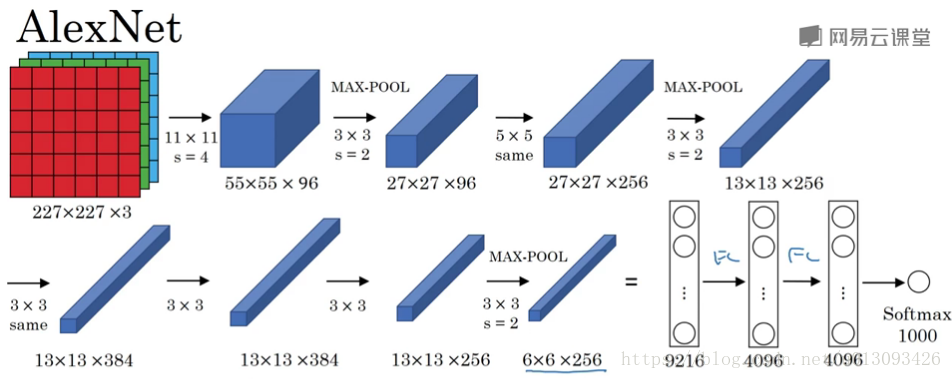
AlexNet的特点
- 与LeNet机构相似,但复杂很多,训练的参数达到6千万;
- 使用了Relu函数
- 多GPU处理,将各层数据分配到两个GPU进行处理;
- 增加了局部相应归一化层(local respond normalization,LRN) ,但算法起到的作用不大
3.VGG-16
这是一种只需要专注于构建卷积层的网络,CONV=3x3 filter, s=1, padding= same MAX-POOLING = 2x2, s=2.
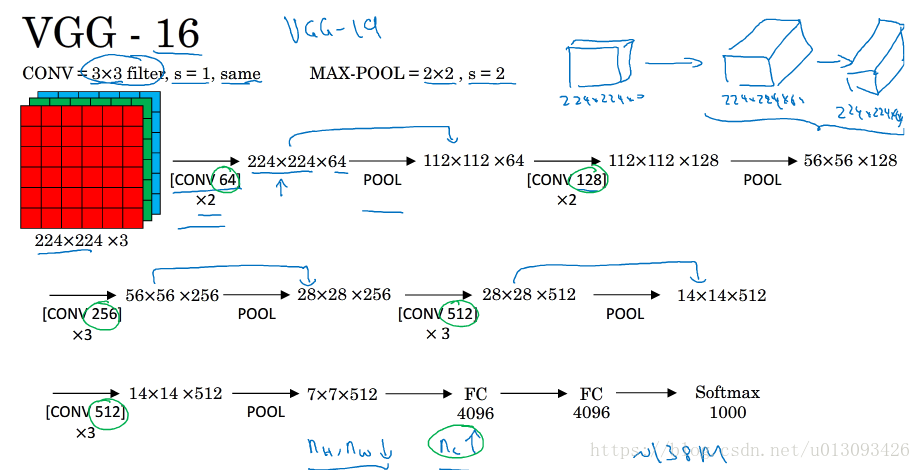
VGG的特点:
- 简化了神经网络结构,即机构很规整并不复杂(都是几个卷积层后跟一个可以缩小图像高度和宽度的池化层)
- 但是是一个非常深的结构,VGG-16包含16个卷积层/FC层,卷积层过滤器的个数存在一定的规律:64-128-256-512
- 1.38亿个参数,缺点之一
- 解释了图像大小和通道数量之间的某种关系
2.3残差网络:ResNet
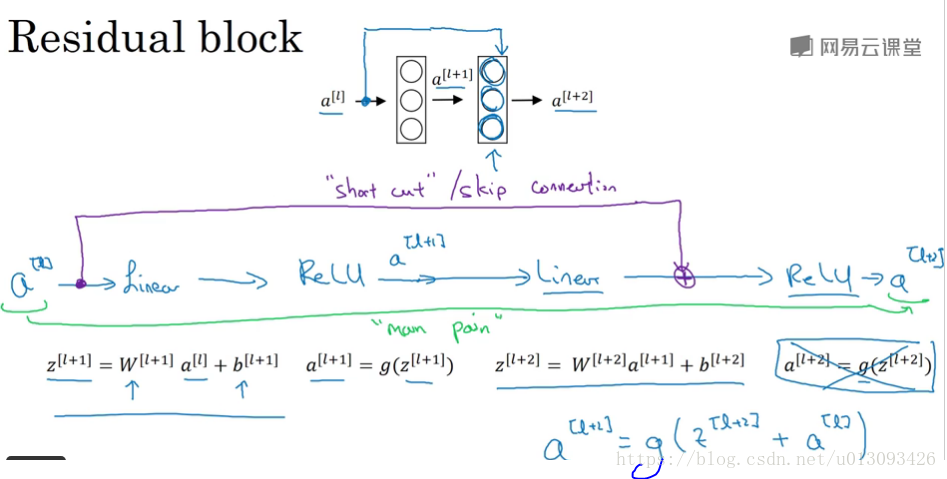
