目录
三、目标检测算法 object detection algorithm
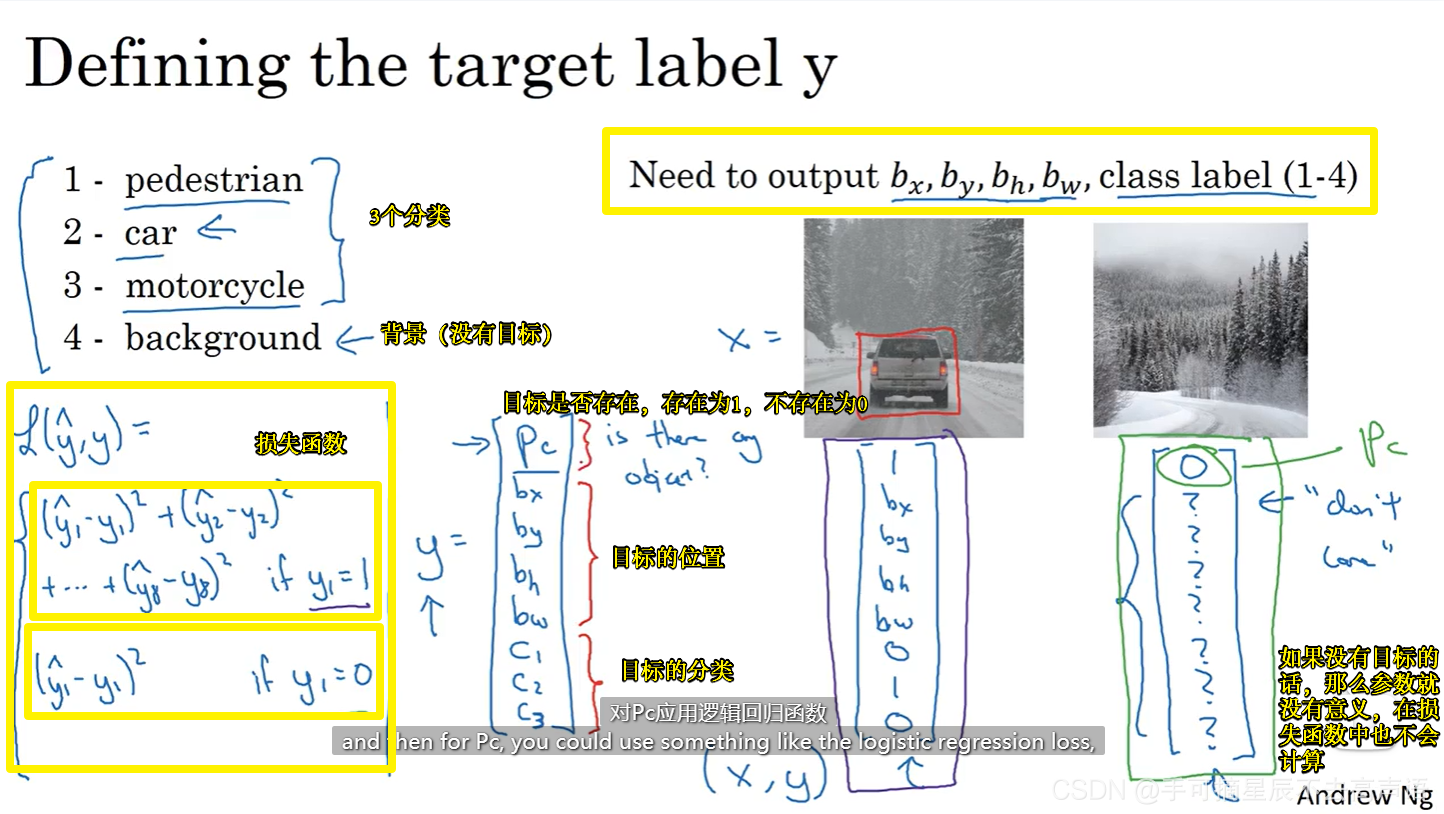
一、目标定位


