卷积神经网络——目标检测
3.1目标定位
1.分类与定位
分类问题可以有助于定位问题的解决,当识别完图片类型之后我们可以让神经网络的输出增加几个单元,从而输出一个边界框(bounding box),具体而言就是多输出4个数字(b_x, b_y, b_h, b_w),在这种情况下,输出将包含:一个分类标签,四个位置值
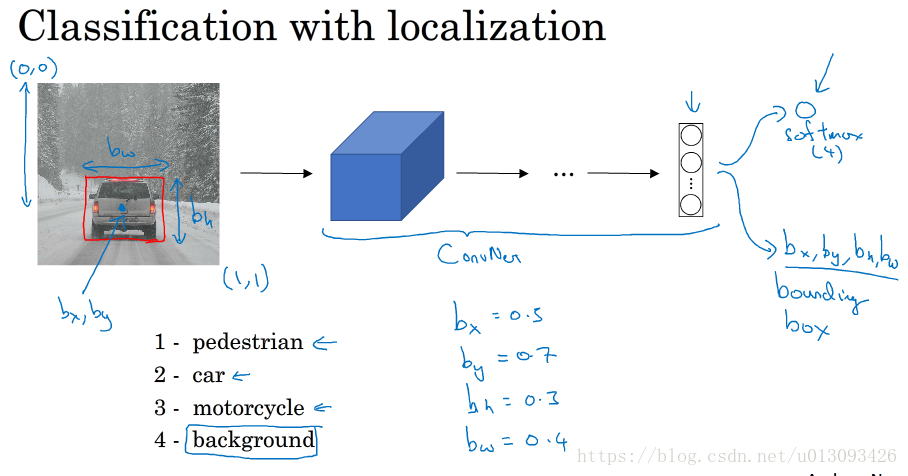
2.定义目标标签y
假设在分类任务中有4类:pedestrian(行人)、car(车辆)、motorcycle(机车),background(其他) ,这四类中如果输入图像不是前三类那么统统算作background,因此在标签y中需要设置一个参数P_c表征是否识别出物体,当P_c=1时,y=[P_c, b_x, b_y, b_h, b_w, C1, C2, C3],其中C1, C2, C3分别代表pedestrian(行人)、car(车辆)、motorcycle(机车),三者只有一个可为1,当P_c=0时,则不需要关心y中其他参数,相当于y=[P_c,?,?,?,?,?,?,?]

3.Loss函数L(y_hat, y)

有上图可知,我们只需考虑P_c=1时的情况,且通常只对边界框坐标应用平方误差或类似方法。
3.2特征点检测
1. 特征点检测
如3.1中输出物体边界框类似,如果我们想提取图片中的特征,比如眼睛,那么我么需要确定双眼四个眼角的坐标(L_1x, L_1y), (L_2x, L_2y), (L_3x, L_3y), (L_4x, L_4y)。再如识别微笑,我们可能需要提取嘴角的特征点,也许是64个点或者更多。那么识别的过程是,将标记好的图像X输入到CNN中,在softmax层将是一个129个元素的向量,其中第一个元素设为face表征输入图片是否为面部,然后128个元素表征了64个特征点的(x,y)值,如下图:

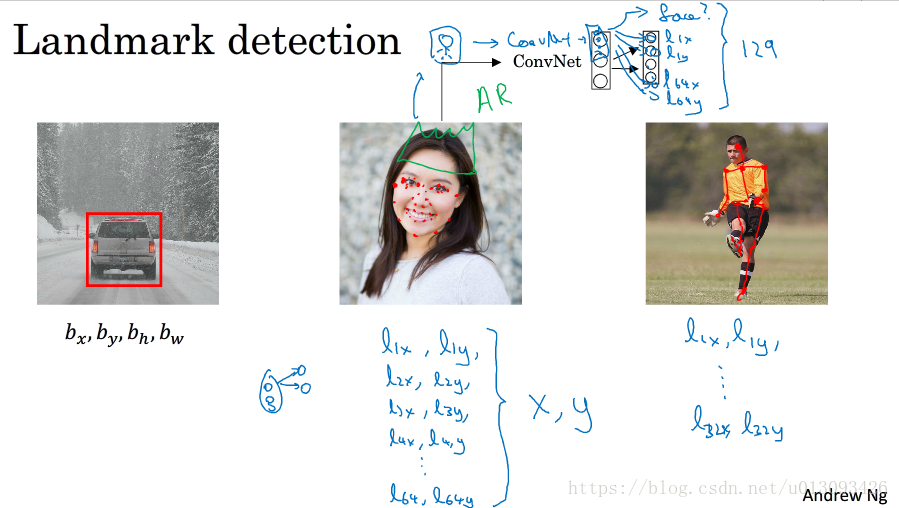
3.3目标检测
1.滑动窗口目标检测
该方法的思路非常直接,即使用某一大小的窗口从输入图像的左上角开始以某一像素大小平移滑动,知道图像的右下角,然后再改变窗口大小重复这一过程,每次讲窗口截取的图像作为CNN的输入进行指定物体的识别,如下图所示。