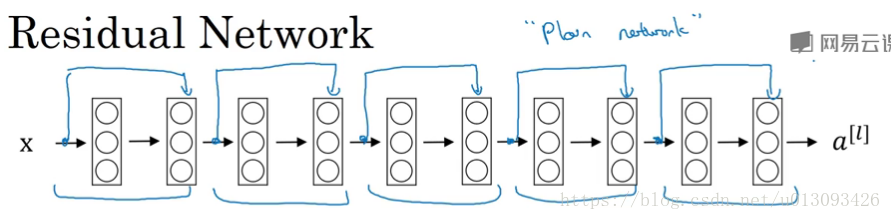
1.残差块(residual block),ResNet的基本组成模块,使用残差块可以训练更深层次的网络,其基本过程是跳过一层或基层网络层,比如将a[l]直接传递到a[l+2],则a[l+2] = g(Z[l+2] + a[l])在这个公式里可看出多了一个a[l]块,这个块就称为残差块。
2.残差网络(Residual Net)
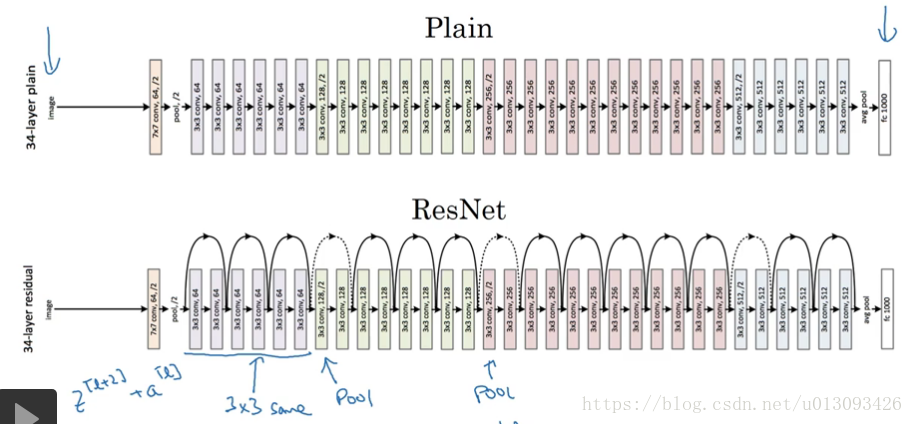
一个没有Residual block 的网络称为plain Network,如下所示:
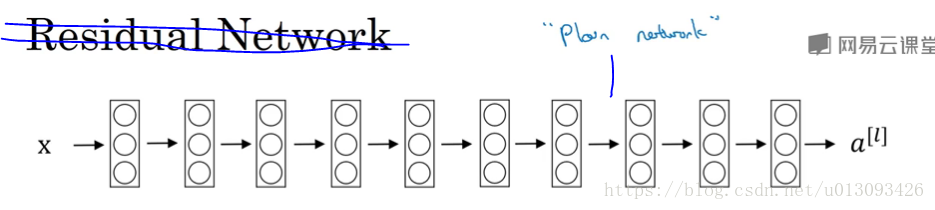
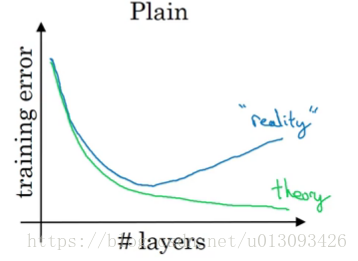
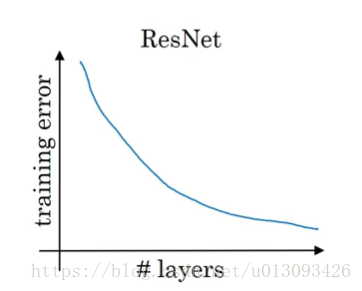
3.残差网络的优势:理论上来说网络的深度越深,优化的精度越高,但实际上用优化算法训练过程中随着层数的增加,模型的精度会触底反弹,如下图所示,正是由于残差块的加入才能克服这个缺点 ,即有助于消除梯度爆炸和梯度消失,又能保证良好的网络性能。
2.4ResNet为什么有用?