二、特征点检测(另一种思路)
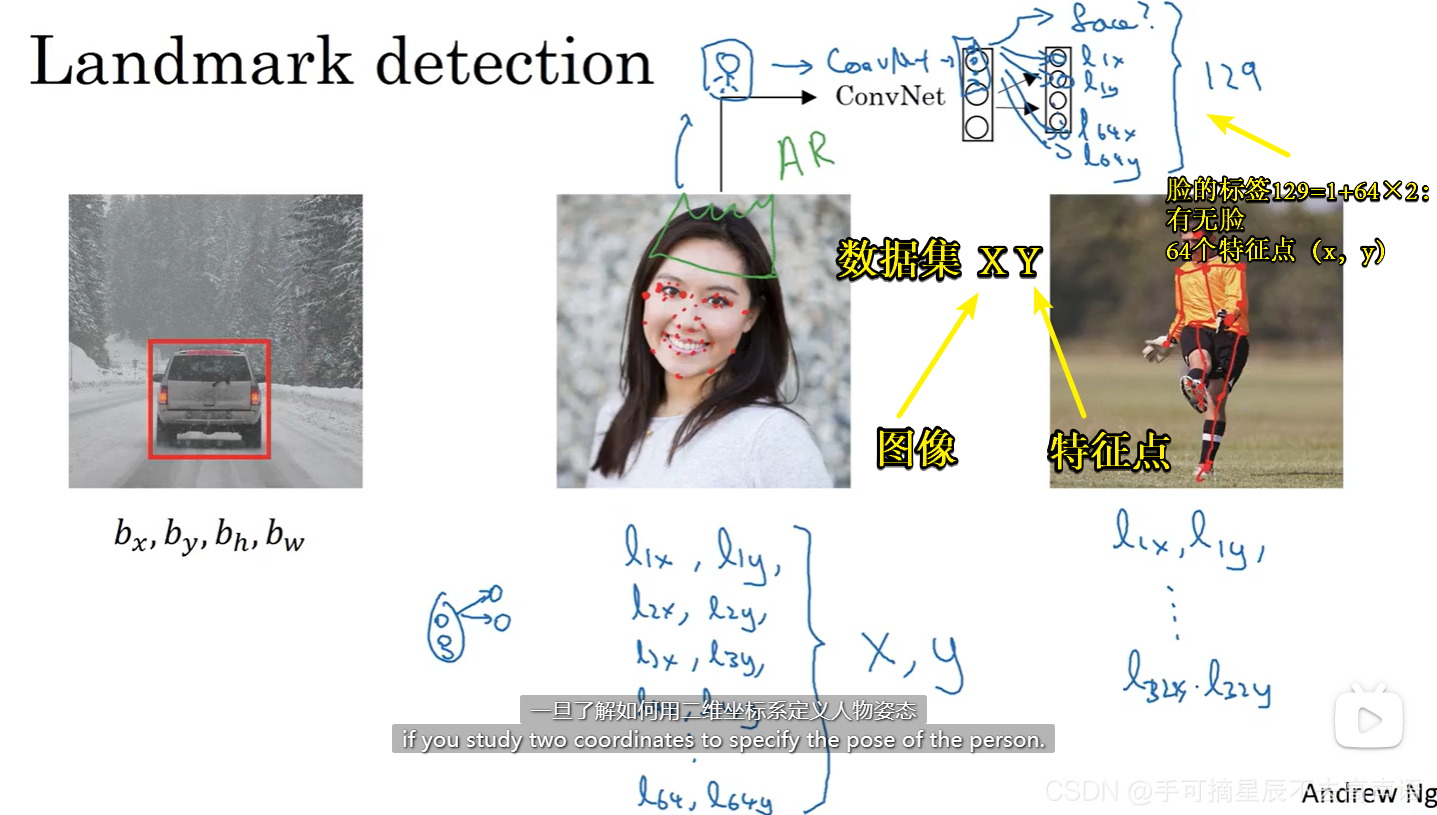
标签特征点的顺序,在所有的样本数据集当中都必须一致
三、目标检测算法 object detection algorithm
滑动窗口的目标检测算法 the sliding windows detection algorithm
标签数据集:照一张照片,然后剪切,剪掉目标以外的部分,使目标居于中心位置,并基本占据整张图片,将标签设置为0/1
然后找一些同样处理过的图片,通过CNN进行训练,训练完毕之后,就可以通过滑动窗口目标检测算法