2.滑动窗口目标检测存在的问题
(1)计算代价过高,剪切出了方块需要卷积神经网络逐个处理
(2)如果增大窗口移动的步频,可以减少网络的计算量,但是颗粒度太大不利于目标检测
3.4卷积的滑动窗口实现
1.将全连接层(FC)转化为卷积层
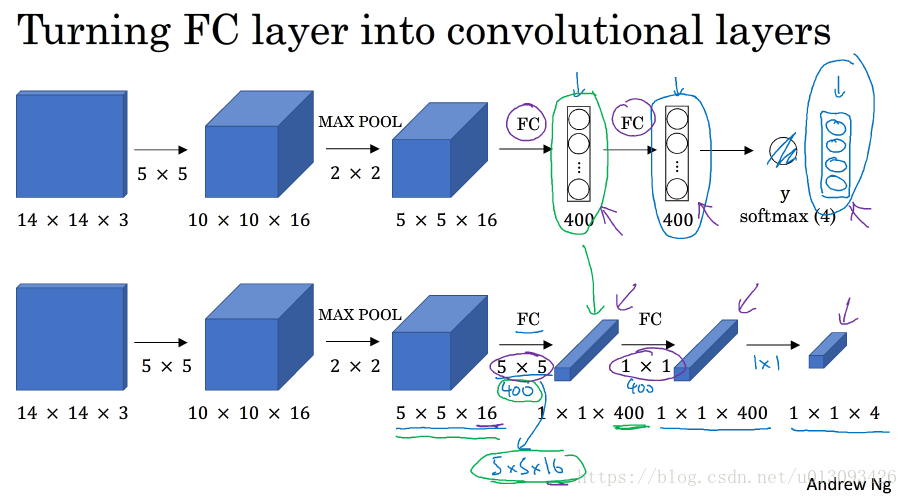
2.滑动窗口的卷积操作
在使用滑动窗口时,选取的各个 窗口元素之间有大量重合的地方,但是如果我们将思路稍加转变,则可以大大减少重复的数据,见下图:
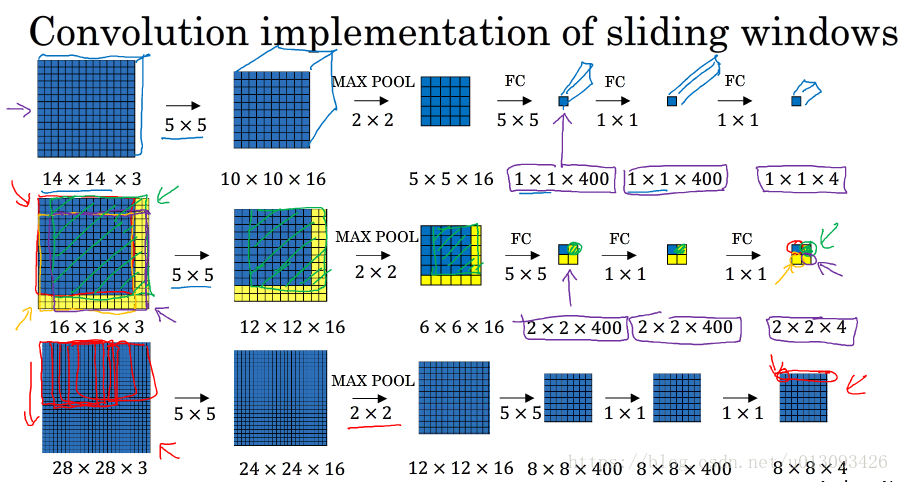
3.缺点:
边界框的位置可能不够准确
3.5bounding box预测
1.输出更精确的边界框
(1)YOLO算法
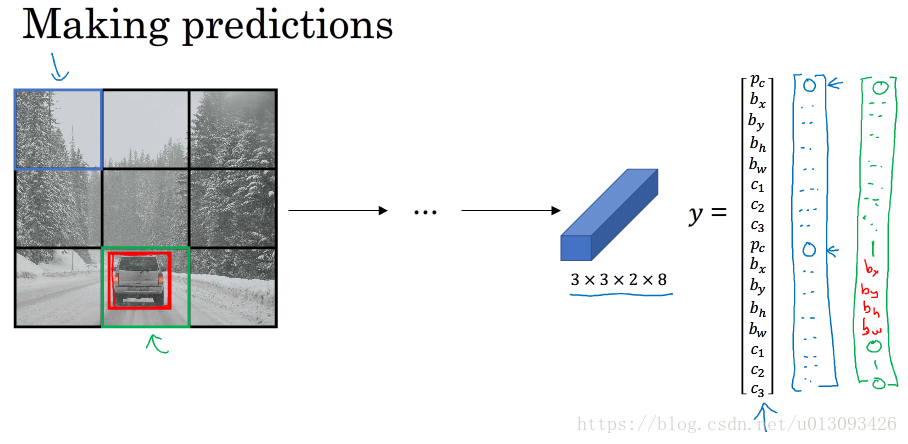