1.ResNet的特点
(1)ResNet中的残差块比普通网络虽然多了两层(不论是添加网络的中间还是末端),但效率并不逊色于普通神经网络,因为多出的两个学习恒等函数很简单,见下图分析。这个是保证了ResNet起作用的基础(因为你可以确定至少性能不受新增层的影响)
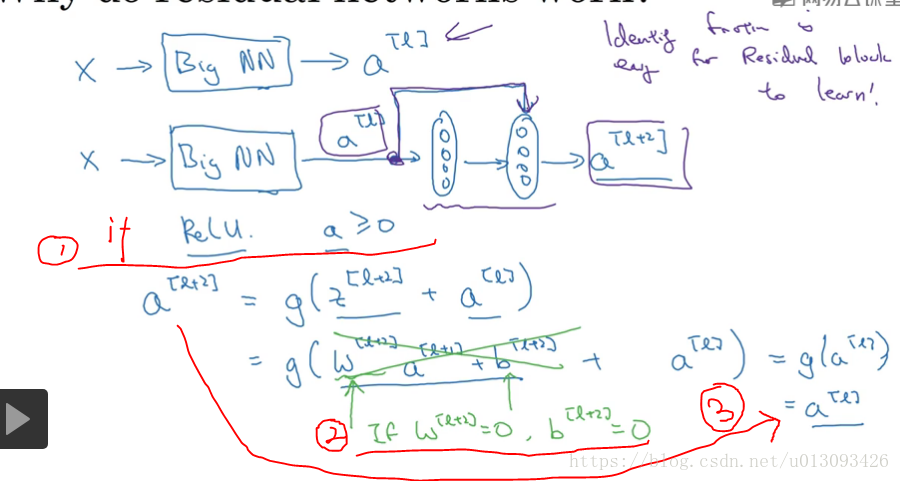
(2) 有助于效率的提升,因为新增的两层可能会学到更多的有效信息,而不含残差块的普通神经网络随着网络层数的增加就算是选择用来学习恒等函数的参数都很困难所以层数多了之后变现反而下降。
(3)Z[l+2]与a[l]的匹配问题,由于ResNet中有很多使用了SAME的卷积层因此大多数时Z[l+2]与a[l]就是相同维度的,如果维度不同,我们可以引入Ws权重使Z[l+2].shape = (Ws * a[l]).shape
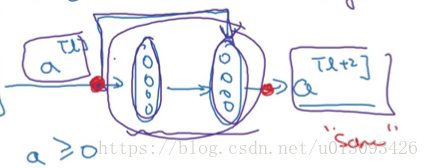
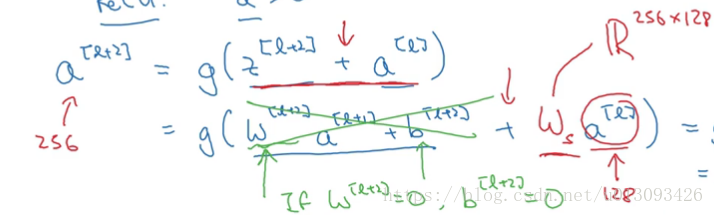
当然,我们不需要为Ws担心,它可以通过网络学习获得,可以把它想象成一个padding的过程,即使用0把a[l]padding成Z[l+2]。
2.ResNet与plainNet的整体对比
2.5网络中的网络及1x1卷积
1.1x1卷积有什么作用?