由于之前已经对卷积神经网络已经训练好了,这个时候取一个窗口,开始在所检测的图片上进行滑动,将图片上的这一窗口的图片传入训练好的CNN当中,预测判断整个窗口里有无目标,然后依次重复操作,直到划过窗口的每一个角落
调整滑动的速度,可以设置固定步幅进行遍历


但是有很明显的缺点:计算成本
在神经网络兴起之前,大家有用的都是比较简单的线性分类器,计算成本比较小,最后的效果也比较好,但是卷积神经网络的加入,倒是运行单个分类任务的成本高很多
四、卷积的滑动窗口实现
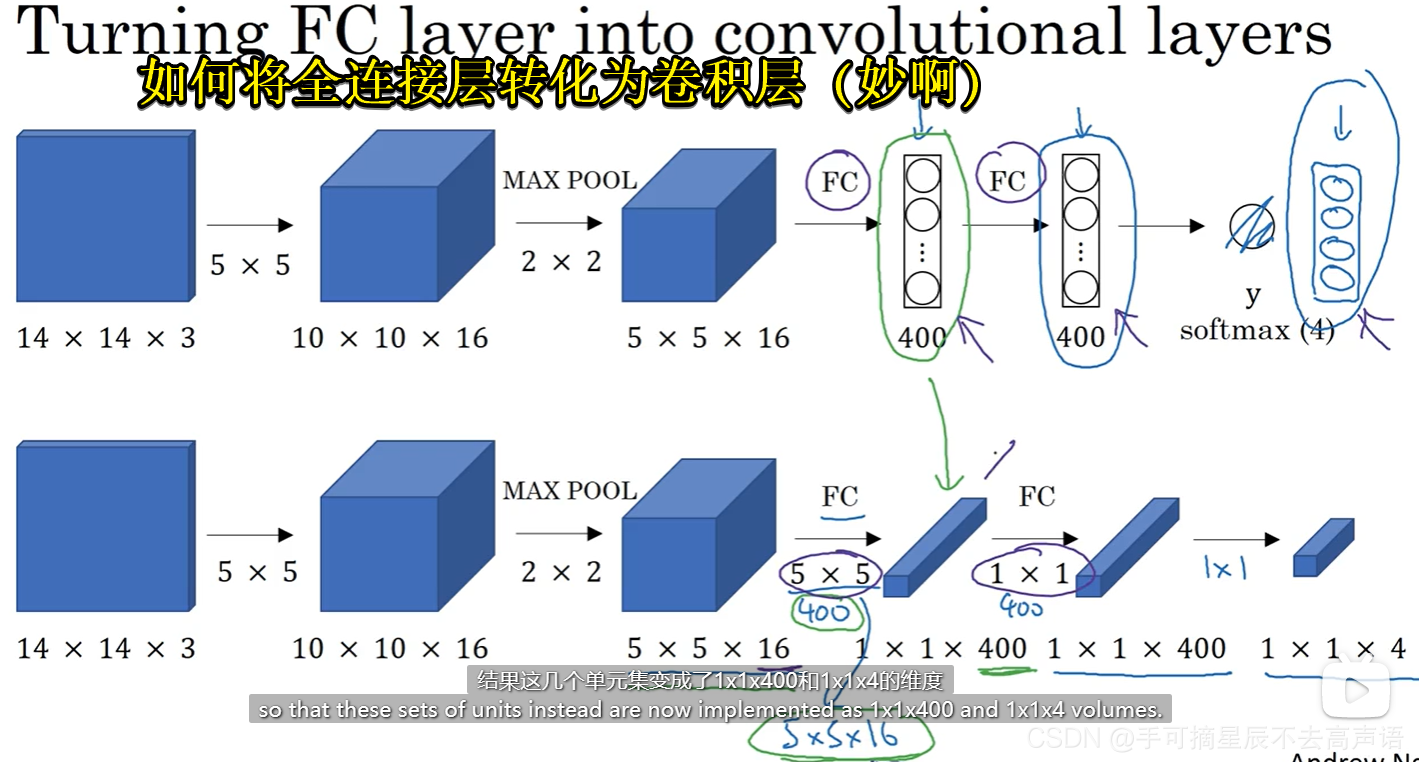


