Triplet 损失 (Triplet Loss)
要想通过学习神经网络的参数来得到优质的人脸图片编码,方法之一就是定义三元组损失函数然后应用梯度下降。

我们看下这是什么意思,为了应用三元组损失函数,你需要比较成对的图像,比如这个图片,为了学习网络的参数,你需要同时看几幅图片,比如这对图片(编号1和编号2),你想要它们的编码相似,因为这是同一个人。然而假如是这对图片(编号3和编号4),你会想要它们的编码差异大一些,因为这是不同的人。
用三元组损失的术语来说,你要做的通常是看一个 Anchor 图片,你想让Anchor图片和Positive图片(Positive意味着是同一个人)的距离很接近。然而,当Anchor图片与Negative图片(Negative意味着是非同一个人)对比时,你会想让他们的距离离得更远一点。

这就是为什么叫做三元组损失,它代表你通常会同时看三张图片,你需要看Anchor图片、Postive图片,还有Negative图片,我要把Anchor图片、Positive图片和Negative图片简写成 。
把这些写成公式的话,你想要的是网络的参数或者编码能够满足以下特性,也就是说你想要 ,你希望这个数值很小,准确地说,你想让它小于等 和 之间的距离,或者说是它们的范数的平方(即: )。( )当然这就是 ,( )这是 ,你可以把 看作是距离(distance)函数,这也是为什么我们把它命名为 。
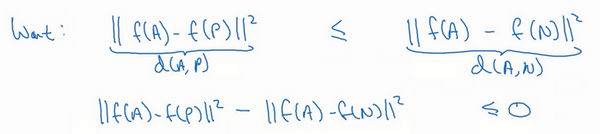
现在如果我把方程右边项移到左边,最终就得到:
现在我要对这个表达式做一些小的改变,有一种情况满足这个表达式,但是没有用处,就是把所有的东西都学成0,如果
总是输出0,即0-0≤0,这就是0减去0还等于0,如果所有图像的
都是一个零向量,那么总能满足这个方程。所以为了确保网络对于所有的编码不会总是输出0,也为了确保它不会把所有的编码都设成互相相等的。另一种方法能让网络得到这种没用的输出,就是如果每个图片的编码和其他图片一样,这种情况,你还是得到0-0。
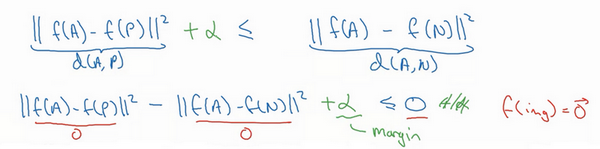
为了阻止网络出现这种情况,我们需要修改这个目标,也就是,这个不能是刚好小于等于0,应该是比0还要小,所以这个应该小于一个 值(即 ),这里的 是另一个超参数,这个就可以阻止网络输出无用的结果。按照惯例,我们习惯写 (即 ),而不是把 写在后面,它也叫做间隔(margin),这个术语你会很熟悉,如果你看过关于支持向量机 (SVM)的文献,没看过也不用担心。我们可以把上面这个方程( )也修改一下,加上这个间隔参数。
举个例子,假如间隔设置成0.2,如果在这个例子中, ,如果 Anchor和 Negative图片的 ,即 只大一点,比如说0.51,条件就不能满足。虽然0.51也是大于0.5的,但还是不够好,我们想要 比 大很多,你会想让这个值( )至少是0.7或者更高,或者为了使这个间隔,或者间距至少达到0.2,你可以把这项调大或者这个调小,这样这个间隔 ,超参数 至少是0.2,在 和 之间至少相差0.2,这就是间隔参数 的作用。它拉大了Anchor和Positive 图片对和Anchor与Negative 图片对之间的差距。取下面的这个方框圈起来的方程式,在下个幻灯片里,我们会更公式化表示,然后定义三元组损失函数。

三元组损失函数的定义基于三张图片,假如三张图片 ,即Anchor样本、Positive样本和Negative样本,其中Positive图片和Anchor图片是同一个人,但是Negative图片和Anchor不是同一个人。
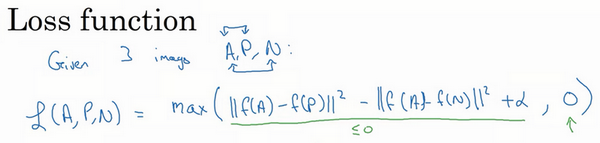
接下来我们定义损失函数,这个例子的损失函数,它的定义基于三元图片组,我先从前一张幻灯片复制过来一些式子,就是 。所以为了定义这个损失函数,我们取这个和0的最大值:
这个 函数的作用就是,只要这个 ,那么损失函数就是0。只要你能使画绿色下划线部分小于等于0,只要你能达到这个目标,那么这个例子的损失就是0。
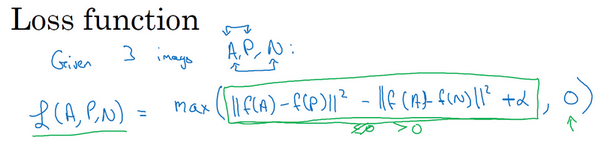
另一方面如果这个 ,然后你取它们的最大值,最终你会得到绿色下划线部分(即 )是最大值,这样你会得到一个正的损失值。通过最小化这个损失函数达到的效果就是使这部分 成为0,或者小于等于0。只要这个损失函数小于等于0,网络不会关心它负值有多大。
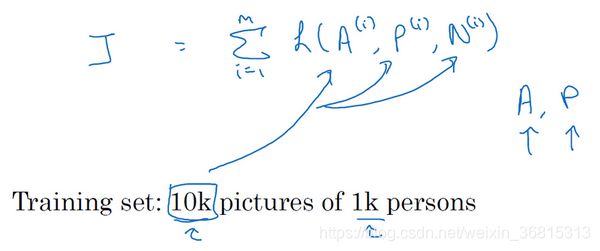
这是一个三元组定义的损失,整个网络的代价函数应该是训练集中这些单个三元组损失的总和。假如你有一个10000个图片的训练集,里面是1000个不同的人的照片,你要做的就是取这10000个图片,然后生成这样的三元组,然后训练你的学习算法,对这种代价函数用梯度下降,这个代价函数就是定义在你数据集里的这样的三元组图片上。
注意,为了定义三元组的数据集你需要成对的 和 ,即同一个人的成对的图片,为了训练你的系统你确实需要一个数据集,里面有同一个人的多个照片。这是为什么在这个例子中,我说假设你有1000个不同的人的10000张照片,也许是这1000个人平均每个人10张照片,组成了你整个数据集。如果你只有每个人一张照片,那么根本没法训练这个系统。当然,训练完这个系统之后,你可以应用到你的一次学习问题上,对于你的人脸识别系统,可能你只有想要识别的某个人的一张照片。但对于训练集,你需要确保有同一个人的多个图片,至少是你训练集里的一部分人,这样就有成对的Anchor和Positive图片了。