对于一维的矩阵而言1x1卷积只是倍数而已,但是如果是6x6x32的图片那么使用1x1卷积效果会非常好,如下图
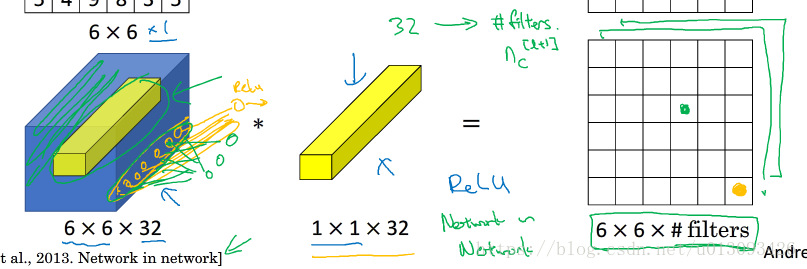
其主要作用是遍历6x6矩阵中的36个元素,然后将左侧32个数字和32个过滤器按照元素逐一乘积,接着应用Relu激活函数,这个过程看似意义不大,但是当我们想缩小输入的数据大小时该怎么办?当然池化作用可以缩小高和宽两个维度(n_H, n_W),然而缩小信道数量(n_C)该怎么处理呢?这时1x1卷积就可以发挥重要作用,如下图。

总结:1x1卷积主要作用是给神经网络增加了非线性函数,从而减少、增加或保持输入层的信道数量,这对构建Inception网络也很多帮助。
2.6 Inception网络简介
1.重要应用:可以帮助工程师确定filter的形式(f:1,3,or 5)和是否需要pooling。
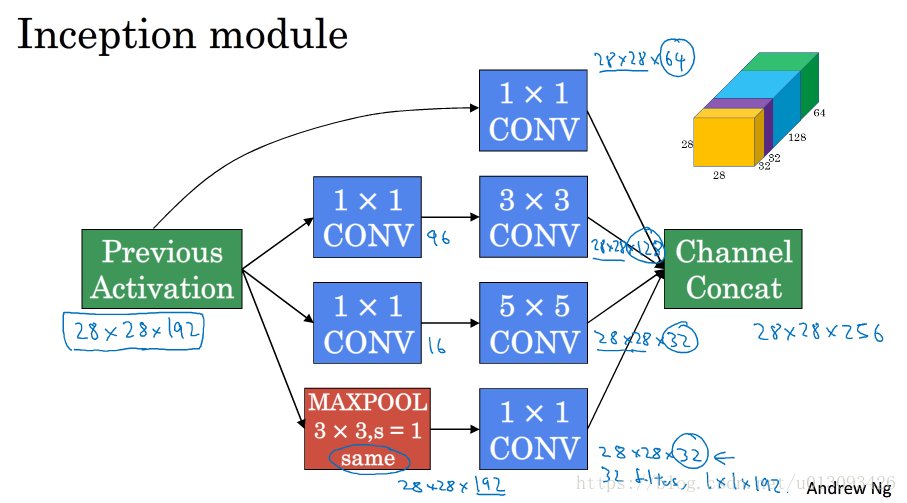
2.Inception模块
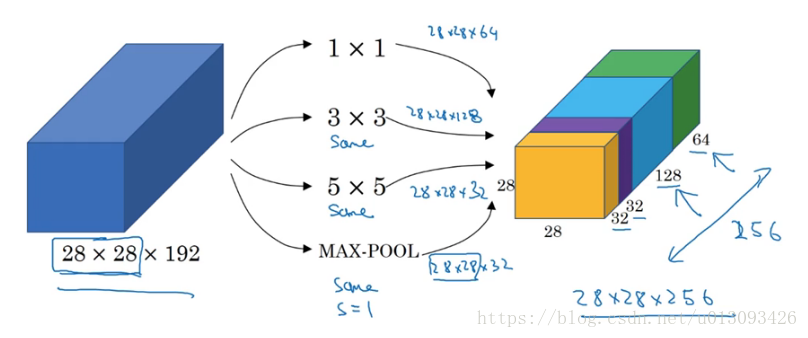
基本思想是不需要人为决定使用哪种过滤器或是否需要池化,而由网络自行确定这些参数, 我们需要做的是给网络传入这些参数的可能值(1x1,3x3,5x5,max-pool)然后把输出连接起来,让网络自己学习需要什么样的参数或哪些过滤器的组合。
3.Inception的计算代价问题
以5x5过滤器为例,
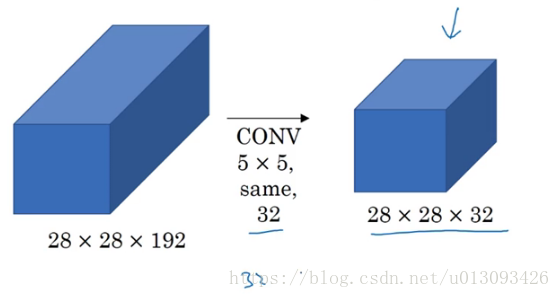