YOLO是一个卷积实现,运算速度非常高,基本可以进行实时识别。在实现过程中,YOLO算法将输入图像分成nxn个小图,然后使用一个卷积网络对这n^2个图像进行识别,最后输出为nxnx8,因为y = [P_c, b_x, b_y, b_w, b_h, C1, C2, C3].T
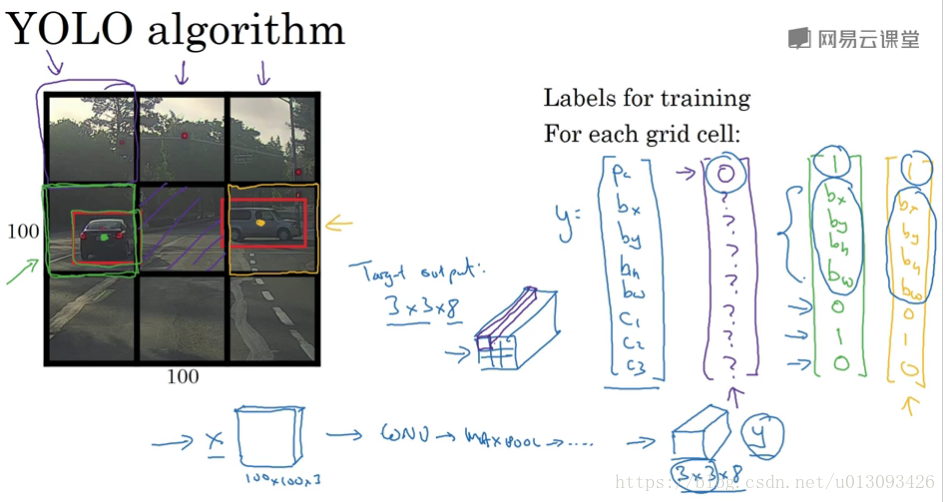
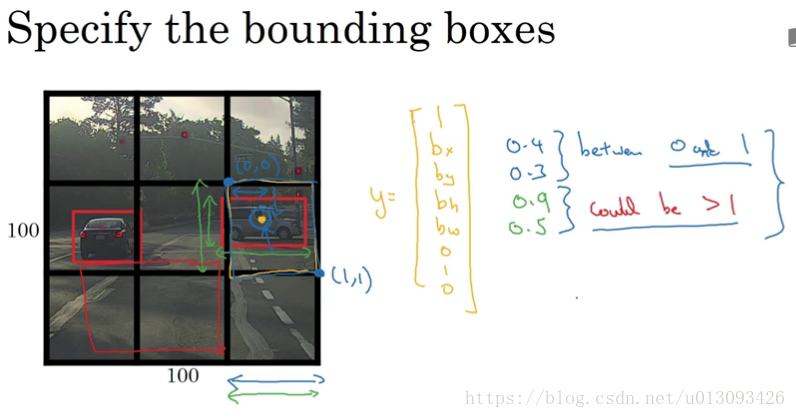
在确定 b_x, b_y, b_w, b_h的原则如下:b_x, b_y的确定以该目标所在单元格为准,其值小于1;b_w, b_h按照与单元格比例,其值可大于1.
3.6交并比(intersection over unit:IOU)
1.作用:评估目标定位算法的优劣, 计算目标实际边框与检测出的边框的交集和并集之比。一般计算机检测出的IoU>=0.5,即可认为识别正确,当然0.5是人为约定的,如果想让结果更严格可以设置为0.6/0.7