现在我们来看,你如何选择这些三元组来形成训练集。一个问题是如果你从训练集中,随机地选择 和 ,遵守 和 是同一个人,而 和 是不同的人这一原则。有个问题就是,如果随机的选择它们,那么这个约束条件( )很容易达到,因为随机选择的图片, 和 比 和 差别很大的概率很大。我希望你还记得这个符号 就是前几个幻灯片里写的 , 就是 , 即 。但是如果 和 是随机选择的不同的人,有很大的可能性 会比左边这项 大,而且差距远大于 ,这样网络并不能从中学到什么。
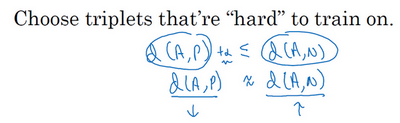
所以为了构建一个数据集,你要做的就是尽可能选择难训练的三元组 和 。具体而言,你想要所有的三元组都满足这个条件( ),难训练的三元组就是,你的 和 的选择使得 很接近 ,即 ,这样你的学习算法会竭尽全力使右边这个式子变大( ),或者使左边这个式子( )变小,这样左右两边至少有一个 的间隔。并且选择这样的三元组还可以增加你的学习算法的计算效率,如果随机的选择这些三元组,其中有太多会很简单,梯度算法不会有什么效果,因为网络总是很轻松就能得到正确的结果,只有选择难的三元组梯度下降法才能发挥作用,使得这两边离得尽可能远。
如果你对此感兴趣的话,这篇论文中有更多细节,作者是Florian Schroff, Dmitry Kalenichenko, James Philbin,他们建立了这个叫做FaceNet的系统,我视频里许多的观点都是来自于他们的工作。
• Florian Schroff, Dmitry Kalenichenko, James Philbin (2015). FaceNet: A Unified Embedding forFace Recognition and Clustering
顺便说一下,这有一个有趣的事实,关于在深度学习领域,算法是如何命名的。如果你研究一个特定的领域,假如说“某某”领域,通常会将系统命名为“某某”网络或者深度“某某”,我们一直讨论人脸识别,所以这篇论文叫做FaceNet(人脸网络),上个视频里你看到过DeepFace(深度人脸)。“某某”网络或者深度“某某”,是深度学习领域流行的命名算法的方式,你可以看一下这篇论文,如果你想要了解更多的关于通过选择最有用的三元组训练来加速算法的细节,这是一个很棒的论文。
总结一下,训练这个三元组损失你需要取你的训练集,然后把它做成很多三元组,这就是一个三元组(编号1),有一个Anchor图片和Positive图片,这两个(Anchor和Positive)是同一个人,还有一张另一个人的Negative图片。这是另一组(编号2),其中Anchor和Positive图片是同一个人,但是Anchor和Negative不是同一个人,等等。

定义了这些包括 和 图片的数据集之后,你还需要做的就是用梯度下降最小化我们之前定义的代价函数 ,这样做的效果就是反向传播到网络中的所有参数来学习到一种编码,使得如果两个图片是同一个人,那么它们的 就会很小,如果两个图片不是同一个人,它们的 就会很大。
这就是三元组损失,并且如何用它来训练网络输出一个好的编码用于人脸识别。现在的人脸识别系统,尤其是大规模的商业人脸识别系统都是在很大的数据集上训练,超过百万图片的数据集并不罕见,一些公司用千万级的图片,还有一些用上亿的图片来训练这些系统。这些是很大的数据集,即使按照现在的标准,这些数据集并不容易获得。幸运的是,一些公司已经训练了这些大型的网络并且上传了模型参数。所以相比于从头训练这些网络,在这一领域,由于这些数据集太大,这一领域的一个实用操作就是下载别人的预训练模型,而不是一切都要从头开始。但是即使你下载了别人的预训练模型,我认为了解怎么训练这些算法也是有用的,以防针对一些应用你需要从头实现这些想法。
这就是三元组损失,下个视频中,我会给你展示Siamese网络的一些其他变体,以及如何训练这些网络,让我们进入下个视频吧。
课程板书