在这个过程中我们需要计算5x5x192(filter_size) x 28x28x32(output_size)这个数量级大致为1.2亿次运算,而解决这个问题的有效办法就是 1x1卷积。
4.使用1x1卷积的Inception网络
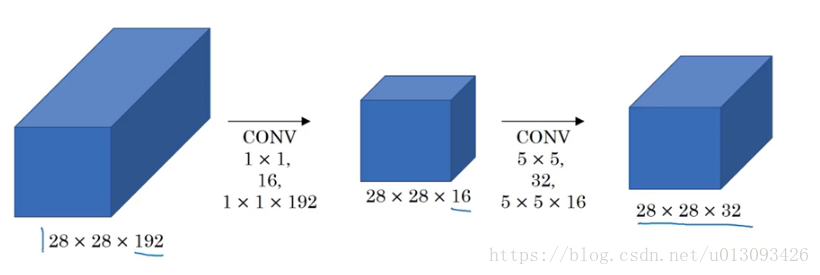
通过增加中间28x28x16这个层(bottleneck layer) ,此时计算量为1x1x192x28x28x16+5x5x16x28x28x32 = 1240万,比之前降低一个数量级。
2.7 Inception网络
1.Inception模块
2.Inception网络结构
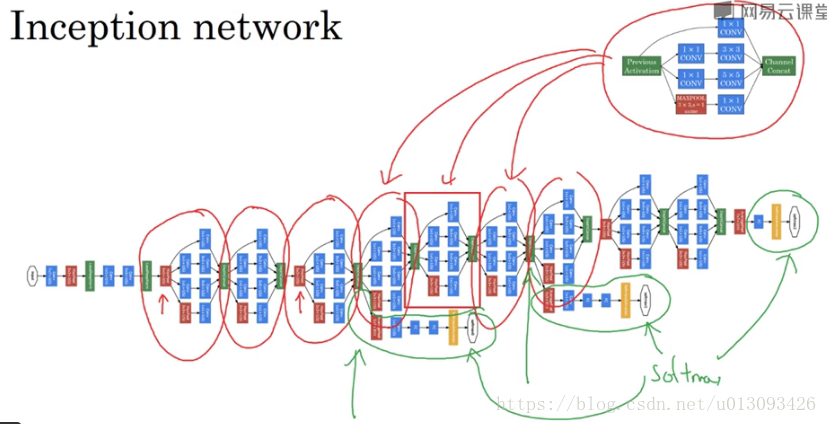
注意绿线框出的都是FC+softmax输出分类标签 ,这保证了即便是在隐藏单元和中间层也参与了特征计算,他们也能预测图片分类,它在Inception网络中起到了一种调节效果,并且可以防止网络发生过拟合。
2.8使用开源的实现方案(github)
1.达叔提示:在论文或文献中看到某种算法时,首先要在网上找下开源的代码去实现以下,这样会节省很多时间,所以多多的使用Github吧。有的开源项目会使用多个GPU训练大量数据,这样我们可以利用迁移学习来训练自己的模型可以节省很多时间。
2.9迁移学习
1.结构示意
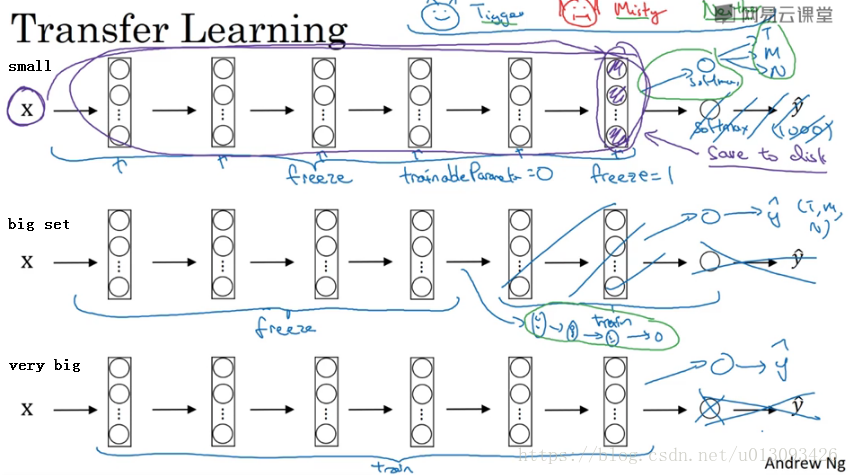
自己的数据样本越多,需要冻结的层数越少 。
2.10 数据增强