缺点:边界框的位置可能不太精确
五、Bounding Box预测(YOLO算法的精髓)
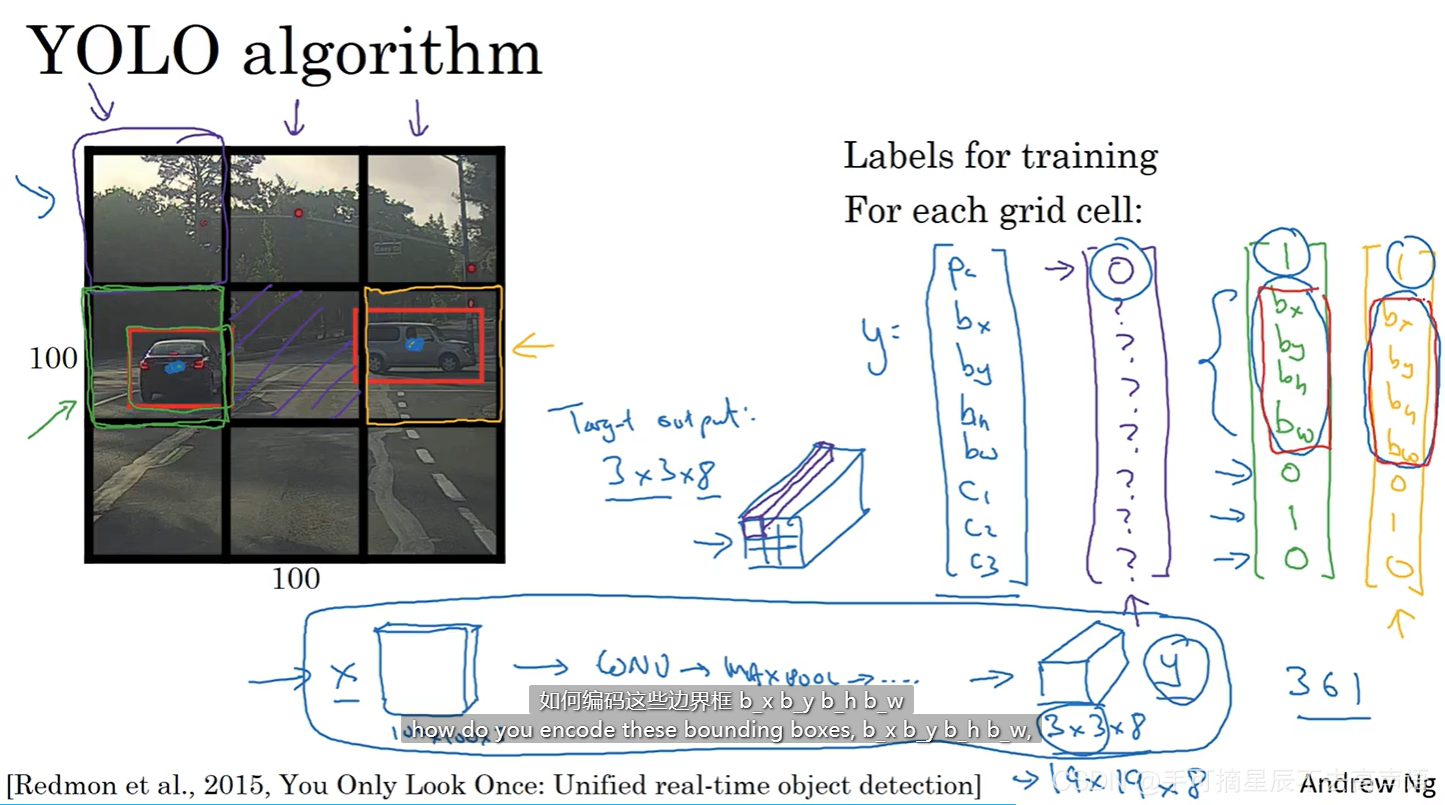
YOLO算法基本原理是,将图片划分为网格(这里以3×3为例),使用图像分类和定位算法,然后将算法应用到9个格子上,那么如何定义训练标签呢?
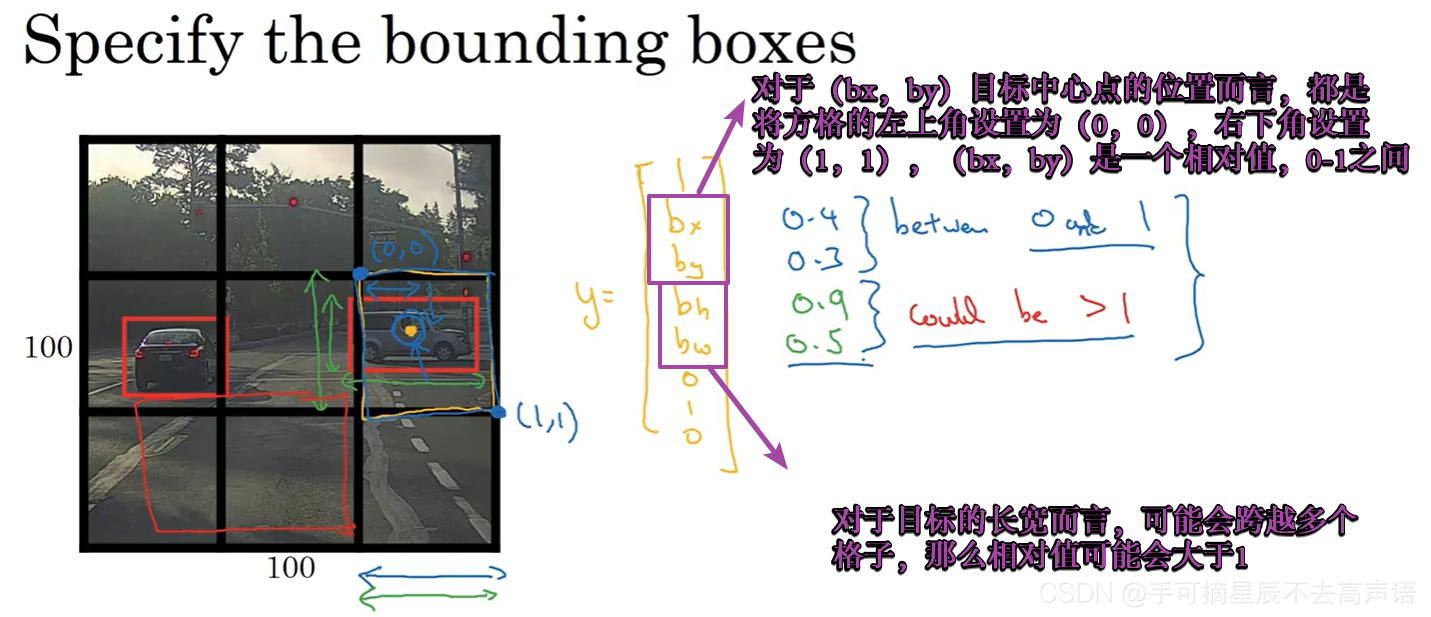
就以第一块中讲的那个例子来说,对于每一个网格指定一个标签y,y是8维向量,那么y=(pc,bx,by,bh,bw,c1,c2,c3),这里一共有9个格子,那么就有9个这样的标签向量。
如果遇到所检测的目标占据了多个格子,那么就找到目标的中心点(目标的中心点就是bx-by),看看这个中心点落在哪一个格子里,那么这个目标就是属于哪一个格子,所以即便一个对象横跨多个方格,最后也只会被分配到9个格子中的一个!所以9个格子中的任意一个格子都会得到8维输出向量,那么对于3×3的格子而言,就会得到目标输出3×3×8
在训练的时候,假设输入100×100×3的图像,那么就将图片通过CNN转化为3×3×8的输出,同3×3×8的标签进行计算损失
那么如果一个格子中有两个目标的中心点怎么办?在实际情况中,我们会将格子划分成19×19(或其他),这样两个中心点分配到一个格子的概率就小得多
对于这个算法而言,可以得到比较精确的框,同时,是对整个图像进行单次卷积,共享了很多数据,降低了计算成本,所以算法的效率很高,运行速度很快,可以达到实时识别