3.7非极大值抑制
1.思路:对于同一个目标的不同检测结果,只保留概率最大的而抑制其他检测结果。

3.8Anchor boxes
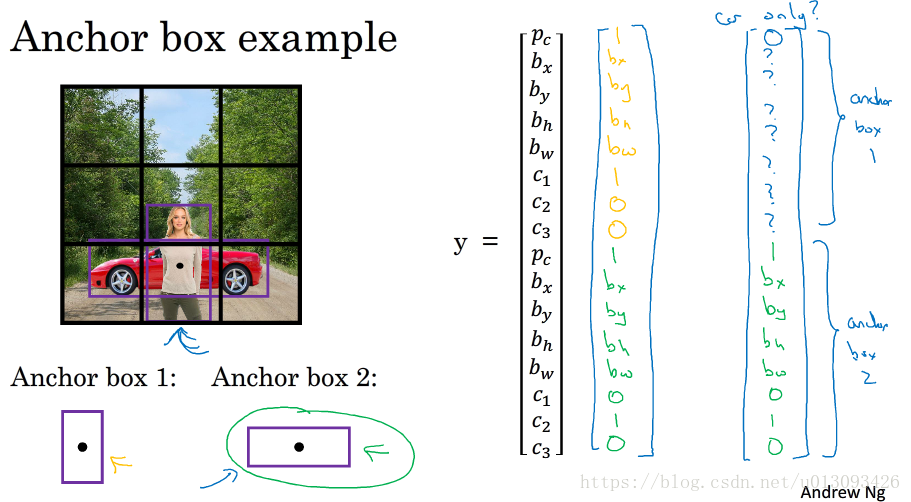
1.作用:在一个格子包含多个物体时(即这些物体的中心点在同一个格子中),可以进行多个目标的检测。

由于人和车的中心在同一个格子中,这时输出y将无法使用y=[P_c, b_x, b_y, b_h, b_w, C1, C2, C3]表示。这时我们要使用anchor boxes算法优化。
2.步骤:
(1)预先定义两个不同形状的anchor1和anchor2(通常情况下可能需要更多,为了简化此处只使用两个)

(2)然后把预测结果和这两个anchor box关联起来,此时输出y的形式为:
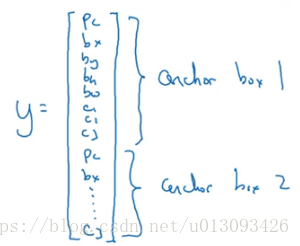
(3)因为行人的形状与anchor1相似,因此使用anchor1的那组数据来编码表示行人的边界框;车子同理
3.特殊情况
(1)由于我们只设置了两个anchor box因此当格子里有三个物体时算法不能很好的处理,
(2)另一种处理不好的情况是,两个物体有相似的anchor 形状
3.9 YOLO算法
1.训练,最终输出的shape由识别的类型数量和anchor box数量共同决定
2.预测,对于P_c=0时的处理,可将其后数据当做噪音处理
3.对输出使用非最大值抑制

3.10RPN网络
1.区域方案:R-CNN详解(带区域的卷积神经网络)
用以解决使用滑动窗口检测时出现的在没有任何对象的区域浪费时间的问题, 该算法尝试选出一些区域,在这些区域中应用卷积网络分类器是有意义的,从而使滑动窗口检测不再对每一个窗口应用,而是只针对选出的区域进行检测。选择的方法是对图像运行“图像分割算法”
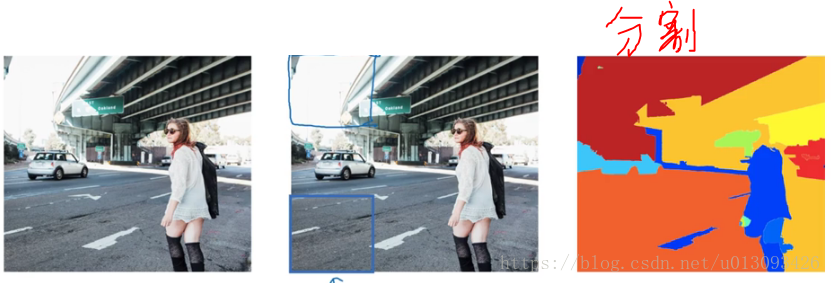
在分割算法处理后的图像中找出一些“色块”,比如图中的蓝色或绿色色块,然后选出这些色块跑一次分类器。

这样需要分类器处理的位置会相对减少很多,可以减少运行时间, 而且还有的好处是,这种算法中我们不局限于窗口选择出的正方形区域,我们还可以检测出高瘦不等的区域,这样更有利于我们识别人物这样的分类。
2.快速 RCNN
R-CNN:输出标签和边界框,在此R-CNN不会直接信任输入的边界框,它会自己输出一个bounding box(b_x, b_y, b_h,b_w)这样的边界框比单纯使用图像分割算法给出的边界框更精确些,但R-CNN的缺点是太慢了
Fast RCNN:用卷积代替滑动窗口,该算法加快的滑动窗口的过程,但是整体的速度还是不理想
Faster RCNN:使用卷积神经网络代替传统的分割法来选择色块,不过相比于YOLO还是稍慢(因为YOLO只需要一步检测,而Faster RCNN要分两个:选定区域,分类识别)