1.对于计算机视觉的应用而言,数据往往不够,需要使用数据扩充技术进行增加。
2.常见的增强方式:
(1)垂直镜像(mirroring)

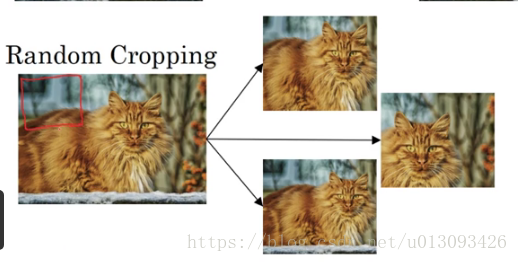
(2)随机裁剪(random cropping)
不常用的方法:
(3)旋转(rotation)
(4) 剪切(shearing)
(5)局部弯曲(local warping)
3.色彩转换(color shifting)
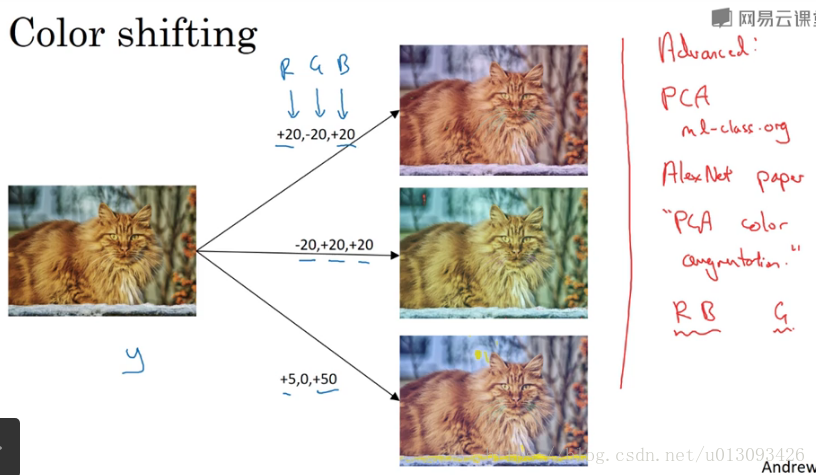
4.在使用数据增强时,通常使用单独的线程/进程或多线程/进程处理。
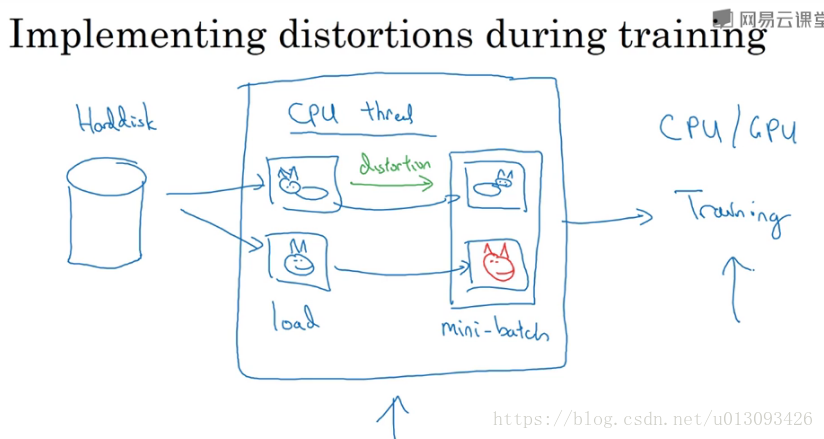
2.11计算机视觉现状
1.学习算法的两种知识来源
(1)带标签的数据
(2)手工工程特征/网络结构/其他组件
因此在缺少(1)的情况下就需要重点考虑(2),这也是正是计算机视觉领域发展出结构非常复杂的神经网络的原因,因为在缺少更多数据的情况下,为获得更好的表现,还是要依靠架构设计
2.数据量对工程算法选择的影响
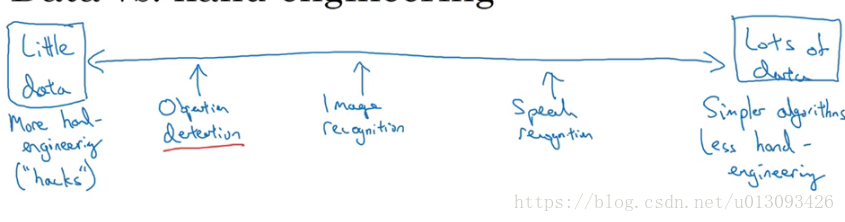
3.计算机视觉领域一直以来是出于少数据量的状况下,但近些年有数据增多的趋势,这导致了手工工程的急剧减少,但是手工工程仍不可或缺,这也是为什么计算机视觉的网络非常复杂的原因。
4.计算机视觉属于小数据系统,因此更好利用开源代码将是一个很多的选择,使用开源代码的优势