六、交并比 IOU
如何表现算法检测精度的效果好坏呢——交并比

七、非极大值抑制 non-max suppression
你的算法可能对同一个对象做出多次检测,非极大值抑制可以确保,你的算法对每个对象只检测一次,非极大值抑制意味着你只输出概率最大的分类结果

首先找到图中概率最大的一个矩形框,然后将整个矩形框保留下来,找到和整个矩形框交并比的其他几个矩形框,然后将其抑制,这样,一个对象就只会留下一个概率最大的矩形框,然后找到图片中第二高的概率(第二个对象),同上面的做法进行非极大值抑制

最后得到两个框!

八、锚框 Anchor Boxes
到目前为止,每个格子只能检测出一个对象,那么锚框可以做到一个格子检测到多个对象



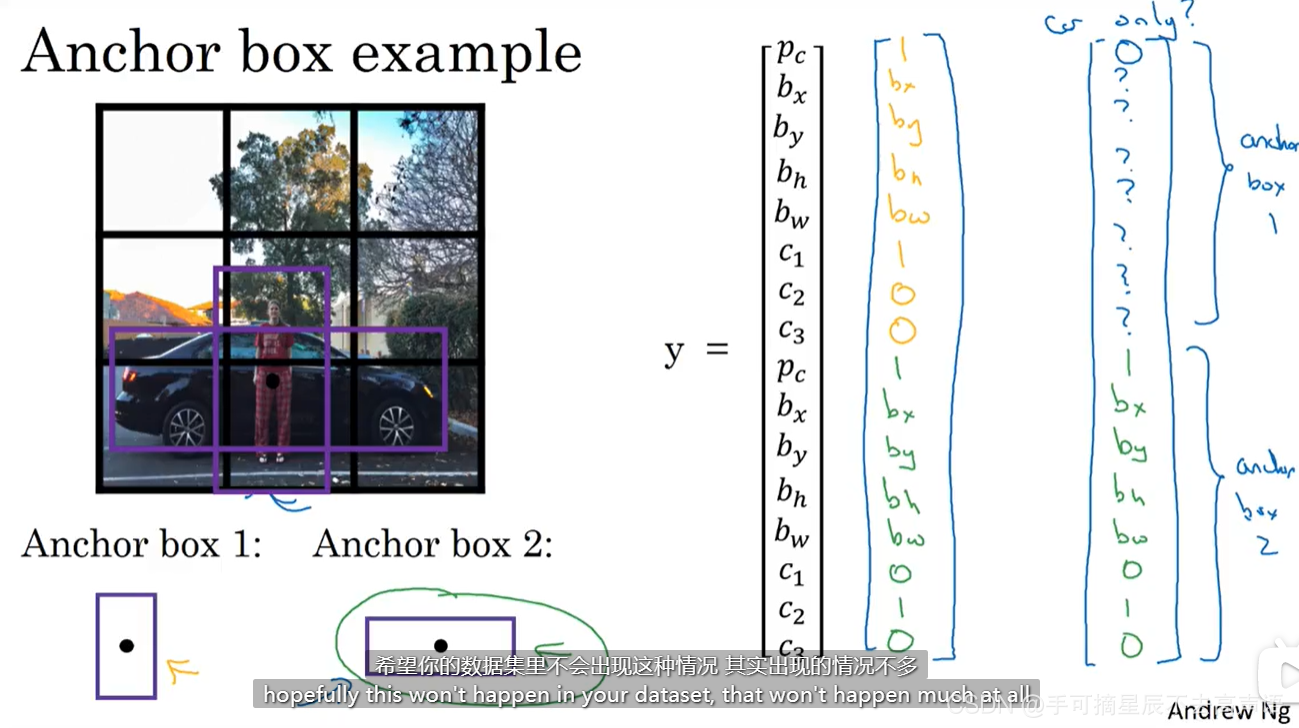
我们一般手动给定5个到10个anchor box形状,覆盖不同的形状
九、YOLO算法




十、候选区域 Region proposals
用图像分割算法,找到可能存在对象的区域,进行窗口检测


大家可以看看这边的作业:
【中文】【吴恩达课后编程作业】Course 4 - 卷积神经网络 - 第三周作业 - 车辆识别
另外我会在实战中用pytorch来操作